一.EasyPR
相关讲解(34条消息) 非常详细的讲解车牌识别easypr_再闹东海7的博客-CSDN博客_easypr
开源库介绍
EasyPR是一个中文的开源车牌识别系统,其目标是成为一个简单、高效、准确的车牌识别引擎。相比于其他的车牌识别系统,EasyPR有如下特点:它基于openCV这个开源库。这意味着你可以获取全部源代码,并且移植到java等平台。它能够识别中文。例如车牌为苏EUK722的图片,它可以准确地输出std:string类型的"苏EUK722"的结果。它的识别率较高。图片清晰情况下,车牌检测与字符识别可以达到80%以上的精度。
- 车牌检测(Plate Detection):对一个包含车牌的图像进行分析,最终截取出只包含车牌的一个图块。这个步骤的主要目的是降低了在车牌识别过程中的计算量。如果直接对原始的图像进行车牌识别,会非常的慢,因此需要检测的过程。在本系统中,我们使用SVM(支持向量机)这个机器学习算法去判别截取的图块是否是真的“车牌”。
- 字符识别(Chars Recognition):有的书上也叫Plate Recognition,我为了与整个系统的名称做区分,所以改为此名字。这个步骤的主要目的就是从上一个车牌检测步骤中获取到的车牌图像,进行光学字符识别(OCR)这个过程。其中用到的机器学习算法是著名的人工神经网络(ANN)中的多层感知机(MLP)模型。最近一段时间非常火的“深度学习”其实就是多隐层的人工神经网络,与其有非常紧密的联系。通过了解光学字符识别(OCR)这个过程,也可以知晓深度学习所基于的人工神经网路技术的一些内容。
完整的EasyPR流程
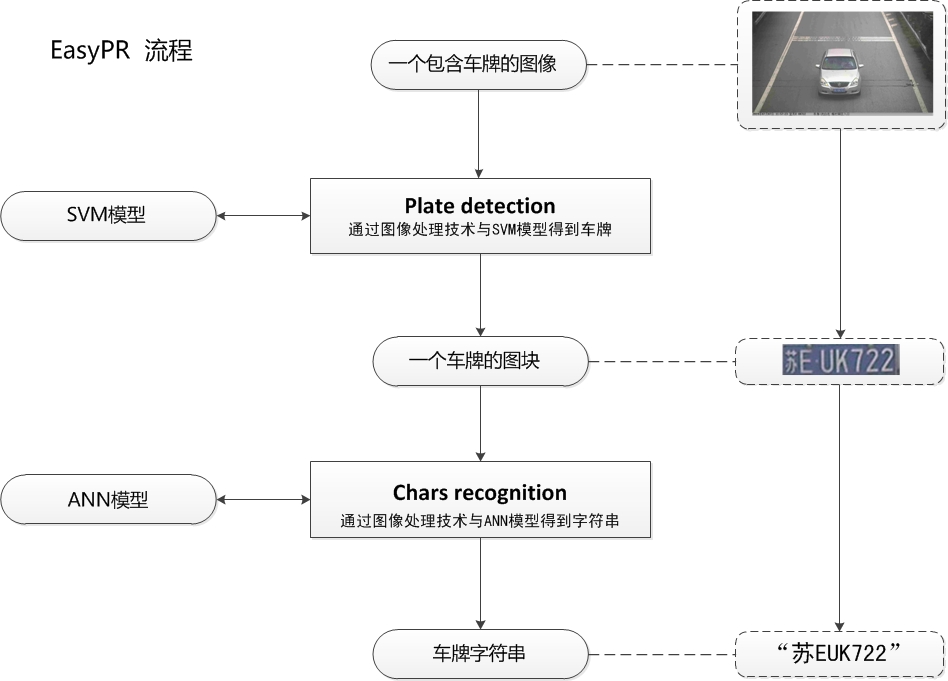
具体说来,EasyPR中PlateDetect与CharsRecognize各包括三个模块。
PlateDetect包括的是车牌定位,SVM训练,车牌判断三个过程,见下图。

PlateDetect过程我们获得了许多可能是车牌的图块,将这些图块进行手工分类,聚集一定数量后,放入SVM模型中训练,得到SVM的一个判断模型,在实际的车牌过程中,我们再把所有可能是车牌的图块输入SVM判断模型,通过SVM模型自动的选择出实际上真正是车牌的图块。
PlateDetect过程结束后,我们获得一个图片中我们真正关心的部分--车牌。那么下一步该如何处理呢。下一步就是根据这个车牌图片,生成一个车牌号字符串的过程,也就是CharsRecognisze的过程。
CharsRecognise包括的是字符分割,ANN训练,字符识别三个过程,具体见下图。
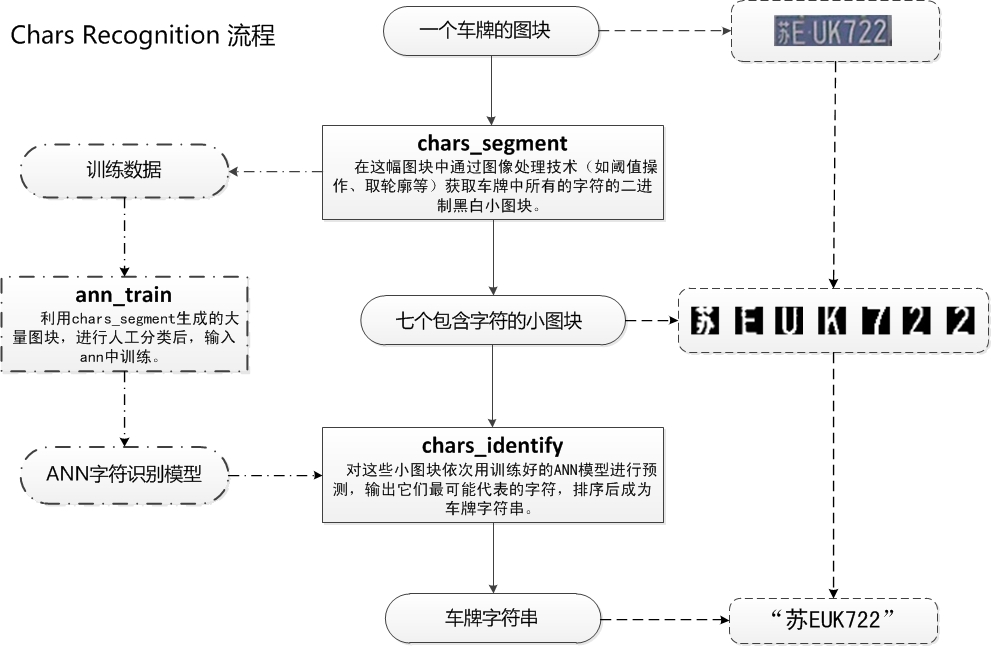
在CharsRecognise过程中,一副车牌图块首先会进行灰度化,二值化,然后使用一系列算法获取到车牌的每个字符的分割图块。获得海量的这些字符图块后,进行手工分类(这个步骤非常耗时间,后面会介绍如何加速这个处理的方法),然后喂入神经网络(ANN)的MLP模型中,进行训练。在实际的车牌识别过程中,将得到7个字符图块放入训练好的神经网络模型,通过模型来预测每个图块所表示的具体字符,例如图片中就输出了“苏EUK722”,(这个车牌只是示例,切勿以为这个车牌有什么特定选取目标。车主既不是作者,也不是什么深仇大恨,仅仅为学术说明选择而已)。
配置实验环境:
absl-py 0.12.0 astunparse 1.6.3 bleach 1.5.0 cached-property 1.5.2 cachetools 4.2.2 certifi 2021.5.30 chardet 4.0.0 cycler 0.10.0 dataclasses 0.8 decorator 4.4.2 easydict 1.9 gast 0.3.3 google-auth 1.30.1 google-auth-oauthlib 0.4.4 google-pasta 0.2.0 grpcio 1.38.0 h5py 2.10.0 html5lib 0.9999999 idna 2.10 imageio 2.9.0 importlib-metadata 4.5.0 Keras 2.0.9 Keras-Preprocessing 1.1.2 kiwisolver 1.3.1 Markdown 3.3.4 matplotlib 