一、插入数据
1、插入数据返回当前主键ID
当我们插入一条数据的时候,我们很多时候都想立刻获取当前插入的主键值返回以做它用。我们通常的做法有如下几种:
1. 先 select max(id) +1 ,然后将+1后的值作为主键插入数据库;
2. 使用特定数据库的 auto_increment 特性,在插入数据完成后,使用 select max(id) 获取主键值;
但要获取此ID,最简单的方法就是在查询之后select @@identity。
sql代码:
INSERT INTO table_name (.....) VALUES(......) SELECT @@IDENTITY AS ID; Eg: (long=int64) long result=0; object obj = DbHelperSQL.GetSingle(strSql.ToString(), parameters); if (obj == null) { Result= 0; } else { Result= Convert.ToInt64(obj); }
2、批量插入数据
--循环插入大量数据
首先创建一个数据表



SET STATISTICS TIME ON --查看服务器资源使用情况。打开CUP统计报表 DECLARE @Index INT = 1 --声明变量 DECLARE @Timer DATETIME = GETDATE() WHILE @Index <= 100000 BEGIN INSERT [Test](Name, CreateTime, Remark) VALUES('hy_' + CAST(@Index AS CHAR(6)),DATEADD (SS,-@Index,GETDATE()), 'system'); SET @Index = @Index + 1; END --SELECT DATEDIFF(MS, @Timer, GETDATE()) AS [执行时间(毫秒)] SET STATISTICS TIME OFF;
3、存在则更新,不存在则增加
采用IF Not EXISTS
USE ManagementDB; DECLARE @parentID NVARCHAR(100) DECLARE @resourceCode INT = 0 DECLARE @createtime datetime --1、加二级菜单:訂單查詢 SELECT @parentID=ResourceID FROM Resource WHERE ResourceSite ='Ho/Order' ORDER BY CreateTime PRINT @parentID SET @resourceCode = ( SELECT MAX(ResourceCode) + 1 FROM Resource WHERE ResourceCode BETWEEN 1000 AND 1999 ) PRINT @resourceCode IF Not EXISTS(select * from Resource where ResourceSite='Ho/Order/SearchOrders.aspx') INSERT INTO Resource ( ResourceCode, ResourceName, ResourceLevel, ParentID, ResourceSite, Creator, CreateTime, [Status], RelativeSite, NeedParams, PRI ) VALUES ( @resourceCode, N'訂單查詢', 2, @parentID, N'Ho/Order/SearchOrders.aspx', N'huy', GETDATE(), 2, N'QueryType ', 0, 0 )
--修改
PRINT N'---更新菜单名字开始---' IF EXISTS(select * from Resource where ResourceSite='Ho/Order/SearchOrders.aspx') UPDATE Resource SET ResourceName=N'訂單查詢-Online' WHERE ResourceSite='Ho/Order/SearchOrders.aspx';
二、删除数据
1、删除某数据库下所有数据表
declare @sql varchar(8000) while (select count(*) from sysobjects where type='U')>0 begin SELECT @sql='drop table ' + name FROM sysobjects WHERE (type = 'U') ORDER BY 'drop table ' + name exec(@sql) end
2、drop、truncate、delete
- drop
出没场合:drop table tb --tb表示数据表的名字,下同
绝招:删除内容和定义,释放空间。简单来说就是把整个表去掉,以后要新增数据是不可能的,除非新增一个表
- truncate
出没场合:truncate table tb
