线程的锁
1.几个概念
讲起线程的锁,先要了解几个概念:什么是并行?什么是并发?什么是同步?什么是异步?
并发:是指系统具有处理多个任务(动作)的能力
并行:是指系统具有 同时 处理多个任务(动作)的能力,所以并行是并发的子集
同步:当进程执行到一个IO(比如等待外部数据)的时候,需要等待就是同步
异步:当进程执行到一个IO(比如等待外部数据)的时候,不需要等待,直到接收到数据成功后再返回来执行,就是异步
2.python的GIL
In CPython, the global interpreter lock, or GIL, is a mutex that prevents multiple native threads from executing Python bytecodes at once. This lock is necessary mainly because CPython’s memory management is not thread-safe. (However, since the GIL exists, other features have grown to depend on the guarantees that it enforces.)
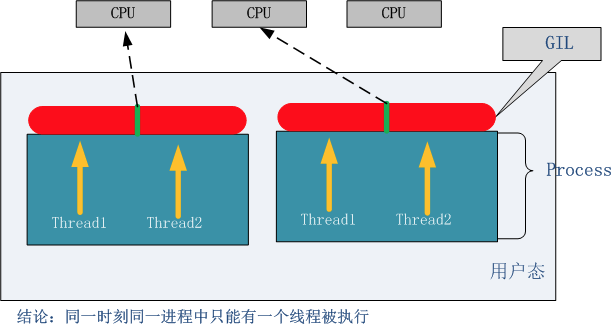
上面的核心意思就是,无论你启多少个线程,你有多少个cpu, Python在执行的时候会淡定的在同一时刻只允许一个线程运行
大部分人使用的python解释器都是c写的,也叫Cpython,在解释器中python的开发者“Guido叔”就在解释器里面加了一道锁,就是GIL,什么意思呢?我们从例子开始讲解:


def add(): sum=0 for i in range(10000000): sum+=i print("sum",sum) def mul(): sum2=1 for i in range(1,100000): sum2*=i print("sum2",sum2) import threading,time start=time.time() t1=threading.Thread(target=add) t2=threading.Thread(target=mul) l=[] l.append(t1) l.append(t2) for t in l: t.start() for t in l: t.join() # add() # mul() print("cost time %s"%(time.time()-start))
运行结果是:
sum 49999995000000
sum2 太长了
cost time 8.665002822875977
换成串行的方式来运行一下:
sum 49999995000000
sum2 太长了
cost time 8.955007314682007
从结果我们发现,多线程和直接串行运行耗时差不多,而且如果你用的是2.7的解释器(我的是3.7),甚至串行还会比多线程快,但是从第二篇的例子可以知道多线程确实能缩短运行时间提高效率的,咋这里就不行,这是为什么呢?就是因为python的GIL!再看看上面的那句话,无论你启多少个线程,你有多少个cpu, Python在执行的时候会淡定的在同一时刻只允许一个线程运行。至于GIL是好还是不好,各有各的看法,引入的目的就是为了实现不同线程对共享资源访问的互斥,才引入了GIL。
这时我们可以知道,一个CPU在执行多线程的时候,是并发且异步的,上面已经讲过概念了,就像下面这个图一样,CPU不停的在我们写的三个线程之间来回切换,切换的情况有两种,一种是遇到类的IO,一种就是自然的时间轮询(CPU会自动切换,周期是纳秒级别的,所及感觉不到)。按道理像t1和t2这样互相切换会比直接一个个的给CPU处理要慢,但是经过python解释器的其他处理,才会出现现在这个结果。
那么为什么第二篇的例子里面,确实线程节约了时间呢?我们可以把任务分成两种,一种是:IO密集型,一种是:计算密集型,我们可以把sleep直接看成是IO,这样就可以解释清楚了。遇到sleep的时候,就切换到其他线程处理,然后等sleep结束,再返回继续处理这个线程。所以得出一个结论:
对于IO密集型的任务:python的多线程是有意义的
对于计算密集型的任务:就不推荐python多线程了
那么对于计算密集型的任务没有办法解决呢?肯定是有的,一个是你可以用其他语言代替(感觉会被打),还有一个是多进程,虽然消耗比线程大,但开十几个的话,不是很明显,后面会讲到。当然还有其他方法,这里就不多讲了。
3.同步锁
我们先看一个例子,运行之后看看会有什么问题:
import threading import time def sub(): global num temp=num time.sleep(0.001) num=temp-1 num=100 l=[] for i in range(100): t=threading.Thread(target=sub) t.start() l.append(t) for t in l: t.join() print (num)
我运行了3次(结果分别是:82、87、84),每次结果都不一样,但是我目的是想让100减一百次1,最终答案应该是0,联想到上面讲的CPU在不停的切换,这里应该出了问题,可以这样推想:如果要减100次,让一百个朋友依次传递下去,最后结果肯定是0,这也就是串行的方式来做。现在用多线程的方式,情况就是一百个朋友竞争着从我这里拿数据num,第一个人拿到了,但是遇到了sleep,就切换了另一个人,此时拿到的还是100,再次遇到sleep,换一个人拿到的还是100,所以如果sleep的时间足够大(比如1s),那么最后得到的结果应该是99,那么问题来了,这该如何是好?
