参考 keras官网
问题描述:通过模型对故障单按照优先级排序并制定给正确的部门。
输入:
- 票证的标题(文本输入),
- 票证的文本正文(文本输入),以及
- 用户添加的任何标签(分类输入)
输出:
- 优先级分数介于0和1之间(sigmoid 输出),以及
- 应该处理票证的部门(部门范围内的softmax输出)
1 import keras 2 import numpy as np 3 4 num_tags = 12 # Number of unique issue tags 5 num_words = 10000 # 预处理文本数据时获得的词汇量 6 num_departments = 4 # Number of departments for predictions 7 8 title_input = keras.Input( 9 shape=(None,), name="title" 10 ) # Variable-length sequence of ints 11 body_input = keras.Input(shape=(None,), name="body") # Variable-length sequence of ints 12 tags_input = keras.Input( 13 shape=(num_tags,), name="tags" 14 ) # Binary vectors of size `num_tags` 15 16 # Embed each word in the title into a 64-dimensional vector 17 title_features = keras.layers.Embedding(num_words, 64)(title_input) 18 # Embed each word in the text into a 64-dimensional vector 19 body_features = keras.layers.Embedding(num_words, 64)(body_input) 20 21 # Reduce sequence of embedded words in the title into a single 128-dimensional vector 22 title_features = keras.layers.LSTM(128)(title_features) 23 # Reduce sequence of embedded words in the body into a single 32-dimensional vector 24 body_features = keras.layers.LSTM(32)(body_features) 25 26 # Merge all available features into a single large vector via concatenation 27 x = keras.layers.concatenate([title_features, body_features, tags_input]) 28 29 # Stick a logistic regression for priority prediction on top of the features 30 priority_pred = keras.layers.Dense(1, name="priority")(x) 31 # Stick a department classifier on top of the features 32 department_pred = keras.layers.Dense(num_departments, name="department")(x) 33 34 # Instantiate an end-to-end model predicting both priority and department 35 model = keras.Model( 36 inputs=[title_input, body_input, tags_input], 37 outputs=[priority_pred, department_pred], 38 ) 39 model.summary() 40 keras.utils.plot_model(model, "multi_input_and_output_model.png", show_shapes=True) 41 42 # model.compile( 43 # optimizer=keras.optimizers.RMSprop(1e-3), 44 # loss={ 45 # "priority": "binary_crossentropy", 46 # "department": "categorical_crossentropy", 47 # }, 48 # loss_weights=[1.0, 0.2], 49 # ) 50 51 model.compile( 52 optimizer=keras.optimizers.RMSprop(1e-3), 53 loss={ 54 "priority": "binary_crossentropy", 55 "department": "categorical_crossentropy", 56 }, 57 loss_weights={'priority': 1., 'department': 0.2},) 58 # Dummy input data 59 title_data = np.random.randint(num_words, size=(1280, 10)) 60 body_data = np.random.randint(num_words, size=(1280, 100)) 61 tags_data = np.random.randint(2, size=(1280, num_tags)).astype("float32") 62 63 # Dummy target data 64 priority_targets = np.random.random(size=(1280, 1)) 65 dept_targets = np.random.randint(2, size=(1280, num_departments)) 66 67 model.fit( 68 {"title": title_data, "body": body_data, "tags": tags_data}, 69 {"priority": priority_targets, "department": dept_targets}, 70 epochs=2, 71 batch_size=32, 72 ) 73 model.save("path_to_my_model") 74 model = keras.models.load_model("path_to_my_model")
环境:keras==2.2.4 tensorflow==1.12.0
模型结构
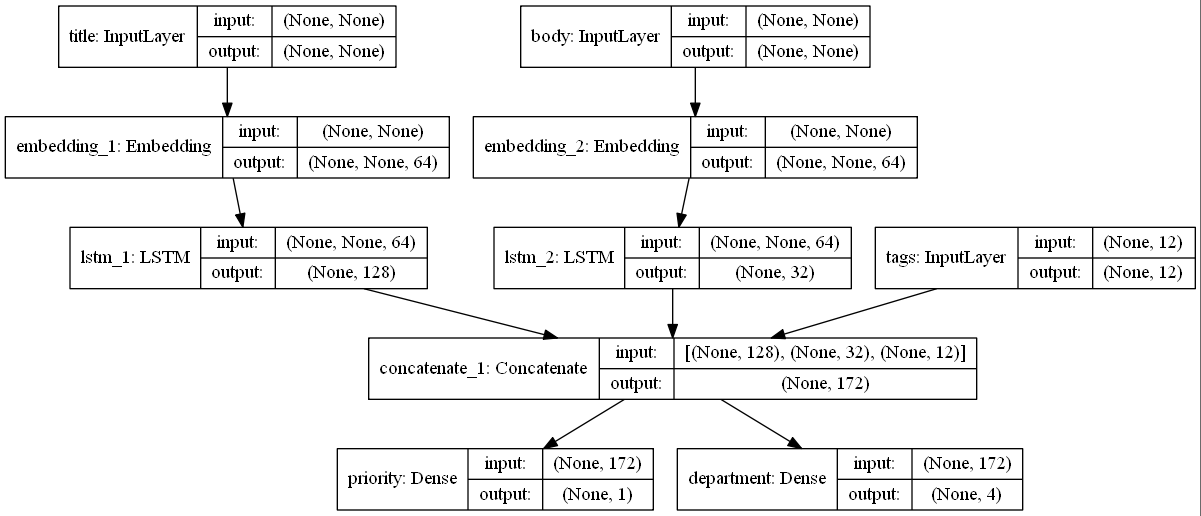
模型参数
__________________________________________________________________________________________________ Layer (type) Output Shape Param # Connected to ================================================================================================== title (InputLayer) (None, None) 0 __________________________________________________________________________________________________ body (InputLayer) (None, None) 0 __________________________________________________________________________________________________ embedding_1 (Embedding) (None, None, 64) 640000 title[0][0] __________________________________________________________________________________________________ embedding_2 (Embedding) (None, None, 64) 640000 body[0][0] __________________________________________________________________________________________________ lstm_1 (LSTM) (None, 128) 98816 embedding_1[0][0] __________________________________________________________________________________________________ lstm_2 (LSTM) (None, 32) 12416 embedding_2[0][0] __________________________________________________________________________________________________ tags (InputLayer) (None, 12) 0 __________________________________________________________________________________________________ concatenate_1 (Concatenate) (None, 172) 0 lstm_1[0][0] lstm_2[0][0] tags[0][0] __________________________________________________________________________________________________ priority (Dense) (None, 1) 173 concatenate_1[0][0] __________________________________________________________________________________________________ department (Dense) (None, 4) 692 concatenate_1[0][0] ================================================================================================== Total params: 1,392,097 Trainable params: 1,392,097
参数计算方法
该模型有前馈神经网络和LSTM。参考深度学习模型参数计算。