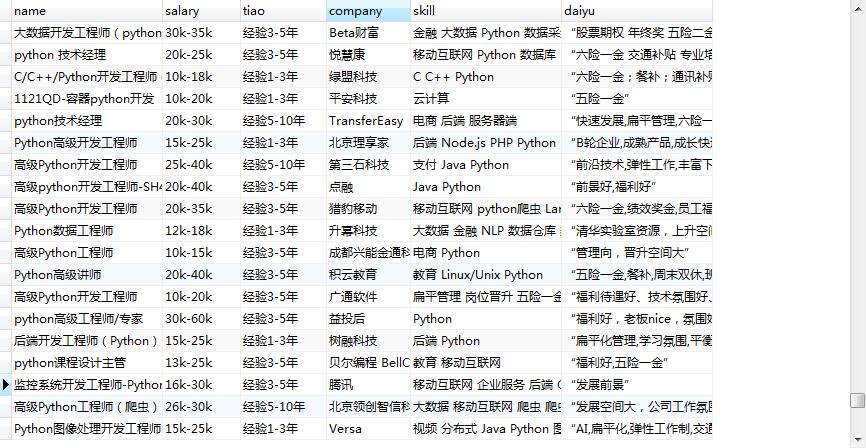
from urllib import request import requests import time import pymysql from selenium import webdriver from selenium.common.exceptions import TimeoutException from selenium.webdriver.common.action_chains import ActionChains from selenium.webdriver.support.wait import WebDriverWait from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.common.by import By db=pymysql.connect('localhost','root','123qwe','ok') cur=db.cursor() #sql='create table lagou(name varchar(50),salary varchar(10),tiao varchar(10),company varchar(20),skill varchar(30),daiyu varchar(30))' #cur.execute(sql) url='https://www.lagou.com/' #opt = webdriver.chrome.options.Options() #opt.set_headless() broswer=webdriver.Chrome() broswer.get(url) broswer.find_element_by_id("cboxClose").click() time.sleep(1) ok=broswer.find_element_by_xpath('//input[@id="search_input"]') broswer.execute_script("arguments[0].click();", ok) broswer.find_element_by_xpath('//input[@id="search_input"]').send_keys('python') op=broswer.find_element_by_id('search_button') broswer.execute_script("arguments[0].click();",op) k=1 while k <= 30: print(k) time.sleep(2) name=broswer.find_elements_by_xpath('//a[@class="position_link"]/h3') classd=broswer.find_elements_by_xpath('//div[@class="p_bot"]/div[@class="li_b_l"]') comany=broswer.find_elements_by_xpath('//div[@class="company_name"]/a') skill=broswer.find_elements_by_xpath('//div[@class="list_item_bot"]/div[@class="li_b_l"]') daiyu=broswer.find_elements_by_xpath('//div[@class="list_item_bot"]/div[@class="li_b_r"]') for i in range(len(name)): sql='insert into lagou(name,salary,tiao,company,skill,daiyu) values(%s,%s,%s,%s,%s,%s)' value=(name[i].text,classd[i].text.split(' ')[0],classd[i].text.split(' ')[1],comany[i].text,skill[i].text,daiyu[i].text) cur.execute(sql,value) db.commit() time.sleep(1) js="var q=document.documentElement.scrollTop=3000" broswer.execute_script(js)#下拉滚动条 time.sleep(1) pages = broswer.find_element_by_xpath('//*[@id="s_position_list"]/div[2]/div/span[6]') ActionChains(broswer).move_to_element(pages).perform() try: next = WebDriverWait(broswer, 10).until( EC.element_to_be_clickable((By.CLASS_NAME, 'pager_next ')) ) next.click() except TimeoutException: next_page()#点击下一页非常关键,用平时click失效的方法,会从第3页直接跳到最后一页 k=k+1 cur.close() broswer.close()