1. JVM的概述
JVM描述
Java 虚拟机有自己完善的硬件架构,如处理器、堆栈等,还具有相应的指令系统。Java虚拟机本质上就是一个程序,当它在命令行上启动的时候,就开始执行保存在某字节码文件中的指令。Java 语言的可移植性正是建立在 Java 虚拟机的基础上。任何平台只要装有针对于该平台的 Java 虚拟机,字节码文件(.class)就可以在该平台上运行。这就是“一次编译,多次运行”。Java 虚拟机不仅是一种跨平台的软件,而且是一种新的网络计算平台。该平台包括许多相关的技术,如符合开放接口标准的各种 API、优化技术等。Java 技术使同一种应用可以运行在不同的平台上。Java 平台可分为两部分,即 Java 虚拟机(Java virtual machine,JVM)和 Java API 类库。
JVM跨平台性
Java 程序先通过编译器编译成字节码文件以后(源程序:.java,字节码文件:.class),在放置到 Java 虚拟机平台上运行,这样做隔离了与操作系统的直接操作,相同的字节码文件(二进制文件)可以在不同操作系统平台上的 Java 虚拟机上面运行,在此基础之上真正做到“一次编译,多次运行”。
JVM语言无关性
随着 Java7 的发布,Java 虚拟机的设计者们通过 JSR-292 规范基本实现在 Java 虚拟机平台上运行非 Java 语言编写的程序。Java 虚拟机根本不关心运行在其内部的程序到底是使用何种编程语言编写,它只关心“字节码文件”,也就是说 Java 虚拟机拥有语言无关性,并不会单纯的终生与 Java 绑定,只要其他语言的编译结果符合并满足 Java 虚拟机的内部指令集,符号表以及其他辅助信息,他就是一个有效的字节码文件,就能够被虚拟机所识别并装载运行
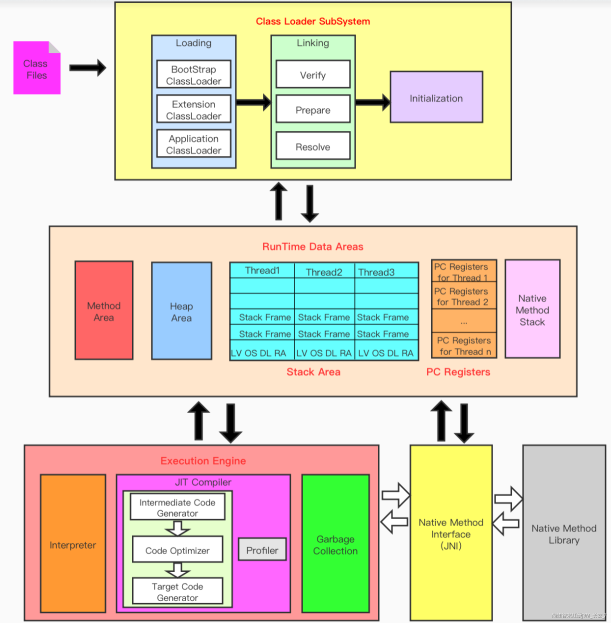
2. JVM整体结构
-
第一层为类加载器子系统,主要的作用是将 class 文件进行初步校验和解析;
-
第二层为运行时数据区,这是 JVM 的核心部分,主要由方法区、堆、程序计数器、本地方法栈和虚拟机栈组成。
-
第三层是执行引擎和本地方法接口,执行引擎就是将高级语言化作适应平台操作系统的二进制语言进行运行。
3. Java代码执行流程
Java 代码的执行流程也分为三个层次(如下图所示):
- 第一层次-编译层:
- 将 Java 源代码通过 Java 编译器编译成字节码文件;
- 第二层次-虚拟机层:
- 将字节码文件加载到 JVM 运行时数据区;
- 第三层次-操作系统层:
- JVM 执行引擎与操作系统交互,将字节码文件编译到相应 的操作系统上运行。

4. JVM架构模型
基于栈
优点
- 设计和实现简单,适用于资源受限的系统
- 避开了寄存器的分配难题:使用零地址指令方式分配
- 指令流中大部分都是零地址指令,执行过程依赖操作栈,指令集更小,编译器容易实现
- 8位字节码,所以说指令集更小,但是完成一项操作花费的指令相对多。
- 不需要硬件支持,可移植性更好,更好实现跨平台
缺点