3.3.4 networkx 2.5.1 numpy 1.19.5 oauthlib 3.1.1 opencv-python 3.4.3.18 opt-einsum 3.3.0 Pillow 8.2.0 pip 21.1.2 protobuf 3.17.2 pyasn1 0.4.8 pyasn1-modules 0.2.8 pyparsing 2.4.7 python-dateutil 2.8.1 PyWavelets 1.1.1 PyYAML 4.2b4 requests 2.25.1 requests-oauthlib 1.3.0 rsa 4.7.2 scikit-image 0.17.2 scipy 1.4.1 setuptools 49.6.0.post20210108 six 1.16.0 tensorboard 2.2.2 tensorboard-plugin-wit 1.8.0 tensorflow 1.5.0 tensorflow-estimator 2.2.0 tensorflow-tensorboard 1.5.1 termcolor 1.1.0 tifffile 2020.9.3 typing-extensions 3.10.0.0 urllib3 1.26.5 Werkzeug 2.0.1 wheel 0.36.2 wincertstore 0.2 wrapt 1.12.1 zipp 3.4.1
准备工作
训练easypr方法时,请下载easypr_train_data.zip放到data目录下
测试时请下载data.zip放到data目录下 easypr的训练数据和各个模型的训练模型请从百度云上下载
将模型文件:
- whether_car_20180210T1049.zip
- chars_20180210T1038.zip
- mrcnn_20180212T2143.zip
解压放在output下。
最后data文件夹下目录结构是
├─demo
├─easypr_train_data
│ ├─chars
│ └─whether_car
├─general_test
├─GDSL.txt
└─使用说明.txt
output文件夹下目录结构是
├─chars_20180210T1038
├─mrcnn_20180212T2143
└─whether_car_20180210T1049
demo测试
# 用easypr的方法
python demo.py --cfg cfgs/easypr.yml --path data/demo/test.jpg
运行结果
输入图片:

结果输出:
Using TensorFlow backend. Model restored... E:EasyPR-pythonlib..outputwhether_car_20180210T1049modelsmodel.ckpt-9 Plate position: [[ 871. 774.] [ 871. 807.] [1012. 807.] [1012. 774.]] Model restored... E:EasyPR-pythonlib..outputchars_20180210T1038modelsmodel.ckpt-9 Chars Recognize: 苏A0CP56
并生成图片两张


功能测试
python func_test.py --cfg cfgs/easypr.yml
结果输出
Using TensorFlow backend. -------- 功能测试: 1. test plate_detect(车牌检测); 2. test chars_recognize(字符识别); 3. test plate_recognize(车牌识别); -------- 1 Testing Plate Detect Model restored... E:EasyPR-pythonlib..outputwhether_car_20180210T1049modelsmodel.ckpt-9 Plate position: [[ 871. 774.] [ 871. 807.] [1012. 807.] [1012. 