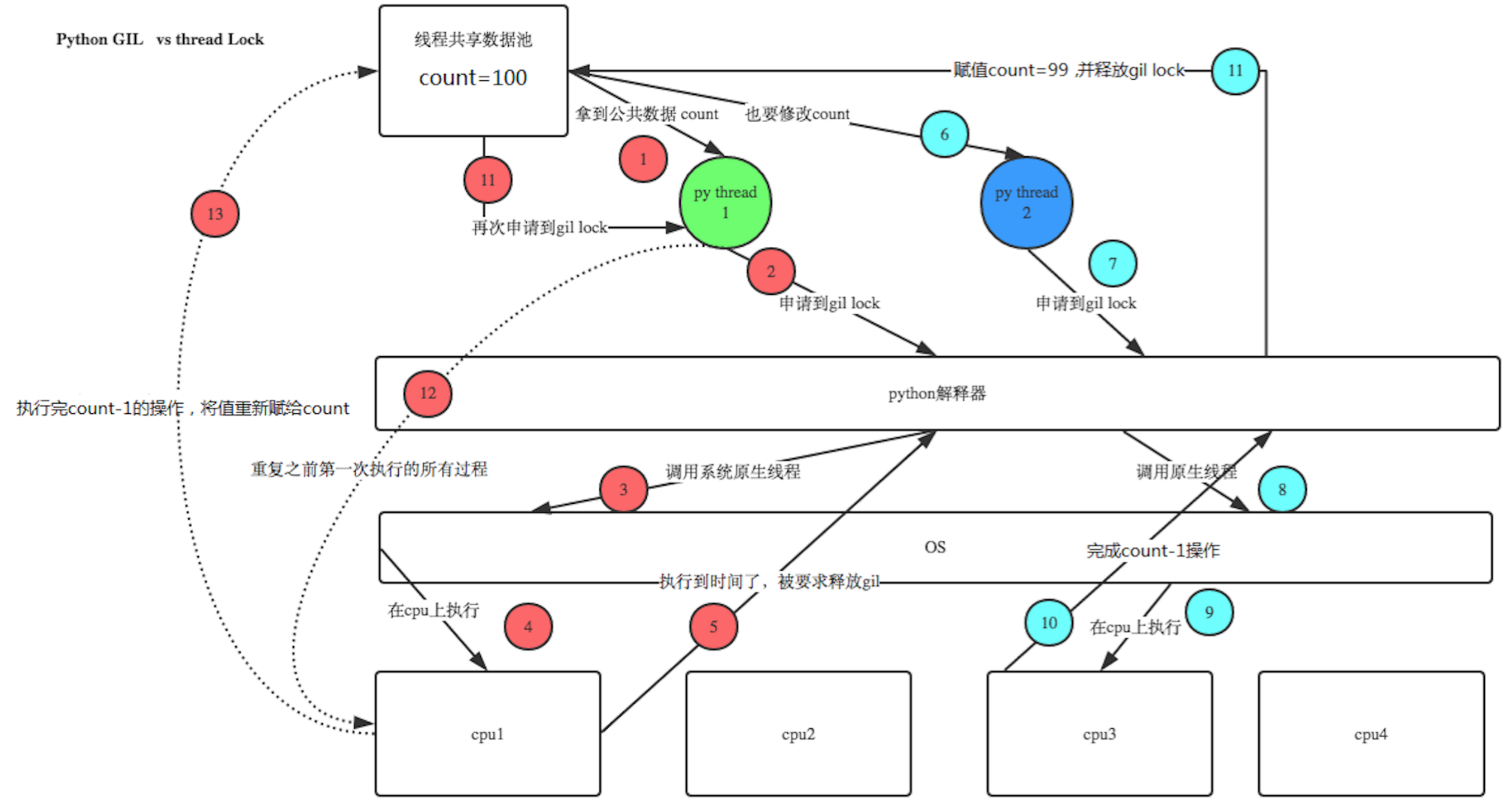
多个线程都在同时操作同一个共享资源,所以造成了资源破坏,怎么办呢?(join会造成串行,失去所线程的意义)
这个时候,我们希望的是将sleep和上下两步捆绑在一起,这样就不会IO切换了,通过同步锁可以解决这种问题,同步锁,顾名思义就是一把锁嘛,把一些东西锁起来
lock=threading.Lock()这就造好一把锁了,然后开始吧:
import threading import time def sub(): global num # num-=1 # print ("ok") lock.acquire() temp=num time.sleep(0.001) num=temp-1 lock.release() num=100 l=[] lock=threading.Lock() for i in range(100): t=threading.Thread(target=sub) t.start() l.append(t) for t in l: t.join() print (num)
现在怎么运行,结果都是0,大功告成!
