ConcurrentHashMap相较于HashMap最大的特点就是线程安全的。
这篇随笔主要了解以下ConcurrentHashMap的基本知识.
环境:JDK1.8
1.初始化
构造函数
-
1.可以看出默认的初始容量是16;
-
2.默认的平衡因子是0.75f
//默认初始容量时16
private static final int DEFAULT_CAPACITY = 16;
//平衡因子默认是0.75
private static final float LOAD_FACTOR = 0.75f;
//最大容量 1073741824
private static final int MAXIMUM_CAPACITY = 1 << 30;
//设置控制容量sizeCtl
public ConcurrentHashMap(int initialCapacity,
float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0.0f) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
if (initialCapacity < concurrencyLevel) // Use at least as many bins
initialCapacity = concurrencyLevel; // as estimated threads
long size = (long)(1.0 + (long)initialCapacity / loadFactor);
int cap = (size >= (long)MAXIMUM_CAPACITY) ?
MAXIMUM_CAPACITY : tableSizeFor((int)size);
this.sizeCtl = cap;
}
值的增删改查操作
值的存储过程
先看一下代码:
static final int TREEIFY_THRESHOLD = 8;
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode()); //获取hash值
int binCount = 0;
for (Node<K,V>[] tab = table;;) {//如果初始化,则通过循环保证数据插入
Node<K,V> f; int n, i, fh;
if (tab == null || (n = tab.length) == 0)//如果存储数据的Node数组为空,初始化数组
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {//当hash定位为空时,则通过CAS插入数据
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
else if ((fh = f.hash) == MOVED)//Node数组进行扩容,原数组的数据进行转移
tab = helpTransfer(tab, f);
else {
V oldVal = null;
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {//如果hash相同,并且不是红黑树节点时
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {//如果是链表的节点会一直循环
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {//如果节点的key相同,直接替换
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {//如果key不相同,则形成单向链表
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
else if (f instanceof TreeBin) {//判断节点是否是红黑树
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {//如果是红黑树,保存进数据返回红黑树的替换节点,如果是新插入节点则返回null
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)//如果链表长度超过8,则把链表变成红黑树
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}
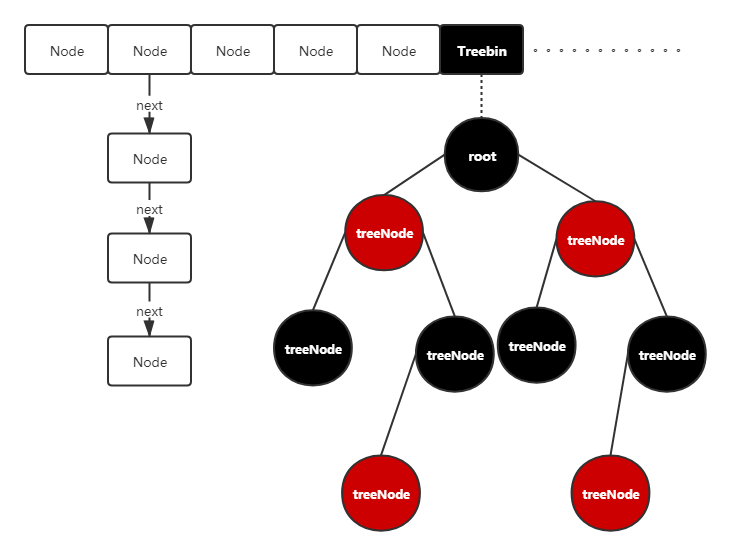
执行逻辑:如下图所示

红黑树的插入,查找,删除操作:
可以查看我的另一篇博客,这个是根据ConcurrentHashMap中红黑树的代码进行分析的。
博客地址:https://www.cnblogs.com/perferect/p/13569671.html
ConcurrentHashMap的数据存储结构:
经过上面的代码,我们可以分析出来,ConcurrentHashMap的数据结构是,数组+链表+红黑树的结构。
-
当链表节点个数超过8个时,才能判断是否要生成红黑树
-
当Node数组长度超过64,链表才能生成红黑树,否则重新resizeNode数组
值的查找
public V get(Object key) {
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
int h = spread(key.hashCode());
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {
if ((eh = e.hash) == h) {//如果在数组中key相等,返回查找值
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
else if (eh < 0)//查找红黑树中的节点
return (p = e.find(h, key)) != null ? p.val : null;
while ((e = e.next) != null) {//查找链表中对应的值
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
}
值的删除操作
先看一下代码:
- 逻辑和插入节点有点类似,看一下代码就能理解
public V remove(Object key) {
return replaceNode(key, null, null);
}
final V replaceNode(Object key, V value, Object cv) {
int hash = spread(key.hashCode());//获取hash
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
if (tab == null || (n = tab.length) == 0 ||
(f = tabAt(tab, i = (n - 1) & hash)) == null)//如果Node数组长度为0,或者hash节点为空,直接结束
break;
else if ((fh = f.hash) == MOVED)//如果Node数组在扩容中先进行扩容
tab = helpTransfer(tab, f);
else {
V oldVal = null;
boolean validated = false;
synchronized (f) {
if (tabAt(tab, i) == f) {//hash节点没变
if (fh >= 0) {//是数组或链表结构时
validated = true;
for (Node<K,V> e = f, pred = null;;) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {// key值相同时
V ev = e.val;
if (cv == null || cv == ev ||
(ev != null && cv.equals(ev))) {
oldVal = ev;
if (value != null)
e.val = value;
else if (pred != null)//逐个遍历e开头的链表
pred.next = e.next;
else
setTabAt(tab, i, e.next);//替换链表e,为e的next,如果为数组的话,next为null
}
break;
}
pred = e;
if ((e = e.next) == null)//如果是链表结构,移动节点
break;
}
}
else if (f instanceof TreeBin) {//如果是红黑树
validated = true;
TreeBin<K,V> t = (TreeBin<K,V>)f;
TreeNode<K,V> r, p;
if ((r = t.root) != null &&
(p = r.findTreeNode(hash, key, null)) != null) {//判断红黑树是否存在并且有这个节点
V pv = p.val;
if (cv == null || cv == pv ||
(pv != null && cv.equals(pv))) {
oldVal = pv;
if (value != null)
p.val = value;
else if (t.removeTreeNode(p))//移除红黑树中的节点
setTabAt(tab, i, untreeify(t.first));
}
}
}
}
}
if (validated) {
if (oldVal != null) {
if (value == null)
addCount(-1L, -1);
return oldVal;
}
break;
}
}
}
return null;
}