一、网络爬虫介绍
网络爬虫是一个自动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成。
例如,百度、google搜索某关键字时,就是爬取整个互联网上的相关资源,给呈现出来。
实际爬虫四个步骤:
1、明确目标
2、爬(将所有网站的内容全部爬下来) -》分析其中一个网页源码,对html标签定位
3、取(去掉对我们没用处的数据) -》正则表达式
4、处理数据
urllib库与requests库
在使用python爬虫时,需要模拟发起网络请求,主要用到的库有requests库和python内置的urllib库,一般建议使用requests,它是对urllib的再次封装,它们使用的主要区别:
requests可以直接构建常用的get和post请求并发起,urllib一般要先构建get或者post请求,然后再发起请求。
二、urllib与urllib2
1、urllib、urllib2和 urllib3的区别
使用python3经常会出现关于urllib2的一些问题,urllib2是python2里面的【需要安装了python 2版本的机器上用】,这里代码出错往往是因为引用了urllib2。
urllib 侧重于 url 基本的请求构造,urllib2侧重于 http 协议请求的处理,而 urllib3是服务于升级的http 1.1标准,且拥有高效 http连接池管理及 http 代理服务的功能库,从 urllib 到 urllib2和 urllib3是顺应互联应用升级浪潮的,这股浪潮从通用的网络连接服务到互联网网络的头部应用:支持长连接的 http 访问,网络访问不断的便捷化。
python2中提供了urllib和urllib2两个模块
python3中也有urllib和urllib3两个模块,其中urllib几乎是python2中urllib和urllib2两个模块的集合,所以我们最常用的是urllib模块,而urllib3作为一个拓展模块使用。
2、urllib和urllib2之间PK
在python中,urllib和urllib2不可相互替代的。 整体来说,urllib2是urllib的增强,但是urllib中有urllib2中所没有的函数。
(1) urllib2可以用urllib2.openurl中设置Request参数,来修改Header头。如果你访问一个网站,想更改User Agent(可以伪装你的浏览器),你就要用urllib2。urllib2在python3中被修改为urllib.request。
(2)urllib支持设置编码的函数,urllib.urlencode(用来GET查询字符串的产生),在模拟登陆的时候,经常要post编码之后的参数,所以要想不使用第三方库完成模拟登录,你就需要使用urllib。
urllib一般和urllib2一起搭配使用
(3)编码工作使用urllib的urlencode()函数,帮我们将key:value这样的键值对转换成‘key=value’这样的字符串,解码工作可以使用urllib的unquote()


#python3 from urllib.parse import urlencode,unquote dic ={ 'derek': '编码'} m = urlencode(dic) #编码,其中dic必须为字典 print(m) #输出:derek=%E7%BC%96%E7%A0%81 print(unquote(m)) #解码,输出:derek=编码
3、在python2中使用urllib2爬百度首页
# 在python2.7中执行 import urllib2 response = urllib2.urlopen("http://www.baidu.com") html = response.read() print(html) ----------------或者------------------ # 在python2.7中执行 import urllib2 req = urllib2.Request("http://www.baidu.com") response=urllib2.urlopen(req) html = response.read() print(html)
4、反爬虫
小程序去爬取可能会被拦截,需要伪装成合法的请求者。eg:浏览器去请求百度是ok的
给请求加上User-Agent。User-Agent是爬虫与反爬虫的第一步。【使用代理IP,这是爬虫/反爬虫的第二大招,通常也是最好用的。】
import urllib2 url = "http://www.baidu.com" # 伪装成浏览器去请求,user-agent可以在网上搜 user_agent = "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) " "Chrome/39.0.2171.71 Safari/537.36" headers = {'User_Agent': user_agent} req = urllib2.Request(url, headers=headers) response = urllib2.urlopen(req) html = response.read() print(html)