774.]] -------- 功能测试: 1. test plate_detect(车牌检测); 2. test chars_recognize(字符识别); 3. test plate_recognize(车牌识别); -------- 2 Testing Chars Recognize Model restored... E:EasyPR-pythonlib..outputchars_20180210T1038modelsmodel.ckpt-9 Chars Recognize: 沪AGH092 (CORRECT) -------- 功能测试: 1. test plate_detect(车牌检测); 2. test chars_recognize(字符识别); 3. test plate_recognize(车牌识别); -------- 3 Testing Plate Recognize Plate position: [[ 871. 774.] [ 871. 807.] [1012. 807.] [1012. 774.]] Chars Recognize: 苏A0CP56 --------
批量测试(data目录下需要有general_test目录)
python accuracy_test.py --cfg cfgs/easypr.yml
结果输出:
Begin to test accuracy -------- Label: 京A88731 Model restored... E:EasyPR-pythonlib..outputwhether_car_20180210T1049modelsmodel.ckpt-9 Model restored... E:EasyPR-pythonlib..outputchars_20180210T1038modelsmodel.ckpt-9 Chars Recognise: 黑A88731 Chars Recognise: 京A88731 time: 13.221395492553711s -------- -------- Label: 京CX8888 Chars Recognise: 辽X8888 Chars Recognise: 京CX888鄂 Chars Recognise: Chars Recognise: time: 77.49492239952087s -------- -------- Label: 京FK5358 time: 54.39446306228638s -------- -------- Label: 京H99999 Chars Recognise: 京H99999 time: 6.030373811721802s -------- -------- Label: 京PC5U22 Chars Recognise: C5U22 time: 13.862390518188477s -------- -------- Label: 冀FA3215 Chars Recognise: 冀FA3215 time: 95.06396842002869s --------
二.HyperLPR
介绍
HyperLPR是一个基于Python的使用深度学习针对对中文车牌识别的实现,与开源的EasyPR相比,它的检测速度和鲁棒性和多场景的适应性都要好于EasyPR。
相关资源
- Android配置教程
- python配置教程
- Linux下C++配置教程
- 带UI界面的工程(感谢群内小伙伴的工作)。
- 端到端(多标签分类)训练代码(感谢群内小伙伴的工作)。
- 端到端(CTC)训练代码(感谢群内小伙伴工作)。
更新
- 更新了Android实现,增加实时扫描接口 (2019.07.24)
- 更新Windows版本的Visual Studio 2015 工程至端到端模型(2019.07.03)
- 更新基于端到端的IOS车牌识别工程。(2018.11.13)
- 可通过pip一键安装、更新的新的识别模型、倾斜车牌校正算法、定位算法。(2018.08.11)
- 提交新的端到端识别模型,进一步提高识别准确率(2018.08.03)
- 增加PHP车牌识别工程@coleflowers (2018.06.20)
- 添加了HyperLPR Lite 仅仅需160 行代码即可实现车牌识别(2018.3.12)
- 感谢 sundyCoder Android 字符分割版本
- 增加字符分割训练代码和字符分割介绍(2018.1.)
