概述
作用
编译原理是介绍如何将高级程序设计语言变换成计算机硬件所能识别的机器语言,以便计算机进行处理。
学习方法
1. 认真听课,认真理解书中的基本概念、基于原理与基本算法
2. 弄懂书中的例题与习题
3. 在看书时或理解例题时,一定要画出相应的细节变化过程,通过画图来加深理解
4. 在理解的基础上记忆
5. 理论结合实践
第一章 引论
1.1
- 程序设计语言
- 高级语言
- 汇编语言
- 机器语言
- 程序语言的转换
- 翻译
- 定义:是指能把某种语言的源程序,在不改变语义的条件下,转换成另一种语言程序,即目标语言程序。
- 实现手段
- 编译
- (对高级语言整体处理)专指由高级语言转换为低级语言。
- 解释
- 接受某高级语言的一个语言输入,进行解释并控制计算机执行,马上得到这句的执行结果,然后再接受下一句。
- 编译的转换过程
- 两阶段转换:编译 --> 运行
- 编译时(直接转成机器语言): 源程序 --> 编译程序 --> 目标代码(如: a.exe)
- 运行时:初始数据 --> 运行子程序目标代码(如: a.exe) --> 计算结果(如: 打印某句话)
- 三阶段转换:编译 --> 汇编 --> 运行
- 编译时(转换成汇编语言): 源程序 --> 编译程序 -->汇编语言
- 汇编时:汇编语言 --> 汇编程序 --> 目标代码
- 运行时:初始数据 --> 运行子程序目标代码(如: a.exe) --> 计算结果(如: 打印某句话)
- 注意: 这里的目标代码可能是a.exe 或者 a.o或者a.obj, a.o或者a.obj还要经过链接才能生成最终的可执行程序。
- 解释
- 以源程序作为输入,不产生目标程序,一边解释一边执行
- 优点:直观易懂,结构简单,易于实现人机对话
- 缺点:效率低(由于不产生目标程序(是机器码),没法直接执行)
1.2 编译程序概述
- 自然语言的翻译
- 识别出句子中的一个个单词
- 分析句子的语法结构
- 根据句子的含义进行初步翻译
- 对译文进行修饰
- 写出最后译文
- 编译程序的工作
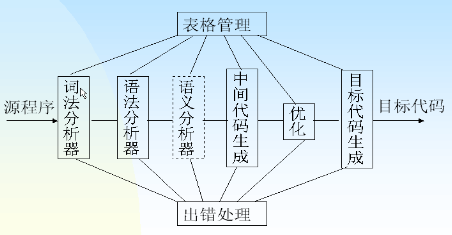
- 词法分析: 分析源程序中的词写的对不对
- 语法分析: 什么句子,判断 or 循环 or 赋值
- 语义分析和中间代码生成
- 优化:效率提高,空间和时间
- 目标代码生成
- 词法分析
- 任务
- 输入源程序,对构成源程序的字符串进行扫描和分解,识别出一个个的单词
- 单词
- 是高级语言中有实在意义的最小语法单位,它由字符构成。
- 词法分析按照词法规则,识别出正确的单词,转换成统一规格,备用。
- 转换
- 对基本字(保留字)、运算符、界限符的转换
- 标识符的转换
- 常数的转换
- 转换完成后的格式:(类号、内码)
- 描述词法规则的有效工具是正规式和有限自动机
- 正规式:用于帮助确定定义的单词是否符合程序语言的规范
- 有限自动机:正规式利用它实现对识别出的单词跟规范进行比较
- 语法分析
- 任务
- 在词法分析的基础上,根据语言的语法规则,把单词符号组成各类的语法单位:短语、字句、语句、过程、程序。
- 语法规则
- 语法的规则,又称为文法;规定单词如何构成短语、语句、过程和程序。
- 语法规则的表示
- BNF: A::=B|C,其中“::=”表示 “定义为”,
- 如:<句子>::=<主语><谓语><宾语>, <主>::=<定><名>
- 赋值语句的语法规则,用A表示赋值语句
- A::=V=E
- E::=T|E+T
- T::=F|T*F
- F::=V|(E)|C
- V::=标识符
- C::=常数
- 方法
- 推导(derive)和归约(reduce)
- 推导
- 最左推导、最右推导