绝招:删除内容、释放空间但不删除定义(表的数据结构还在)。与drop不同的是,他只是清空表数据而已,他比较温柔
- delete
出没场合:delete table tb --虽然也是删除整个表的数据,但是过程是痛苦的(系统一行一行地删,效率较truncate低)
或 delete table tb where 条件(删除指定的列)
绝招:删除内容不删除定义,不释放空间。三兄弟之中最容易欺负的一个
- 关于truncate的小小总结:
truncate table 在功能上与不带 WHERE 子句的 delete语句相同:二者均删除表中的全部行。
但 truncate 比 delete速度快,且使用的系统和事务日志资源少。
delete 语句每次删除一行,并在事务日志中为所删除的每行记录一项。所以可以对delete操作进行roll back
三、修改数据
1、截取数据
eg:针对PATH字段,将 ftp://ftp://119.156 改为 ftp://119.156
[PATH] = SUBSTRING(PATH,7,LEN(PATH)) 索引是从1开始的,7包括7本身。
2、替换数据
eg:将lieming中的2011全部替换为2014
Update tab
set lieming=replace(lieming,’2011’,’2014’);
3、更新多行
执行一条sql语句update多条不同值。
你想更新多行数据的某个字段的值,并且每行记录的字段值都是各不一样,想使用一条update语句修改。尽可能的减少数据库查询的次数,以减少资源占用,同时可以提高系统速度。
use Test GO UPDATE config SET TaxTypeInFant = CASE WHEN TaxCode='HK' THEN 41 WHEN TaxCode='G3' THEN 42 WHEN TaxCode='I5' THEN 43 WHEN TaxCode='OIL' THEN 44 WHEN TaxCode='TIC' THEN 45 WHEN TaxCode='OTH' THEN 46 WHEN TaxCode='QC' THEN 47 WHEN TaxCode='TK' THEN 48 END WHERE SourceType=2
4、存在则更新,不存在则添加
示例语句
if not exists(select id,abc,def from A_TEST where id = 'A' and abc = 'B') INSERT INTO A_TEST (id,abc,def,ddd) VALUES('A','B','C','D') else update A_TEST set id = 'A',abc='B' ,def='def',ddd='ddd' where id = 'A' and abc = 'B'
注解: if not exists 判断 后面括号中的语句是否可以查询到数据,如果能查询到则执行else后面的 update语句 ;如果 查询不到 则会执行 insert 语句
注意,前面括号中的查询语句条件和 后面的 update语句的条件要一致,
update语句 中 set的数据要和where 后面的条件一致,否则 执行两次会插入一条重复数据。
四、查询数据
1、查询重复数据(并删除)
- 取obuid重复的数据:
SELECT * FROM [cip-middleware].[dbo].[OBU] where OBUID in (select OBUID from OBU group by OBUID having count(OBUID)>1)
若行数为奇数,则可能有重复3条的,将1改为2
- 删除时间小的那条/那两条
DELETE FROM [cip-middleware].[dbo].[OBU] where OBUID in (select OBUID from OBU group by OBUID having count(OBUID)>1) and TIME in (select MIN(TIME) from OBU group by OBUID having COUNT(OBUID)>1 )
- 查找表中多余的重复记录(多个字段)
select * from vitae a where (a.peopleId,a.seq) in (select peopleId,seq from vitae group by peopleId,seq having count(*) > 1)
【这是错误写法】
x in () ,in前面只能一个字段,多条件时候不能用in,要用exists
正确写法:
select * from HISTORY_UPD_DATA a where exists (select 1 from (select TIME,LOTID from HISTORY_UPD_DATA group by TIME,LOTID having count(*) > 1) b where a.TIME = b.TIME and a.LOTID = b.LOTID) order by TIME desc
2、查询去除重复数据
当查询结果只有一个字段的话 直接用distinct
当查询出多个字段的话,只能消除所有字段全部相同的记录。