TODO
- 支持多种车牌以及双层
- 支持大角度车牌
- 轻量级识别模型
特性
- 速度快 720p,单核 Intel 2.2G CPU (MaBook Pro 2015)平均识别时间低于100ms
- 基于端到端的车牌识别无需进行字符分割
- 识别率高,卡口场景准确率在95%-97%左右
- 轻量,总代码量不超1k行
模型资源说明
- cascade.xml 检测模型 - 目前效果最好的cascade检测模型
- cascade_lbp.xml 召回率效果较好,但其错检太多
- char_chi_sim.h5 Keras模型-可识别34类数字和大写英文字 使用14W样本训练
- char_rec.h5 Keras模型-可识别34类数字和大写英文字 使用7W样本训练
- ocr_plate_all_w_rnn_2.h5 基于CNN的序列模型
- ocr_plate_all_gru.h5 基于GRU的序列模型从OCR模型修改,效果目前最好但速度较慢,需要20ms。
- plate_type.h5 用于车牌颜色判断的模型
- model12.h5 左右边界回归模型
注意事项:
- Win工程中若需要使用静态库,需单独编译
- 本项目的C++实现和Python实现无任何关联,都为单独实现
- 在编译C++工程的时候必须要使用OpenCV 3.3以上版本 (DNN 库),否则无法编译
- 安卓工程编译ndk尽量采用14b版本
环境
win10、anaconda4.8.3 、python3.8
github地址:
https://github.com/zeusees/HyperLPR
https://gitee.com/zeusees/HyperLPR
填坑参考网址:
https://www.cnblogs.com/zhupengfei/p/12104504.html
配置参考网址:
https://www.jianshu.com/p/7ab673abeaae
项目配置过程:
(1)实际上只需要 hyperlpr_py3 、Font 、model 三个文件夹。单独拿出来建个文件夹,再建个car,把测试图片放里面。
(2)cmd后创建一个新环境 conda create -n hyperlpr36 python=3.6,然后查看自己的环境 conda info -e
(删除某个环境是 conda remove -n hyperlpr --all)
(3)然后激活它 activate hyperlpr36,使用 conda list 查看里面安装的包。安装需要的包,也可以选择其他的源:
pip install keras==2.0.9 -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
pip install Theano==1.0.4 -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
pip install numpy==1.16.0 -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
pip install Scipy==1.4.1 -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
pip install opencv-python==3.4.3.18 -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
pip install scikit-image==0.17.2 -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
pip install pillow==7.1.2 -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
pip install tensorflow==1.2.0 -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
pip install h5py==2.10.0 -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
(4)把hyperlpr_py3复制到你的目录Anaconda3envshyperlpr36Lib下,并改名为hyperlpr。
(5)可以在 pycharm 测试,也可以用 jupyter notebook 测试。
pycharm中
新建一个test.py,记得编译器必须选刚刚建的虚拟环境
from hyperlpr import pipline as pp
import cv2
# 自行修改文件名
image = cv2.imread("./car/3.jpg")
image,res = pp.SimpleRecognizePlate(image)
print(res)
jupyter notebook中
在hyperlpr36环境下进入jupyter notebook
找到你的源目录,new一个python3的test文件,代码一样
点击kernel中的change kernel,选择你的虚拟环境
这里也许只有python 3选项,因为还没导入虚拟环境。步骤如下:
1.在cmd中激活hyperlpr36环境
2.在hyperlpr36环境中中安装好ipykernel
conda install ipykernel
3.在你的C:ProgramDatajupyterkernels路径下生成hyperlpr36文件
python -m ipykernel install --name adda
现在重新打开jupyter notebook,里面就会显示有这个虚拟环境了
运行结果
输入图片:

打印结果:
(518, 690, 3)
校正角度 h 0 v 90
keras_predict [0.15252575 0.8190352 ]
c43d6973
e2e: ('京EL0662', 0.9415582844189235)
校正 0.3470723628997803 s
分割 0.14561128616333008
254
寻找最佳点 0.06282758712768555
字符识别 0.21841692924499512
分割和识别 0.4308490753173828 s
车牌: 京EL0662 置信度: 0.99361081634249
1.9338304996490479 s
['京EL0662']
相关问题及解答
Q:Android识别率没有所传demo apk的识别率高?
A:请使用Prj-Linux下的模型,android默认包里的配置是相对较早的模型
Q:车牌的训练数据来源?
A:由于用于训练车牌数据涉及到法律隐私等问题,本项目无法提供。开放较为大的数据集有CCPD车牌数据集。
Q:训练代码的提供?