Request总共三个参数,除了必须要有url参数,还有下面两个:
-
data(默认空):是伴随 url 提交的数据(比如要post的数据),同时 HTTP 请求将从 "GET"方式 改为 "POST"方式。
-
headers(默认空):是一个字典,包含了需要发送的HTTP报头的键值对
response的常用方法
# 服务器返回的类文件对象支持python文件对象的操作方法 # read()方法就是读取文件里的全部内容,返回字符串 html = response.read() # 返回HTTP的响应吗,成功返回200,4服务器页面出错,5服务器问题 print response.getcode() #200 # 返回数据的实际url,防止重定向 print response.geturl() #https://www.baidu.com/ # 返回服务器响应的HTTP报头 print response.info()
5、随机选择一个Use-Agent
为了防止封IP,先生成一个user-agent列表,然后从中随机选择一个
爬虫系列文章:https://www.cnblogs.com/derek1184405959/category/1163820.html
6、发送post请求
7、ProxyHandler处理器(代理设置)
使用代理IP,这是爬虫/反爬虫的第二大招,通常也是最好用的。
很多网站会检测某一段时间某个IP的访问次数(通过流量统计,系统日志等),如果访问次数多的不像正常人,它会禁止这个IP的访问。
所以我们可以设置一些代理服务器,每隔一段时间换一个代理,就算IP被禁止,依然可以换个IP继续爬取。
urllib2中通过ProxyHandler来设置使用代理服务器,使用自定义opener来使用代理:
免费代理网站:http://www.xicidaili.com/; https://www.kuaidaili.com/free/inha/
但是,这些免费开放代理一般会有很多人都在使用,而且代理有寿命短,速度慢,匿名度不高,HTTP/HTTPS支持不稳定等缺点(免费没好货),所以,专业爬虫工程师会使用高品质的私密代理
私密代理
(代理服务器都有用户名和密码)必须先授权才能用
三、python与request
使用requests可以模拟浏览器的请求,比起之前用到的urllib,requests模块的api更加便捷(本质就是封装了urllib3)
注意:requests库发送请求将网页内容下载下来以后,并不会执行js代码,这需要我们自己分析目标站点然后发起新的request请求
四、爬虫框架Scrapy
-
新建项目 :新建一个新的爬虫项目
-
明确目标 (编写items.py):明确你想要抓取的目标
-
制作爬虫 (spiders/xxspider.py):制作爬虫开始爬取网页
-
存储内容 (pipelines.py):设计管道存储爬取内容
详见 scrapy中文网 【必读】
scrapy安装
安装scrapy过程中出现错误,指向了twisted(用python语言写的事件驱动的网络框架),那么需要先安装twisted【通过下载whl文件安装】
安装scrapy 强烈建议用 anaconda去安装,然后使用anaconda安装目录下的python版本。
若安装不在C盘,则执行scrapy时 用anaconda powershell prompt去执行。
执行爬虫时也可以定位到程序目录去执行。

scrapy没有界面,只能使用scrapy命令行工具。命令不多,而且常用的就三四个:
scrapy startproject(创建项目)、
scrapy crawl XX(基于项目 运行XX蜘蛛) 创建了项目整个框架、
scrapy runspider yy.py(基于文件 运行yy蜘蛛)不用创建项目,直接一个.py写爬出就可以执行、
scrapy shell http://www.scrapyd.cn(主要是调试用,调试网址为http://www.scrapyd.cn的网站),
scrapy命令分为:全局命令【在哪都能用】和项目命令【只能依赖你的项目】
全局命令有:startproject、shell、setting、genspider(根据模板直接生成爬虫.py文件)、runspider、fetch等
项目命令有:crawl(运行爬虫)、list(列出当前项目下spiders文件夹下面多少个.py爬虫,爬虫文件中定义的name相同的算一个)
创建一个scrapy项目
在命令行输入一下命令即可创建
scrapy startproject mingyan
mingyan是我们创建的蜘蛛名字,后面我们运行的时候用得到。 则自动创建了以下目录
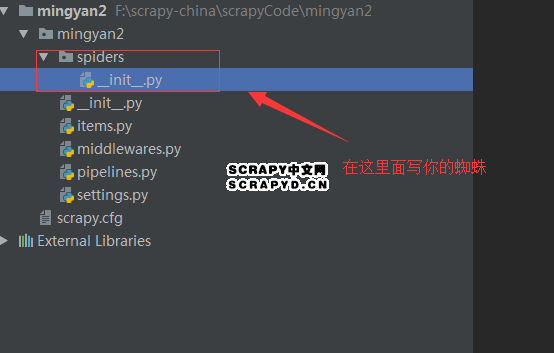
那我们该在哪里写我们的蜘蛛呢?here,在spiders目录下面,我们就来创造一只scrapy蜘蛛(mingyanSpider.py)
我们要爬取哪个网站、爬取这个网站的神马数据,统统在这个文件里面编写,其实挺简单,就是一个.py文件而已,别把scrapy想得太复杂!