- 对 x=a+b*50的推导,看他是不是赋值语句(使用最右推导,每次替换最右边的大写符号):
- A==>V=E ==> V=E+T ==> V=E+T*F ==> V+E+T*C ==> V+E+T*50
- ==>V=E+F*50 ==> V=E+V*50 ==> V=E+b*50 ==> V=T+b*50
- ==>V=F+b*50 ==> V=a+b*50
- ==> x=a+b*50
- 归约 (是推导的逆过程)
- 最右归约、最左归约
- 最右推导的逆过程是最左归约 (将上面的最右推导过程倒着看就是最左归约)
- 最左推导的逆过程是最右归约 (将下面的最左推导过程倒着看就是最右归约)
- 对 x=a+b*50采用最右归约:
- A==>V=E ==> x=E ==> x=E+T ==> x=T+T ==> x=F+T ==> x=V+T
- ==>x=a+T ==> x=a+T*F ==> x=a+F*F ==> x=a+V*F
- ==>x=a+b*F ==> x=a+b*C
- ==> x=a+b*50
- 再如,一个出错的C语句: y=c+)d*(x+b
- 推导如下: A ==> V=E ==> V=E+T ==> V=E+F ==> V=E+V ==> V=E=b
- ==> V=T+b ==> V=T*F+b ==> V=T*V+b ==> V=T*x+b
- 到这里,就推不下去了,所以这不是一个赋值语句
- 上面的这种方法,计算机中使用树来实现
- 语法分析过程也可以用一颗倒着的树来表示,这棵树叫做语法树,如对于x=a+b*50的语法树如下图所示:
-

- 可以看到,叶子节点都是标识符、运算符和常量
- 在看一个错误的:y=c+)d*(x+b的语法树,如下图所示:
-
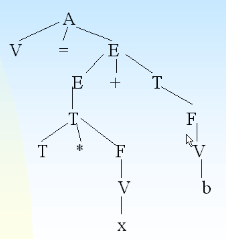
- 图中,T无法再往下推了,计算机就知道错了。
- 中间代码生成
- 任务
- 对语法分析识别出的各类语法范畴,分析其含义,进行和初步翻译,产生介于源代码和目标代码之间的一种代码。
- 语法范畴:短语、表达式、语句、过程等等
- 分为两个阶段工作
- 对每种语法范畴进行静态语义检查 (有些语句,虽然语法没问题,但是没有意义,这就是语义检查)
- 若语义正确,就进行中间代码的翻译
- 中间代码的形式
- 四元式、三元式、逆波兰式
- 四元式:有四项内容组成的句子
- 三元式
- 逆波兰式
- 例如将x=a+b*50变成中间代码,如下图所示:
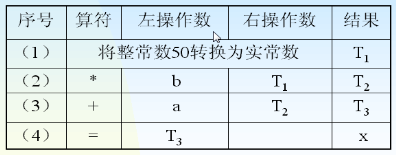
- 其中,b和a都是float类型。这是一个四元式,由算符、左操作数、右操作数和结果组成,存放在中间代码表中。
- 再由中间代码转换成汇编就比较容易了。
- 优化
- 任务
- 对前面产生的中间代码进行加工变换,以期在最后阶段能产生更为高效的中间代码
- 原则:等价变换
- 主要方面
- 公共子表达式的提取
- 如对于 x=(a+b)*c+(a+b)*d,其中(a+b)只需要计算一次,这时就需要提取公共子表达式
- 合并已知量
- 如c=a+b; ...... d=a+b; 其间a和b的值没有发生过改变,那么,就没有比要重新计算a+b,同时,d都可以没必要存在。
- 删除无用语句
- 如a=a+c,然后其他地方根本都没有用到a,那么就可以删除变量a
- 注释
- 循环优化等
- 循环内都是必须的
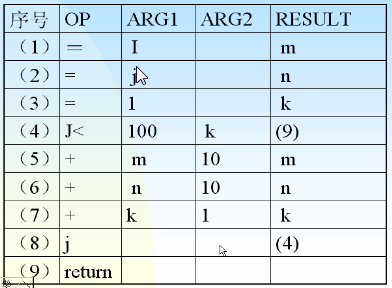
- 例如: 将下面的语句转换成中间代码
-
for(k =1; k <=100; k++){m = j +10* k;n = j +10* k;}
效率: 做了200次加法和200次乘法中间代码如下所示: 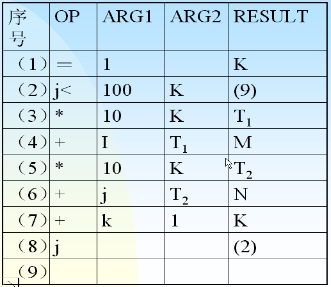