A:相关资源中有提供训练代码
Q:关于项目的来源?
A:此项目来源于作者早期的研究和调试代码,代码缺少一定的规范,同时也欢迎PR。
三.LPRNet
相关讲解LPRnet轻量级实时车牌识别,主网络代码以及论文思路简要介绍 - you-wh - 博客园 (cnblogs.com)、(35条消息) PyTorch实现的MTCNN/LPRNet车牌识别_平凡简单的执着-CSDN博客
LPRNet简介
LPRNet全称就叫做License Plate Recognition via Deep Neural Networks(基于深层神经网络的车牌识别)。LPRNet由轻量级的卷积神经网络组成,所以它可以采用端到端的方法来进行训练。据我们所知,LPRNet是第一个没有采用RNNs的实时车牌识别系统。因此,LPRNet算法可以为LPR创建嵌入式部署的解决方案,即便是在具有较高挑战性的中文车牌识别上。
LPRNet特性
实时、高精度、支持车牌字符变长、无需字符分割、对不同国家支持从零开始end-to-end的训练;
第一个不需要使用RNN的足够轻量级的网络,可以运行在各种平台,包括嵌入式设备;
鲁棒,LPRNet已经应用于真实的交通监控场景,事实证明它可以鲁棒地应对各种困难情况,包括透视变换、镜头畸变带来的成像失真、强光、视点变换等。
特征提取骨干网络架构
骨干网络的结构在表[3]中进行了描述。骨干网络获取原始的RGB图片作为输入,并且计算出大量特征的空间分布。宽卷积(1*13的卷积核)利用本地字符的上下文从而取代了基于LSTM的RNN网络。骨干子网络的输出可以被认为是一个代表对应字符可能性的序列,它的长度刚到等于输入图像的宽度。由于解码器的输出与目标字符序列的长度是不一致的,因此采用了CTC损失函数,无需分割的端到端训练。CTC 损失函数是一种广泛地用于处理输入和输出序列不对齐的方法。
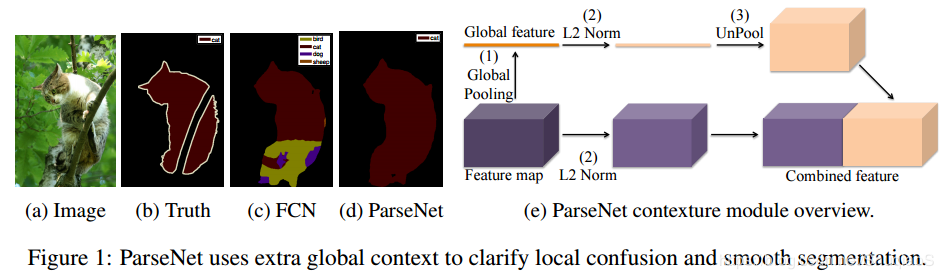
为了进一步地提升模型的表现,增强解码器所得的中间特征图,采用用全局上下文关系进行嵌入[12]。它是通过全连接层对骨干网络的输出层进行计算,随后将其平铺到所需的大小最后再与骨干网络的输出进行拼接 , 加入GAP思想源于Parsenet,parsenet主要图:,右侧部分为加入GAP拼接到feature map上进行识别的表示。
对测试集1000张图片的实验结果如下:
[Info] Test Accuracy: 0.894 [894:69:37:1000]
[Info] Test Speed: 0.2548015410900116s 1/1000]
识别结果打印:
target: 苏HXN335 ### F ### predict: 苏HTXN335 target: 皖AZ787K ### T ### predict: 皖AZ787K target: 皖A6N958 ### T ### predict: 皖A6N958 target: 皖A6B667 ### T ### predict: 皖A6B667 target: 皖A32C32 ### F ### predict: 皖A32C362 target: 皖A753V2 ### T ### predict: 皖A753V2
四.alpr-unconstrained
相关讲解ALPR:无约束场景中的车牌检测和识别 - 简书 (jianshu.com)
简介
随着深度学习的兴起,最先进的ALPR技术开始向另一个方向发展,现在许多作品都采用CNN,因为它在通用物体检测和识别的精度很高。与ALPR相关的是场景文本定位(Scene Text Spotting,STS)和户外数字读取问题,目标是在自然场景中找到并读取文本/数字。尽管ALPR可以被视为STS的一个特例,但这两个问题具有特殊的特征:在ALPR中,需要学习没有相关语义信息的字符和数字(没有太多字体变化),而STS则专注于字体可变性高的文本信息,并探索词汇和语义信息。数字读取任务比ALPR的内容简单,因为它避免了常见的数字/字母混淆,例如B-8,D-0,1-I,5-S。
使用CNN的ALPR商业系统,比较著名的有Sighthound、OpenALPR商业版 和 Amazon Rekognition。尽管这些系统的技术取得了进步,但大多数ALPR系统主要使用车辆和LP的正面视图,这在诸如收费监控和停车场验证等应用中很常见。 然而,更宽泛的图像获取场景(例如,执法人员使用移动相机或智能电话拍照)可能导致车牌被高度扭曲,但仍然可读,如图1所示,即使最先进的商业系统也在为识别这些挑战性场景中的车牌而努力。
方法介绍
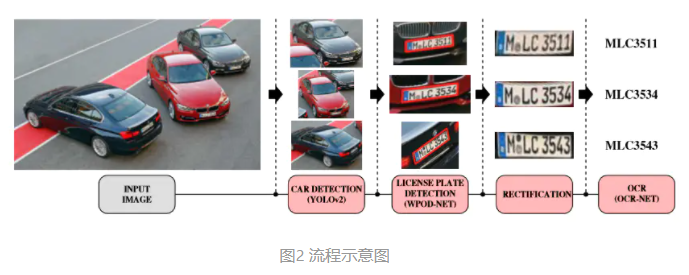
车辆检测
由于车辆是许多经典目标检测和识别数据集(如Pascal-VOC、ImageNet和Coco)中存在的潜在目标之一,因此作者决定不从头开始训练检测器,而是选择一个已知模型来执行车辆检测,并考虑一些标准。一方面,要求较高的召回率,因为任何具有可见LP的漏检车辆将直接导致整个LP漏检。另一方面,由于每个错误检测到的车辆必须通过WPOD-NET进行验证,因此精度过高也可能导致运行时间过长。基于这些考虑,决定使用yolov2网络,因为它执行速度快(大约70 fps),精度和召回率折衷性好(pascal-voc数据集上有76.8%的mAP)。作者没有对yolov2进行任何更改或修改,只是将网络当作黑盒,合并与车辆(比如汽车和公共汽车)相关的输出,忽略其他类。