- 性能下降,实现同样的功能需要更多的指令,毕竟还要入栈出栈等操作
指令
地址、操作数
- 零地址只有操作数
- 基于栈式的,因为是操作栈顶的元素,所以不需要地址
- 一地址有一个地址,一个操作数
- 二地址有两个地址,一个操作数
基于寄存器
优点
- 性能优秀,执行更高效
- 花费更少的指令去完成一项操作
缺点
- 指令集架构完全依赖硬件,可移植性差
举例
- 典型应用是X86的二进制指令集,比如传统的PC以及安卓的Davlik虚拟机:16位字节码
- 大部分情况下,指令集往往以一地址指令,二地址指令和三地址指令为主。
javap 查看字节码
- -v输出附加信息
- -l输出行号和本地变量表
- -p显示所有类和成员
- -c对代码进行反汇编
5. JVM生命周期
虚拟机的启动
- 通过引导类加载器bootstrap class loader创建一个初始类来完成的,这个类是由虚拟机的具体实现指定的。
虚拟机的执行
- 执行一个所谓的Java程序的时候,真正执行的是一个叫Java虚拟机的进程
虚拟机的关闭
- 程序正常执行结束
- 执行过程遇到异常或错误而异常终止
- 操作系统错误导致Java虚拟机进程终止
- Runtime类或System类的exit方法、runtime类的halt方法,并且Java安全管理器允许这次exit或halt操作
- halt停止、停下、阻止
- exit方法源码:static native void halt0(int status)
- JNI(Java Native Interface)规范描述了用JNI Invocation API来加载或卸载Java虚拟机时,Java虚拟机退出的情况
6.JVM内存结构
6.1 程序计数器
作用
用于保存JVM中下一条所要执行的指令的地址
特点
- 线程私有
- CPU会为每个线程分配时间片,当当前线程的时间片使用完以后,CPU就会去执行另一个线程中的代码
- 程序计数器是每个线程所私有的,当另一个线程的时间片用完,又返回来执行当前线程的代码时,通过程序计数器可以知道应该执行哪一句指令
- 不会存在内存溢出
6.2 虚拟机栈
定义
- 每个线程运行需要的内存空间,称为虚拟机栈
- 每个栈由多个栈帧组成,对应着每次调用方法时所占用的内存
- 每个线程只能有一个活动栈帧,对应着当前正在执行的方法
栈帧:比如我们main方法中有a,b两个方法依次执行。此时我们虚拟机栈中自下而上有三个栈桢对应着三个方法,最底下的就是main方法的栈桢,因为main首先执行,然后就是a方法 b方法,当运行结束后,b方法首先结束,那么b方法对应的栈桢就会首先弹出去,然后再弹出a栈桢,最后就是main栈桢弹出
问题辨析
- 垃圾回收是否涉及栈内存?
- 不需要。因为虚拟机栈中是由一个个栈帧组成的,在方法执行完毕后,对应的栈帧就会被弹出栈。所以无需通过垃圾回收机制去回收内存。
- 栈内存的分配越大越好吗?
- 不是。因为物理内存是一定的,栈内存越大,可以支持更多的递归调用,但是可执行的线程数就会越少。
- 方法内的局部变量是否是线程安全的?