4.线程死锁和递归锁
在线程间共享多个资源的时候,如果两个线程分别占有一部分资源并且同时等待对方的资源,就会造成死锁,因为系统判断这部分资源都正在使用,所有这两个线程在无外力作用下将一直等待下去。下面是一个死锁的例子:
import threading,time class myThread(threading.Thread): def doA(self): lockA.acquire() print(self.name,"gotlockA",time.ctime()) time.sleep(3) lockB.acquire() print(self.name,"gotlockB",time.ctime()) lockB.release() lockA.release() def doB(self): lockB.acquire() print(self.name,"gotlockB",time.ctime()) time.sleep(2) lockA.acquire() print(self.name,"gotlockA",time.ctime()) lockA.release() lockB.release() def run(self): self.doA() self.doB() if __name__=="__main__": lockA=threading.Lock() lockB=threading.Lock() threads=[] for i in range(5): threads.append(myThread()) for t in threads: t.start() for t in threads: t.join() print('ending...')
运行结果:
Thread-1 gotlockA Fri Apr 12 10:42:16 2019 Thread-1 gotlockB Fri Apr 12 10:42:19 2019 Thread-1Thread-2 gotlockBgotlockA Fri Apr 12 10:42:19 2019Fri Apr 12 10:42:19 2019
补充知识点1:self.name可以拿到这个线程的默认名字,就是Thread-1和Thread-2。现在我们发现程序不会停止了,一直卡在这里,这个时候,就像两个孩子在争执,我手里拿了你的东西,你手里拿了我的东西,谁也不想先拿出来交换,这就死锁了,这种情况怎么办呢?用递归锁:
现在我全部换成一把锁,叫递归锁:
import threading import time class MyThread(threading.Thread): def actionA(self): r_lcok.acquire() #count=1 print(self.name,"gotA",time.ctime()) time.sleep(2) r_lcok.acquire() #count=2 print(self.name, "gotB", time.ctime()) time.sleep(1) r_lcok.release() #count=1 r_lcok.release() #count=0 def actionB(self): r_lcok.acquire() print(self.name, "gotB", time.ctime()) time.sleep(2) r_lcok.acquire() print(self.name, "gotA", time.ctime()) time.sleep(1) r_lcok.release() r_lcok.release() def run(self): self.actionA() self.actionB() if __name__ == '__main__': # A=threading.Lock() # B=threading.Lock() r_lcok=threading.RLock() L=[] for i in range(5): t=MyThread() t.start() L.append(t) for i in L: i.join() print("ending....")
现在就可以运行完整了:
Thread-1 gotA Fri Apr 12 10:47:46 2019 Thread-1 gotB Fri Apr 12 10:47:48 2019 Thread-2 gotA Fri Apr 12 10:47:49 2019 Thread-2 gotB Fri Apr 12 10:47:51 2019 Thread-2 gotB Fri Apr 12 10:47:52 2019 Thread-2 gotA Fri Apr 12 10:47:54 2019 Thread-4 gotA Fri Apr 12 10:47:55 2019 Thread-4 gotB Fri Apr 12 10:47:57 2019 Thread-5 gotA Fri Apr 12 10:47:58 2019 Thread-5 gotB Fri Apr 12 10:48:00 2019 Thread-1 gotB Fri Apr 12 10:48:01 2019 Thread-1 gotA Fri Apr 12 10:48:03 2019 Thread-3 gotA Fri Apr 12 10:48:04 2019 Thread-3 gotB Fri Apr 12 10:48:06 2019 Thread-3 gotB Fri Apr 12 10:48:07 2019 Thread-3 gotA Fri Apr 12 10:48:09 2019 Thread-5 gotB Fri Apr 12 10:48:10 2019 Thread-5 gotA Fri Apr 12 10:48:12 2019 Thread-4 gotB Fri Apr 12 10:48:13 2019 Thread-4 gotA Fri Apr 12 10:48:15 2019 ending....
这个递归锁的原理也很简单,就是通过一个计数器,看当前有几个人在用这把锁,为了支持在同一线程中多次请求同一资源,python提供了“可重入锁”:threading.RLock。RLock内部维护着一个Lock和一个counter变量,counter记录了acquire的次数,从而使得资源可以被多次acquire。直到一个线程所有的acquire都被release,其他的线程才能获得资源。不过这种情况比较少见,了解一下就好。
在递归函数中的应用:
import threading n = 2 max_n = 10 x = 0 lock = threading.RLock() def countup(m): global x if m > 0: lock.acquire() x += 1 countup(m - 1) lock.release() print ('%s: %s ' % (threading.currentThread().getName(), x)) else: return for i in range(n): t = threading.Thread(target=countup, args=(max_n,)) t.start()
在线程中比较常用的就是这两把锁,当然还有其他锁,比如Condition等,这里就过多讲解了,下面要讲的是信号量、同步对象、队列等知识点。