检测结果(车辆)在被送入wpod-net之前需要调整大小。根据经验,较大的输入图像允许检测较小的目标,但会增加计算成本。在大致的前/后视图中,车牌尺寸和车辆边界框(BB)之间的比率很高。然而,对于斜视/侧视而言,此比率往往要小得多,因为倾斜车辆的边界框往往更大、更长。因此,倾斜视图的大小应比正面视图大,以保持LP区域的可识别性。虽然可以使用三维姿态估计方法来确定调整比例,但本论文提出了一个基于车辆边界框高宽比的简单快速的过程。当它接近1时,可以使用较小的尺寸,并且必须随着长宽比的增大而增大。
实验结果如下:
layer filters size input output 0 conv 32 3 x 3 / 1 416 x 416 x 3 -> 416 x 416 x 32 0.299 BFLOPs 1 max 2 x 2 / 2 416 x 416 x 32 -> 208 x 208 x 32 2 conv 64 3 x 3 / 1 208 x 208 x 32 -> 208 x 208 x 64 1.595 BFLOPs 3 max 2 x 2 / 2 208 x 208 x 64 -> 104 x 104 x 64 4 conv 128 3 x 3 / 1 104 x 104 x 64 -> 104 x 104 x 128 1.595 BFLOPs 5 conv 64 1 x 1 / 1 104 x 104 x 128 -> 104 x 104 x 64 0.177 BFLOPs 6 conv 128 3 x 3 / 1 104 x 104 x 64 -> 104 x 104 x 128 1.595 BFLOPs 7 max 2 x 2 / 2 104 x 104 x 128 -> 52 x 52 x 128 8 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256 1.595 BFLOPs 9 conv 128 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 128 0.177 BFLOPs 10 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256 1.595 BFLOPs 11 max 2 x 2 / 2 52 x 52 x 256 -> 26 x 26 x 256 12 conv 512 3 x 3 / 1 26 x 26 x 256 -> 26 x 26 x 512 1.595 BFLOPs 13 conv 256 1 x 1 / 1 26 x 26 x 512 -> 26 x 26 x 256 0.177 BFLOPs 14 conv 512 3 x 3 / 1 26 x 26 x 256 -> 26 x 26 x 512 1.595 BFLOPs 15 conv 256 1 x 1 / 1 26 x 26 x 512 -> 26 x 26 x 256 0.177 BFLOPs 16 conv 512 3 x 3 / 1 26 x 26 x 256 -> 26 x 26 x 512 1.595 BFLOPs 17 max 2 x 2 / 2 26 x 26 x 512 -> 13 x 13 x 512 18 conv 1024 3 x 3 / 1 13 x 13 x 512 -> 13 x 13 x1024 1.595 BFLOPs 19 conv 512 1 x 1 / 1 13 x 13 x1024 -> 13 x 13 x 512 0.177 BFLOPs 20 conv 1024 3 x 3 / 1 13 x 13 x 512 -> 13 x 13 x1024 1.595 BFLOPs 21 conv 512 1 x 1 / 1 13 x 13 x1024 -> 13 x 13 x 512 0.177 BFLOPs 22 conv 1024 3 x 3 / 1 13 x 13 x 512 -> 13 x 13 x1024 1.595 BFLOPs 23 conv 1024 3 x 3 / 1 13 x 13 x1024 -> 13 x 13 x1024 3.190 BFLOPs 24 conv 1024 3 x 3 / 1 13 x 13 x1024 -> 13 x 13 x1024 3.190 BFLOPs 25 route 16 26 conv 64 1 x 1 / 1 26 x 26 x 512 -> 26 x 26 x 64 0.044 BFLOPs 27 reorg / 2 26 x 26 x 64 -> 13 x 13 x 256 28 route 27 24 29 conv 1024 3 x 3 / 1 13 x 13 x1280 -> 13 x 13 x1024 3.987 BFLOPs 30 conv 125 1 x 1 / 1 13 x 13 x1024 -> 13 x 13 x 125 0.043 BFLOPs 31 detection mask_scale: Using default '1.000000' Loading weights from data/vehicle-detector/yolo-voc.weights...Done! Searching