mingyanSpider.py 需要做以下几件事:
A:首先我们需要创建一个类,并继承scrapy的一个子类:scrapy.Spider 或者是其他蜘蛛类型,后面会说到,除了Spider还有很多牛X的蜘蛛类型;
B:然后定义一个蜘蛛名,name=“” 后面我们运行的话需要用到;
C:定义我们需要爬取的网址,没有网址蜘蛛肿么爬,所以这是必须滴;
D:继承scrapy的一个方法:start_requests(self),这个方法的作用就是通过上面定义的链接去爬取页面,简单理解就是下载页面。
#!/usr/bin/env python # encoding: utf-8 # file: mingyan_spider.py import scrapy class mingyan(scrapy.Spider): #需要继承scrapy.Spider类 name = "mingyan2" # 爬虫名称 def start_requests(self): # 由此方法通过下面链接爬取页面 # 定义爬取的链接 urls = [ 'http://lab.scrapyd.cn/page/1/', 'http://lab.scrapyd.cn/page/2/', ] for url in urls: yield scrapy.Request(url=url,callback=self.parse) #爬取到的页面如何处理?提交给parse方法处理 def parse(self,response): ''' start_requests已经爬取到页面,那如何提取我们想要的内容呢?那就可以在这个方法里面定义。 这里的话,并木有定义,只是简单的把页面做了一个保存,并没有涉及提取我们想要的数据,后面会慢慢说到 也就是用xpath、正则、或是css进行相应提取,这个例子就是让你看看scrapy运行的流程: 1、定义链接; 2、通过链接爬取(下载)页面; 3、定义规则,然后提取数据; 就是这么个流程,似不似很简单呀? :param response: :return: ''' page = response.url.split("/")[-2] # 根据上面的链接提取分页,如:/page/1/,提取到的就是:1 filename = 'mingyan-%s.html' % page # 拼接文件名,如果是第一页,最终文件名便是:mingyan-1.html with open(filename, 'wb') as f: # python文件操作,不多说了; f.write(response.body) # 刚才下载的页面去哪里了?response.body就代表了刚才下载的页面! self.log('保存文件: %s' % filename) # 打个日志
运行
scrapy crawl mingyan2
输入以上命令便可以运行蜘蛛了!这里要重点提醒一下,我们一定要进入:mingyan2 这个目录,也就是我们创建的蜘蛛项目目录,以上命令才有效!还有 crawl 后面跟的是你类里面定义的蜘蛛名,也就是:name,并不是项目名、也不是类名,这些细节希注意!