- 如果方法内局部变量没有逃离方法的作用范围,则是线程安全的
- 如果如果局部变量引用了对象,并逃离了方法的作用范围,则需要考虑线程安全问题
内存溢出
Java.lang.stackOverflowError 栈内存溢出
发生原因
- 虚拟机栈中,栈帧过多(无限递归)
- 每个栈帧所占用过大
诊断CPU占用过高
- Linux环境下运行某些程序的时候,可能导致CPU的占用过高,这时需要定位占用CPU过高的线程
- top命令,查看是哪个进程占用CPU过高
- ps H -eo pid, tid(线程id), %cpu | grep 刚才通过top查到的进程号 通过ps命令进一步查看是哪个线程占用CPU过高
- jstack 进程id 通过查看进程中的线程的nid,刚才通过ps命令看到的tid来对比定位,注意jstack查找出的线程id是16进制的,需要转换
6.3 本地方法栈
一些带有native关键字的方法就是需要JAVA去调用本地的C或者C++方法,因为JAVA有时候没法直接和操作系统底层交互,所以需要用到本地方法
synchronized
当你点进synchronized源码的时候会看到前面有个修饰符 native synchronized如果你想深入看源码,你会发现你在idea层次你是看不到更底层的东西了,这是因为native关键字表示的是本地方法,而本地方法的实现不是在java层面完成的,你所谓能看到的源码其实都是java层面的东西,当你调用synchronized时候其实jvm会帮你调用c++写的syn方法。
start0
给你举个例子吧,比如我们线程中常用的start方法,当你点进去后会看到,其实在进行一系列判断后,最终调用的是start0方法。
private native void start0();
这个start0方法就是native修饰的本地方法,当调用这个方法的时候,其实jvm会调用系统级别的指令,比如pthread_create等
6.4 堆
定义
通过new关键字创建的对象都会被放在堆内存
特点
- 所有线程共享,堆内存中的对象都需要考虑线程安全问题
- 有垃圾回收机制
堆内存溢出
java.lang.OutofMemoryError :java heap space. 堆内存溢出
堆内存诊断
jps
jmap
jconsole
jvirsalvm
6.5 方法区
结构
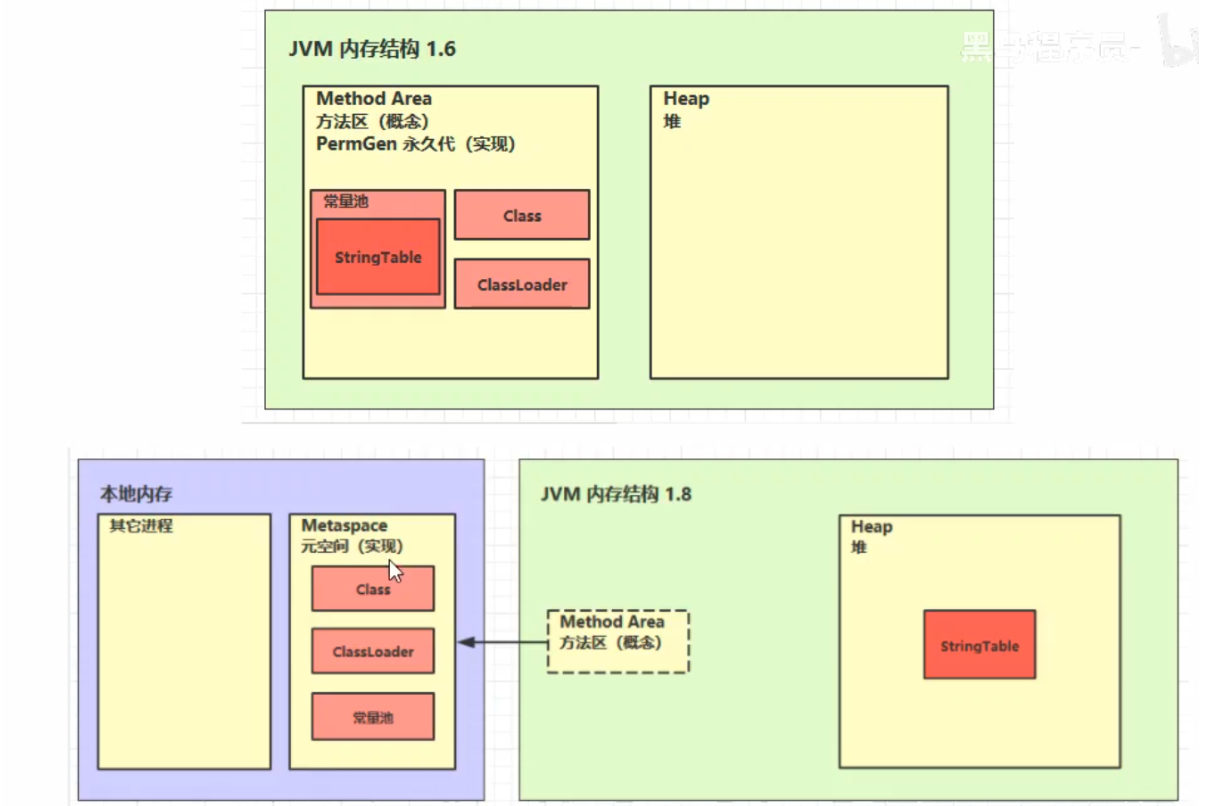
内存溢出
- 1.8以前会导致永久代内存溢出
- 1.8以后会导致元空间内存溢出
常量池
二进制字节码的组成:类的基本信息、常量池、类的方法定义(包含了虚拟机指令)
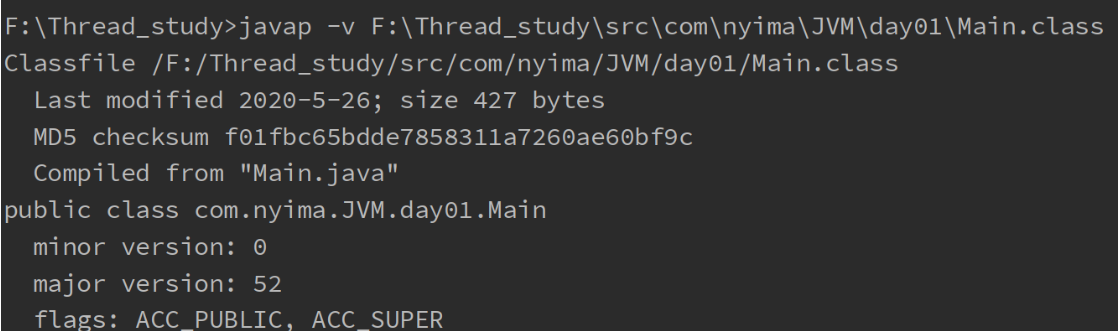
通过反编译来查看类的信息
-
获得对应类的.class文件
-
在JDK对应的bin目录下运行cmd,也可以在IDEA控制台输入
-
输入 javac 对应类的绝对路径
javac Main.javaCopy输入完成后,对应的目录下就会出现类的.class文件
-
-
在控制台输入 javap -v 类的绝对路径
javap -v Main.classCopy -
然后能在控制台看到反编译以后类的信息了
-
类的基本信息
-
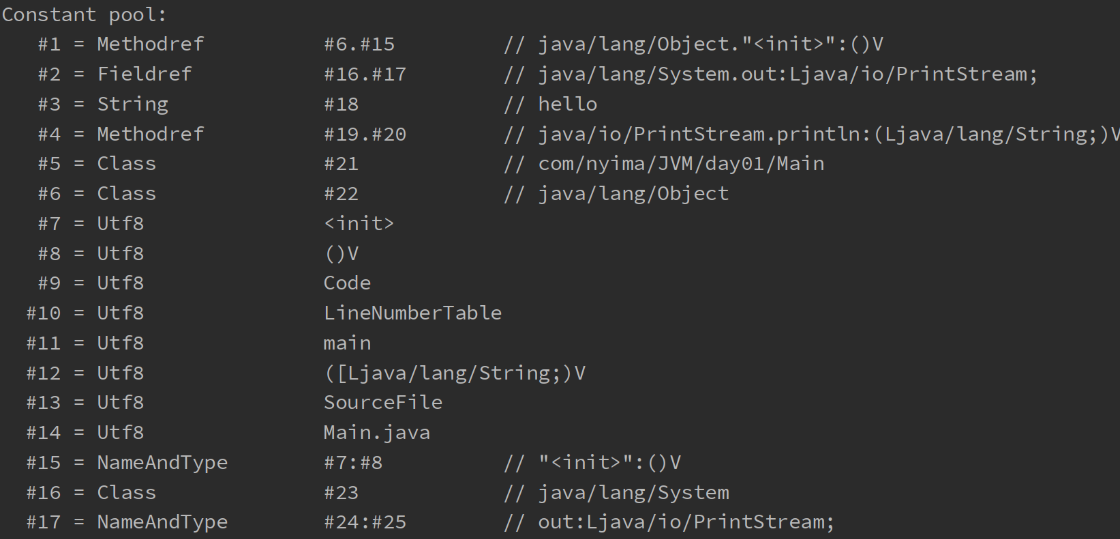
常量池