- j 表示 jump
- 其中第3句和第5句重复
- 同时i和j的值始终没有变,m和n每次递增10,k每次递增1
- 下面是优化后的结果:
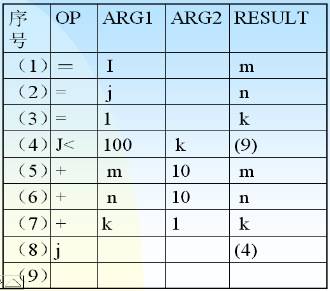
-
- 优化后的结果:
m=in=jk=110:if(k <=100){m = m +10;n = n +10;k++;goto 10;}
- 效率: 做了200次加法
- 目标代码生成
- 任务
- 把经过优化的中间代码转化成特定机器上的低级语言代码
- 目标代码的形式
- 绝对指令代码:可立即执行的目标代码,如二进制可执行程序
- 汇编指令代码:汇编语言程序,需要通过汇编程序汇编后才能运行
- 可重定位指令代码:先将各目标模块连接起来,确定变量、常数在主存中的位置,装入主存后才能成为可以运行的绝对指令代码。如生成的obj文件
- 表格与表格管理
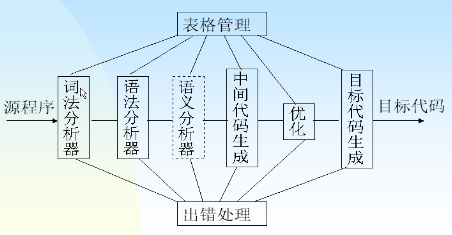
- 表格作用
- 用来记录源程序的各种信息以及编译过程中的各种状况
- 与编译阶前三阶段有关的表格有(即编译的前三个阶段才会产生表格):
- 符号表
- 用来登记源程序中的常量名、变量名、数组名、过程名等,记录它们的性质、定义和引用情况。
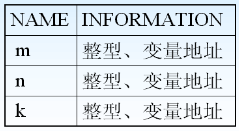
- 用的时候才登记
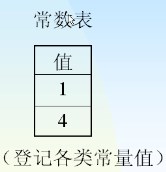
- 常数表
- 每一种类型的常数存放一张表
- 标号表
- 如上面程序中的标号10,

- 表示执行标号10后面的四元式
- 如标号表是在词法分析时建立的,然后再后面中间代码生成过程中去维护
- 分程序入口表
- 作用:登记过程的层号,分程序符号表入口等。(用于表示程序是由若干个过程来构成的,每个过程的从哪开始执行)

- 中间代码表等
- 出错处理
- 任务
- 如果源程序有错误,编译程序应设法发现错误,并报告给用户。
- 完成:由专门的出错处理程序来完成
- 错误类型
- 语法错误
- 在词法分析和语法分析阶段检测出来
- 语义错误 (如:逻辑错误)
- 一般在语义分析阶段检测 (比较难以发现)
- 如:使用没有初始化的变量导致死循环,作为分母的变量的值为0等等
- 逻辑错误在编译阶段是不处理的
- 遍
- 指对源程序或者源程序的中间结果从头到尾扫描一次,并做有关的加工处理,生成新的中间结果或者目标代码。
- 一遍扫描
- 如下图,并不是按照上面的五步顺序进行的
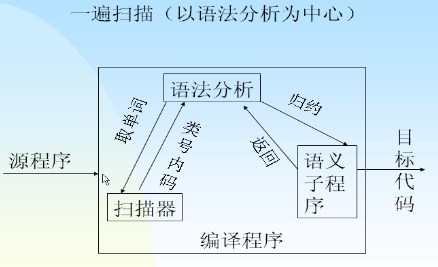
- 注:遍跟阶段(上面的五个过程)的含义毫无关系。有可能一个阶段有多次扫描,也可能一次扫描多个阶段。
- 多遍扫描
- 优点:节省内存空间,提高目标代码质量,使编译的逻辑结构清晰。
- 每次扫描分析上一次产生的表格,不需要所有的表格都驻留在内存中
- 每次扫描有各自的
- 缺点:编译时间较长
- 注:在内存许可的情况下,还是遍数尽量少些为好。
1.3 编译程序生成
- 直接用机器语言编写编译程序
- 用汇编语言编写编译程序
- 注:编译程序核心部分常用汇编语言编写
- 用高级语言编写编译程序
- 注:这是普遍采用的方法
- 自编译
- 编译工具
- LEX(词法分析,用于生成词法分析程序)与YACC(用于自动产生LALR分析表)
- 移植 (同种语言的编译程序在不同类型的机器之间移植)
1.4 编译程序构造
- 在某机器上为某种语言构造编译程序要掌握以下三方面:
- 源语言
- 目标语言
- 编译方法
本章小结
- 掌握编译程序与高级程序设计语言的关系
- 掌握编译分为哪几个阶段
- 了解各个阶段完成的主要功能和采用的主要方法