慢查询
查询任务涉及到:网络,CPU计算,生成统计信息和执行计划,锁等待等操作。这些需要内存操作,CPU操作,内存不足导致I/O操作上消耗时间。
优化数据访问
性能低下的主要原因是访问的数据太多
可能存在的问题:
-
相同数据重复查询,可以利用缓存技术,减少
-
查找所有的列
-
查找不需要的记录
衡量查询开销的三个指标:
-
响应时间
-
服务时间:处理查询所需时间
-
排队时间:等待任务执行的时间
-
-
扫描行数
-
通过EXPLAIN 语句返回的type列返回的访问类型
- 索引的好处是可以查找更少的行
-
-
返回的行数
重构查询的方式
-
可以将SQL复杂查询切割成多个小查询
-
将一个查询数据很多条的进行分页,成小的查询
-
可以将多个关联查询切分成多个简单查询;
-
单个表查询有缓存,可以利用到查询缓存的结果;
-
减少了数据库锁竞争
-
减少重复查询的数据
-
查询执行的基础
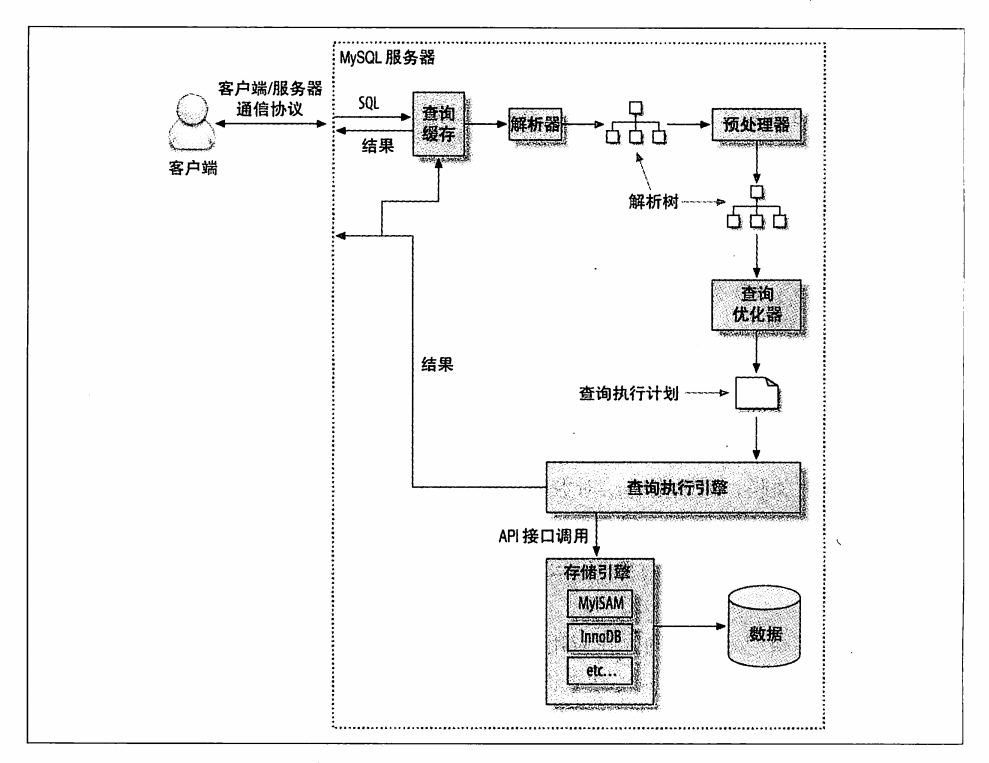
-
客户端发送查询给服务器,服务器先检查缓存是否命中
-
如果缓存命中则返回查询结果,如果没有命中,服务器进行SQL解析数据处理,再进行优化器生成执行计划
-
进行数据查询并进行缓存,返回数据
SQL优化
-
IN,EXISTS和关联子查询
-
涉及到IN内部子查询,数据库优化器会自动将IN方法里面的查询转成EXISTS查询
-
EXISTS查询时,外层的表查询的type是ALL,所以当外部表很大时,效率会很低;
-
可以通过INNER JOIN或者LEFT JOIN代替IN()方法的子查询
-
-
UNION ALL
- 会创建一个数据查询的临时表
-
最大值最小值优化
-
MIN(),MAX()查询有的时候不是很好的选择
-
可以通过order by 和limit 1 联合处理
-
-
COUNT 统计
-
不统计列为null的值
-
COUNT(*) 统计行数
-
-
关联查询优化
-
ON或USING子句的列上有索引
-
关联顺序,A/B表关联,关联顺序是A/B,可以不用在A表关联上建索引
-
-
LIMIT优化
-
可以将LIMIT查询切换成两部分
-
limit 查询数据的主键
-
查找这些主键的数据
-
-