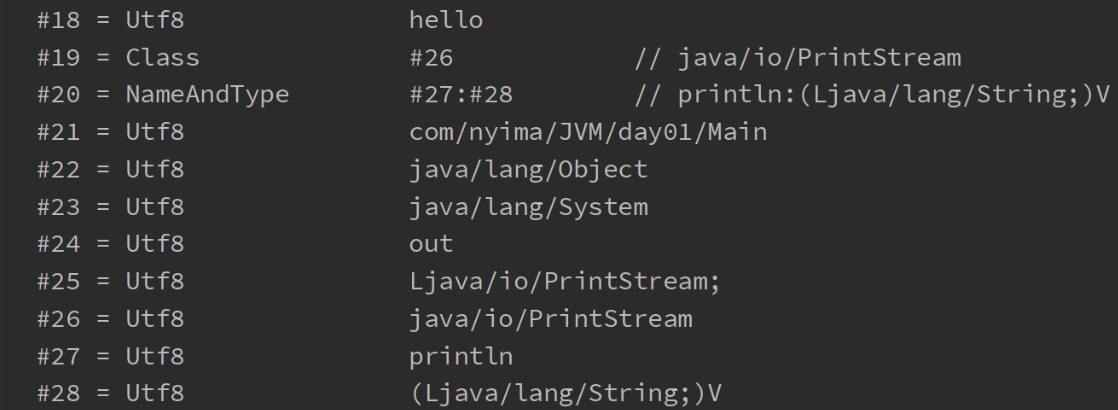
-
虚拟机中执行编译的方法(框内的是真正编译执行的内容,#号的内容需要在常量池中查找)
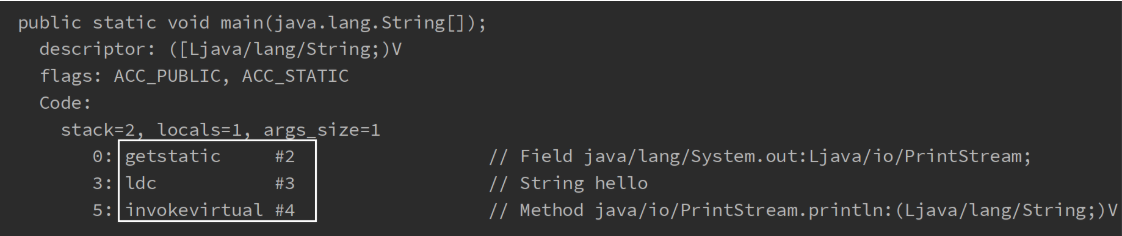
-
运行时常量池
- 常量池
- 就是一张表(如上图中的constant pool),虚拟机指令根据这张常量表找到要执行的类名、方法名、参数类型、字面量信息
- 运行时常量池
- 常量池是*.class文件中的,当该类被加载以后,它的常量池信息就会放入运行时常量池,并把里面的符号地址变为真实地址
常量池与串池的关系
串池StringTable
特征
- 常量池中的字符串仅是符号,只有在被用到时才会转化为对象
- 利用串池的机制,来避免重复创建字符串对象
- 字符串变量拼接的原理是StringBuilder
- 字符串常量拼接的原理是编译器优化
- 可以使用intern方法,主动将串池中还没有的字符串对象放入串池中
- 注意:无论是串池还是堆里面的字符串,都是对象
用来放字符串对象且里面的元素不重复
public class StringTableStudy {
public static void main(String[] args) {
String a = "a";
String b = "b";
String ab = "ab";
}
}Copy
常量池中的信息,都会被加载到运行时常量池中,但这是a b ab 仅是常量池中的符号,还没有成为java字符串
0: ldc #2 // String a
2: astore_1
3: ldc #3 // String b
5: astore_2
6: ldc #4 // String ab
8: astore_3
9: returnCopy
当执行到 ldc #2 时,会把符号 a 变为 “a” 字符串对象,并放入串池中(hashtable结构 不可扩容)
当执行到 ldc #3 时,会把符号 b 变为 “b” 字符串对象,并放入串池中
当执行到 ldc #4 时,会把符号 ab 变为 “ab” 字符串对象,并放入串池中
最终StringTable [“a”, “b”, “ab”]
注意:字符串对象的创建都是懒惰的,只有当运行到那一行字符串且在串池中不存在的时候(如 ldc #2)时,该字符串才会被创建并放入串池中。
使用拼接字符串变量对象创建字符串的过程
public class StringTableStudy {
public static void main(String[] args) {
String a = "a";
String b = "b";
String ab = "ab";
//拼接字符串对象来创建新的字符串
String ab2 = a+b;
}
}Copy
反编译后的结果
Code:
stack=2, locals=5, args_size=1
0: ldc #2 // String a
2: astore_1
3: ldc #3 // String b
5: astore_2
6: ldc #4 // String ab
8: astore_3
9: new #5 // class java/lang/StringBuilder
12: dup
13: invokespecial #6 // Method java/lang/StringBuilder."<init>":()V