【注:spiders目录下 可以建立多个xxxspider.py,只要定义不同的name就好,里面的class类名可以和文件名不一致。执行时:scrapy crawl name】
数据提取工具
scrapy真正的强大是表现在它提取数据的能力上,scrapy提取数据的几种方式:CSS、XPATH、RE(正则)
那开始之前,我们还需要磨把刀,神马刀呢?也就是:验证scrapy到底有木有提取到数据的工具,其实说白了就是scrapy调试工具【可以在命令行中调试 或者pycharm中调试】,如果木有它你根本不知道你写的规则到底有木有提取到数据,所以这个工具是个:刚需!其实也很简单,就是在命令行输入下面一行代码而已:
scrapy shell http://lab.scrapyd.cn
scrapy shell 固定格式,后面的话跟的是你要调试的页面。
就这样一个格式,其实这段代码就是一个下载的过程,一执行这么一段代码scrapy就立马把我们相应链接的相应页面给拿到了,那接下来就可以任你处置了
比如我们想提取 http://lab.scrapyd.cn 的 title,我们可以在 In[1]: 后面输入:response.css('title') ,然后回车, 立马就得到如下结果:
>>> response.css('title')
[<Selector xpath='descendant-or-self::title' data='<title>爬虫实验室 - S
CRAPY中文网提供</title>'>]
似不似很直观的验证了你提取的数据对不对?如果正确了,我们再把上面的代码放到我们蜘蛛里面,那这样就会正确的得到你想要的数据,而不会出现意外了,这就是scrapy调试工具的应用!
CSS选择器使用
上面使用 response.css('标签名') 它就是scrapy的固定格式。
1、函数使用
那你会发现,我们使用这个命令提取的一个Selector的列表,并不是我们想要的数据;那我们再使用scrapy给我们准备的一些函数来进一步提取,那我们改变一下上面的写法,输入:
>>> response.css('title').extract()
['<title>爬虫实验室 - SCRAPY中文网提供</title>']
extract() 这么一个函数你就提取到了我们标签的一个列表,那如果不要列表[ ] ,只要title这个标签,可以如下操作
>>> response.css('title').extract()[0]
'<title>爬虫实验室 - SCRAPY中文网提供</title>'
scrapy也给我提供了另外一个函数,可以这样来写,一样的效果:
>>> response.css('title').extract_first()
'<title>爬虫实验室 - SCRAPY中文网提供</title>'
extract_first()就代表提取第一个元素,和我们的:[0],一样的效果
但是你会发现,肿么多了一个title标签,这并不是你需要的,那要肿么办呢,我们可以继续改变一下以上的输入:
>>> response.css('title::text').extract_first()
'爬虫实验室 - SCRAPY中文网提供'
我们在title后面加上了 ::text ,这代表提取标签里面的数据,
2、实战:获取第一个的名言、作者、标签,保存到txt文本
#!/usr/bin/env python # encoding: utf-8 # file: item_spider.py # 获取第一个名言、作者、标签 import scrapy class itemSpider(scrapy.Spider): name = 'itemSpider' start_urls = ['http://lab.scrapyd.cn'] def parse(self, response): # 每一段名言都被一个 <div class="quote post">……</div> 包裹,取第一个名言 mingyan = response.css('div.quote')[0] # 提取名言 text = mingyan.css('.text::text').extract_first() # 提取作者 author =mingyan.css('.author::text').extract_first() # 提取标签,有多个 tags = mingyan.css('.tags .tag::text').extract() tags = ','.join(tags) #数组转化为字符串 filename = '%s-语录.txt' %author f =open(filename,"a+") #追加写入 f.write(text) f.write(' ') f.write('标签:'+tags) f.close()
获取多条数据、获取多页数据......
小结
爬虫就是替人重复的执行一系列从网络上保存想要的数据的过程,它要完成这几个动作:打开页面、提取数据、保存数据。这样一类比,那scrapy就灰常简单了,我们只要搞清楚三个问题:
1、scrapy如何打开页面?
2、scrapy如何提取数据?
3、scrapy如何保存数据?