for vehicles using YOLO... Scanning samples/test/03009.jpg 2 cars found Scanning samples/test/03016.jpg 1 cars found Scanning samples/test/03025.jpg 1 cars found Scanning samples/test/03033.jpg 1 cars found Scanning samples/test/03057.jpg 1 cars found Scanning samples/test/03058.jpg 2 cars found Scanning samples/test/03066.jpg 3 cars found Scanning samples/test/03071.jpg 1 cars found Using TensorFlow backend. 2021-06-10 11:34:50.896375: I tensorflow/core/platform/cpu_feature_guard.cc:137] Your CPU supports instructions that this TensorFlow binary was not compiled to use: SSE4.1 SSE4.2 AVX AVX2 FMA Searching for license plates using WPOD-NET Processing /tmp/output/03066_1car.png Bound dim: 490, ratio: 1.685950 Processing /tmp/output/03057_0car.png Bound dim: 526, ratio: 1.804819 Processing /tmp/output/03025_0car.png Bound dim: 568, ratio: 1.958333 Processing /tmp/output/03033_0car.png Bound dim: 476, ratio: 1.606780 Processing /tmp/output/03071_0car.png Bound dim: 608, ratio: 2.156250 Processing /tmp/output/03066_0car.png Bound dim: 544, ratio: 1.889503 Processing /tmp/output/03009_1car.png Bound dim: 608, ratio: 3.037433 Processing /tmp/output/03009_0car.png Bound dim: 526, ratio: 1.802211 Processing /tmp/output/03058_0car.png Bound dim: 346, ratio: 1.159664 Processing /tmp/output/03066_2car.png Bound dim: 608, ratio: 2.135135 Processing /tmp/output/03016_0car.png Bound dim: 606, ratio: 2.052117 Processing /tmp/output/03058_1car.png Bound dim: 372, ratio: 1.288136 layer filters size input output 0 conv 32 3 x 3 / 1 240 x 80 x 3 -> 240 x 80 x 32 0.033 BFLOPs 1 max 2 x 2 / 2 240 x 80 x 32 -> 120 x 40 x 32 2 conv 64 3 x 3 / 1 120 x 40 x 32 -> 120 x 40 x 64 0.177 BFLOPs 3 max 2 x 2 / 2 120 x 40 x 64 -> 60 x 20 x 64 4 conv 128 3 x 3 / 1 60 x 20 x 64 -> 60 x 20 x 128 0.177 BFLOPs 5 conv 64 1 x 1 / 1 60 x 20 x 128 -> 60 x 20 x 64 0.020 BFLOPs 6 conv 128 3 x 3 / 1 60 x 20 x 64 -> 60 x 20 x 128 0.177 BFLOPs 7 max 2 x 2 / 2 60 x 20 x 128 -> 30 x 10 x 128 8 conv 256 3 x 3 / 1 30 x 10 x 128 -> 30 x 10 x 256 0.177 BFLOPs 9 conv 128 1 x 1 / 1 30 x 10 x 256 -> 30 x 10 x 128 0.020 BFLOPs 10 conv 256 3 x 3 / 1 30 x 10 x 128 -> 30 x 10 x 256 0.177 BFLOPs 11 conv 512 3 x 3 / 1 30 x 10 x 256 -> 30 x 10 x 512 0.708 BFLOPs 12 conv 256 3 x 3 / 1 30 x 10 x 512 -> 30 x 10 x 256 0.708 