16: aload_1
17: invokevirtual #7 // Method java/lang/StringBuilder.append:(Ljava/lang/String
;)Ljava/lang/StringBuilder;
20: aload_2
21: invokevirtual #7 // Method java/lang/StringBuilder.append:(Ljava/lang/String
;)Ljava/lang/StringBuilder;
24: invokevirtual #8 // Method java/lang/StringBuilder.toString:()Ljava/lang/Str
ing;
27: astore 4
29: returnCopy
通过拼接的方式来创建字符串的过程是:StringBuilder().append(“a”).append(“b”).toString()
最后的toString方法的返回值是一个新的字符串,但字符串的值和拼接的字符串一致,但是两个不同的字符串,一个存在于串池之中,一个存在于堆内存之中
String ab = "ab";
String ab2 = a+b;
//结果为false,因为ab是存在于串池之中,ab2是由StringBuffer的toString方法所返回的一个对象,存在于堆内存之中
System.out.println(ab == ab2);Copy
使用拼接字符串常量对象的方法创建字符串
public class StringTableStudy {
public static void main(String[] args) {
String a = "a";
String b = "b";
String ab = "ab";
String ab2 = a+b;
//使用拼接字符串的方法创建字符串
String ab3 = "a" + "b";
}
}Copy
反编译后的结果
Code: stack=2, locals=6, args_size=1 0: ldc #2 // String a 2: astore_1 3: ldc #3 // String b 5: astore_2 6: ldc #4 // String ab 8: astore_3 9: new #5 // class java/lang/StringBuilder 12: dup 13: invokespecial #6 // Method java/lang/StringBuilder."<init>":()V 16: aload_1 17: invokevirtual #7 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder; 20: aload_2 21: invokevirtual #7 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder; 24: invokevirtual #8 // Method java/lang/StringBuilder.toString:()Ljava/lang/String; 27: astore 4 //ab3初始化时直接从串池中获取字符串 29: ldc #4 // String ab 31: astore 5 33: returnCopy