eg:select distinct id,name from t1 可以取多个字段,但只能消除这2个字段值全部相同的记录
【而且distinct要在最前头】
解决方法:
SELECT id,name FROM t1
WHERE id IN(SELECT MAX(id) FROM t1 GROUP BY name)
order by id desc
注意开头的 id 的 一定要,后面的order by 里有的字段一定要加进select 结果,要不然排序无效
3、多条件查询
示例:
where (case when FLAG=1 then 1 else 0 end case when FLAGCO=1 then 1 else 0 end case when TEMPLATEFLAG=1 then 1 else 0 end case when DEEPFLAG=1 then 1 else 0 end case when BEIHANGFLAG=1 then 1 else 0 end)=5
4、查询数据库所有表的记录数、总记录条数、主键、查索引
选中某一个数据库,新建以下查询,直接执行
select b.[name] '表名',max(a.rowcnt) row from sysindexes a join sys.objects b on b.object_id=a.id where b.type='U' group by b.[name]
总的记录条数
select sum(t.row) as rows from (select b.[name] '表名',max(a.rowcnt) row from sysindexes a join sys.objects b on b.object_id=a.id where b.type='U' group by b.[name]) as t
查所有表的 主键、索引
SELECT a.name AS '表', e.name AS '主键字段',c.name AS '索引名' FROM sysobjects AS a --对象表,结合a.xtype='U'条件,查用户表 LEFT JOIN sysobjects AS b --对象表,结合b.xtype='PK'条件,查主键约束 ON a.id=b.parent_obj LEFT JOIN sysindexes AS c --索引表,根据(主键)约束名称匹配,查对应字段索引 ON a.id=c.id AND b.name=c.name LEFT JOIN sysindexkeys AS d --索引中对应键、列的表,根据索引匹配,查字段id ON a.id=d.id AND c.indid=d.indid LEFT JOIN syscolumns AS e --字段表,根据字段id匹配,查字段名称 ON a.id=e.id AND d.colid=e.colid WHERE a.xtype='U' AND b.xtype='PK'
5、Join连接查询
连接查询,Join默认为Inner Join内连接 【返回两者相等】
Left join 左连接:返回包括左表中的所有记录和右表中联结字段相等的记录
Right join 右连接:返回包括右表中的所有记录和左表中联结字段相等的记录
Linq查询中,多条件查询
from p in store.Repository.Set<EFRa>() join q in store.Repository.Set<EFRo>() on new { p.telID, p.RoomID } equals new { q.telID, q.RoomID }
6、查询条件是中文查不出来数据
数据库中是中文,但是查询条件是中文怎么也查不出来。
原来使用的数据库是英文版本的,所以数据库中的字段值是unicode编码的
首先看看字段类型是不是 : char ->nchar varchar ->nvarchar text ->ntext
然后在查询时加入N:select * form table where city=N'上海'
7、查询时间相关数据
- 获取当前时间
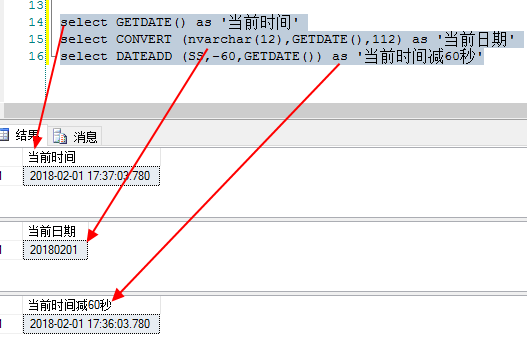
select GETDATE() as '当前时间' --取当天的数据,前一天的则0替换为-1 select CONVERT (nvarchar(12),GETDATE(),112) as '当前日期' --或者 select convert(varchar(10),getdate(),23) 2018-05-08 select DATEADD (SS,-60,GETDATE()) as '当前时间减秒' select DATEDIFF(d,TIME,getdate())>10 10天之前的数据
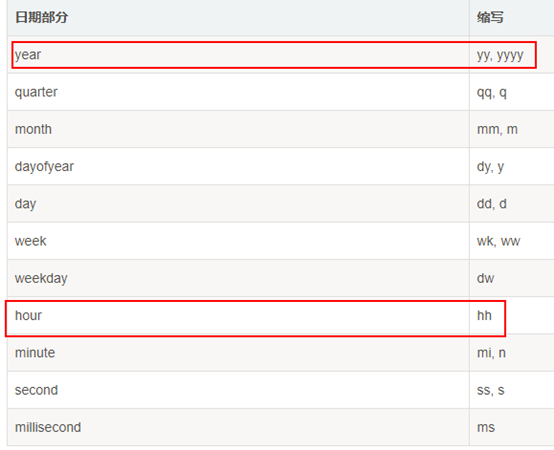
- 获取时间字段的“年、月、日、时、分、秒”
函数DATENAME(param,date);
1、 param是指定要返回日期部分的参数
2、 date就是指定的日期,可以是getdate(),eg:
select DATENAME(year,GETDATE()) as 'YEAR'; --或者 select DATENAME(yy,GETDATE()) as 'YEAR'; select DATENAME(m,GETDATE()) as 'Month';
param枚举
8、计算相邻两条数据某字段之差、同一条数据两列之差
- 相邻两条数据某字段之差
找出uwb中前后两条数据时间、泊位一样的数据,并计算状态之差(不为0则是一进一出)
select *,T1.STATUS -T2.STATUS as diffStatus from (select UPDID,TIME,STATUS ,LOTID from HISTORY_UPD_DATA ) T1 join (select UPDID,TIME,STATUS ,LOTID from HISTORY_UPD_DATA ) T2 on T1.LOTID=T2.LOTID and T1.TIME =T2.TIME and T2.UPDID-T1.UPDID=1 order by T1.TIME desc
- 同一条数据两列之差
DATEDIFF(MI,TIMEIN,TIMEOUT)>1.5 --大于1.5分钟
返回两个日期之间的时间。
select top 100 * from Order where DATEDIFF(day, ArrivalDate, DepartureDate)>1 ORDER BY createTime DESC
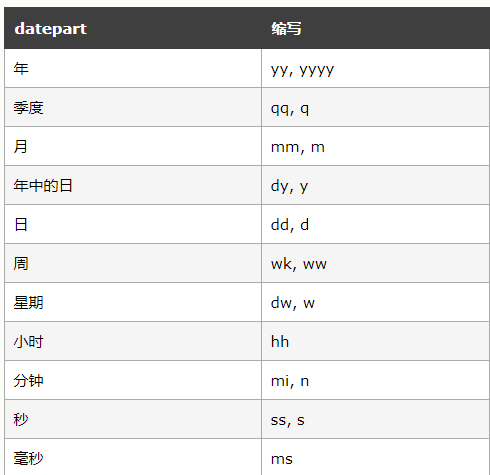
datepart 参数可以是下列的值:
9、查询时多次为表“T”指定了列“LOTID”
select T.LOTID from ( select T1.LOTID,T1.UPDID, T1.TIME,T1.STATUS, T2.LOTID,T2.UPDID, T2.TIME,T2.STATUS , T1.STATUS -T2.STATUS as diffStatus from HISTORY_UPD_DATA T1 join HISTORY_UPD_DATA T2 on T1.LOTID=T2.LOTID and T1.TIME =T2.TIME and T2.UPDID-T1.UPDID=1 )as T where T.diffStatus <>0
在第二行那里已经用了T1. T2.还出现这种错误,有点郁闷。
看到网上说:错误原因是select后面的选项T1.LOTID, T2.LOTID,具有相同的列名(LOTID),解决错误的方法是分别给它们取个不同的别名就好了。
select T.* from ( select T1.LOTID as t1lotid,T1.UPDID as t1updid, T1.TIME as t1time,T1.STATUS as t1status, T2.LOTID,T2.UPDID, T2.TIME,T2.STATUS , T1.STATUS -T2.STATUS as diffStatus from HISTORY_UPD_DATA T1 join HISTORY_UPD_DATA T2 on T1.LOTID=T2.LOTID and T1.TIME =T2.TIME and T2.UPDID-T1.UPDID=1 )as T where T.diffStatus <>0 order by T.t1time desc
10、分页查找
采用row_number,语法格式:row_number() over(partition by 分组列 order by 排序列 desc)
从1开始,为每一条分组记录返回一个数字,
例如找第三页,每页26条数据。
SELECT TOP (26) * FROM(SELECT * , row_number() OVER(ORDER BY[Extent1].[CustomerID] ASC) AS[row_number] FROM[dbo].[Customers] AS[Extent1] ) AS[Extent1] WHERE[Extent1].[row_number] > 52 ORDER BY[Extent1].[CustomerID] ASC
// row_number() OVER(ORDER BY[Extent1].[CustomerID] ASC)
//按照CustomerID升序排列后,再为升序以后的每条CustomID记录返回一个序号。
11、统计某个字段在记录中出现的次数
--找出哪个酒店的单最多,以第2个字段降序排列 SELECT hotelid,count(1) from HotelOrder where Cityid=59 GROUP BY hotelid ORDER BY 2 DESC;
12、 取出表A中第31到第40记录
(SQLServer,以自动增长的ID作为主键,注意:ID可能不是连续的。)
解1:select top 10 * from A where id not in (select top 30 id from A)
解2::select top 10 * from A where id > (select max(id) from (select top 30 id from A )as A)