BFLOPs 13 conv 512 3 x 3 / 1 30 x 10 x 256 -> 30 x 10 x 512 0.708 BFLOPs 14 conv 80 1 x 1 / 1 30 x 10 x 512 -> 30 x 10 x 80 0.025 BFLOPs 15 detection mask_scale: Using default '1.000000' Loading weights from data/ocr/ocr-net.weights...Done! Performing OCR... Scanning /tmp/output/03009_0car_lp.png LP: GN06BG Scanning /tmp/output/03016_0car_lp.png LP: MPE3389 Scanning /tmp/output/03025_0car_lp.png LP: INS6012 Scanning /tmp/output/03033_0car_lp.png LP: SEZ229 Scanning /tmp/output/03057_0car_lp.png LP: INTT263 Scanning /tmp/output/03058_1car_lp.png LP: C24JBH Scanning /tmp/output/03066_0car_lp.png LP: 77 Scanning /tmp/output/03066_2car_lp.png LP: HHP8586 Scanning /tmp/output/03071_0car_lp.png LP: 6GQR959
开源数据集
CCPD(中国城市停车数据集,ECCV)和PDRC(车牌检测与识别挑战)。这是一个用于车牌识别的大型国内的数据集,由中科大的科研人员构建出来的。发表在ECCV2018论文Towards End-to-End License Plate Detection and Recognition: A Large Dataset and Baseline
下载地址镜像/检测雷科格/ccpd_代码中国 (csdn.net)
该数据集在合肥市的停车场采集得来,采集时间早上7:30到晚上10:00。停车场采集人员手持Android POS机对停车场的车辆拍照并手工标注车牌位置。拍摄的车牌照片涉及多种复杂环境,包括模糊、倾斜、阴雨天、雪天等等。CCPD数据集一共包含将近30万张图片,每种图片大小720x1160x3。一共包含8项,具体如下:
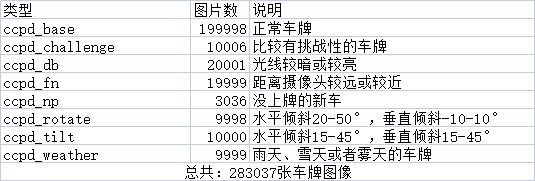
部分照片示例如下:

CCPD数据集没有专门的标注文件,每张图像的文件名就是对应的数据标注(label)。
例如:025-95_113-154&383_386&473-386&473_177&454_154&383_363&402-0_0_22_27_27_33_16-37-15.jpg
由分隔符'-'分为几个部分:
1) 025为区域,
2) 95_113 对应两个角度, 水平95°, 竖直113°
3) 154&383_386&473对应边界框坐标:左上(154, 383), 右下(386, 473)
4) 386&473_177&454_154&383_363&402对应四个角点坐标
5) 0_0_22_27_27_33_16为车牌号码 映射关系如下: 第一个为省份0 对应省份字典皖, 后面的为字母和文字, 查看ads字典.如0为A, 22为Y....
具体的,省份对应标签如下:
{ "皖": 0, "沪": 1, "津": 2, "渝": 3, "冀": 4, "晋": 5, "蒙": 6, "辽": 7, "吉": 8, "黑": 9, "苏": 10, "浙": 11, "京": 12, "闽": 13, "赣": 14, "鲁": 15, "豫": 16, "鄂": 17, "湘": 18, "粤": 19, "桂": 20, "琼": 21, "川": 22, "贵": 23, "云": 24, "西": 25, "陕": 26, "甘": 27, "青": 28, "宁": 29, "新": 30 }
字母和数字对应的标签如下:
{ "a" : 0, "b" : 1, "c" : 2, "d" : 3, "e" : 4, "f" : 5, "g" : 6, "h" : 7, "j" : 8, "k" : 9, "l" : 10, "m" : 11, "n" : 12, "p" : 13, "q" : 14, "r" : 15, "s" : 16, "t" : 17, "u" : 18, "v" : 19, "w" : 20, "x": 21, "y" : 22, "z" : 23, "0" : 24, "1" : 25, "2" : 26, "3" : 27, "4" : 28, "5" : 29, "6" : 30, "7" : 31, "8" : 32, "9" : 33 }
五.总结
推理时间对比
| 单张推理时间(s) | |
| LPRNet | 0.264 |
| EasyPR | 18.888 |
| HyperLPR | 1.074 |
推理精度对比
| 推理精度 | |
| LPRNet | 0.894 |
| EasyPR | 0.142 |
| HyperLPR | 0.583 |