1、scrapy打开网页,其实就是给互联网发送一个请求、返回请求的过程。
因此引出了scrapy spiders的第一个必须的常量: start_urls
有两种写法:一种是作为类的常量,一种是作为start_requests(self)方法的常量
''' def start_requests(self): # 由此方法通过下面链接爬取页面 # 定义爬取的链接 urls = [ 'http://lab.scrapyd.cn/page/1/', 'http://lab.scrapyd.cn/page/2/', ] for url in urls: yield scrapy.Request(url=url,callback=self.parse) #爬取到的页面如何处理?提交给parse方法处理 ''' # [初始链接的简写]这种写法,无需定义start_requests方法,此时下面的方法名一定要是parse start_urls = [ 'http://lab.scrapyd.cn/page/1/', 'http://lab.scrapyd.cn/page/2/',]
如果URL是定义在start_request(self)这个方法里面,那我们就要使用: yield scrapy.Request 方法发送请求。
这样写的一个麻烦之处就是我们需要处理我们的返回,也就是我们还需要写一个callback方法来处理response;因此大多数我们都是把URL作为类的常量,然后再加上另外一个方法:parse(response)
使用这个方法来发送请求,可以看到里面有个参数已经是:response(返回),也就是说这个方自动化的完成了:request(请求页面)-response(返回页面)的过程,我们就不必要再写函数接受返回,所以这样就比较方便了!
2、scrapy提取数据
比如获取:http://lab.scrapy.cn 这个页面的标题?或是这个页面的某个段文字?还是类比,人类如何做的呢?肯定是用眼睛查找!同理scrapy也有眼睛,分别是:css选择器、xpath选择器、正则,这三双眼睛实现的功能都一样
和scrapy相关的函数就这么三个而已:response.css("css表达式")、extract()、extract_first()。
2.1 CSS提取
- 按标签属性值的提取
常见的链接和图片的地址提取: 提取属性我们是用:“标签名::attr(属性名)”,比如我们要提取url表达式就是:a::attr(href),要提取图片地址的表达式就是:img::attr(src)……以此类推
有时需要限定一下我们URL的范围,最好的方法就是找到我们要提取目标最近的class或是id,eg:
response.css(".page-navigator a::attr(href)").extract()
class选择器用. id选择器用#
- 按标签内容提取
例如,<p>scrapy中文网</p> 获取标签内容,用到了scrapy给我提供的这么一个方法:“::text”
response.css("p::text").extract()
标签是惟一的话(eg title),就不用去做限制。
如果一个标签还有子标签的时候,获取所有text 可以用* ,提取出来是一个列表
response.css(".post-content *::text").extract()
2.2 xpath提取
- xpath 属性提取
XPath 使用路径表达式在 XML 文档中选取节点。节点是通过沿着路径或者 step 来选取的。 下面列出了最有用的路径表达式:
| 表达式 | 描述 |
|---|---|
| nodename | 选取此节点的所有子节点。 |
| / | 从根节点选取。 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。 |
| . | 选取当前节点。 |
| .. | 选取当前节点的父节点。 |
| @ | 选取属性。 |
可以看到上面选取属性用的是:@符号,到了这么一个函数:response.xpath("表达式")
response.xpath("//@href").extract()
和css选择一样我们需要加以限制,如何限制呢?我们可以看到分页href是在一个<ol></ol>标签里面,那我们就可以这样来写:
response.xpath("//ol//@href").extract()
这个表达式表示:ol标签下所有的href属性值。但是假如有多个ol标签,则还可以对标签加限制:标签[@属性名='属性值']
//ol[@class='page-navigator']//@href
是id选择器则用@id=
- 提取标签里面的内容,表达式: //text()
response.xpath("//title//text()").extract()
//title是限定你要提取的范围
再比如,获取class=tags-list的ul里面的a标签的内容 //ul[@class='tags-list']//a//text()
- 包含HTML标签的所有文字内容提取:string()
用//text()提取出来的是一个列表,但有时希望提取出来是一整段文字,就可以用string()
response.xpath("string(//div[@class='post-content'])").extract()
python爬虫学习资源
https://blog.csdn.net/finn_wft/article/details/80881946
https://www.jianshu.com/p/169b62a8a269
1、去哪网
报错:ERROR: Loading "scrapy.core.downloader.handlers.http.HTTPDownloadHandler" for scheme "https" 和ModuleNotFoundError: No module named 'win32api'
问题:需要安装pywin32