- 使用拼接字符串常量的方法来创建新的字符串时,因为内容是常量,javac在编译期会进行优化,结果已在编译期确定为ab,而创建ab的时候已经在串池中放入了“ab”,所以ab3直接从串池中获取值,所以进行的操作和 ab = “ab” 一致。
- 使用拼接字符串变量的方法来创建新的字符串时,因为内容是变量,只能在运行期确定它的值,所以需要使用StringBuilder来创建
intern方法 1.8
调用字符串对象的intern方法,会将该字符串对象尝试放入到串池中
- 如果串池中没有该字符串对象,则放入成功
- 如果有该字符串对象,则放入失败
无论放入是否成功,都会返回串池中的字符串对象
注意:此时如果调用intern方法成功,堆内存与串池中的字符串对象是同一个对象;如果失败,则不是同一个对象
例1
public class Main { public static void main(String[] args) { //"a" "b" 被放入串池中,str则存在于堆内存之中 String str = new String("a") + new String("b"); //调用str的intern方法,这时串池中没有"ab",则会将该字符串对象放入到串池中,此时堆内存与串池中的"ab"是同一个对象 String st2 = str.intern(); //给str3赋值,因为此时串池中已有"ab",则直接将串池中的内容返回 String str3 = "ab"; //因为堆内存与串池中的"ab"是同一个对象,所以以下两条语句打印的都为true System.out.println(str == st2); System.out.println(str == str3); }}Copy
例2
public class Main { public static void main(String[] args) { //此处创建字符串对象"ab",因为串池中还没有"ab",所以将其放入串池中 String str3 = "ab"; //"a" "b" 被放入串池中,str则存在于堆内存之中 String str = new String("a") + new String("b"); //此时因为在创建str3时,"ab"已存在与串池中,所以放入失败,但是会返回串池中的"ab" String str2 = str.intern(); //false System.out.println(str == str2); //false System.out.println(str == str3); //true System.out.println(str2 == str3); }}Copy
intern方法 1.6
调用字符串对象的intern方法,会将该字符串对象尝试放入到串池中
- 如果串池中没有该字符串对象,会将该字符串对象复制一份,再放入到串池中
- 如果有该字符串对象,则放入失败
无论放入是否成功,都会返回串池中的字符串对象
注意:此时无论调用intern方法成功与否,串池中的字符串对象和堆内存中的字符串对象都不是同一个对象
StringTable 垃圾回收
StringTable在内存紧张时,会发生垃圾回收
StringTable调优
-
因为StringTable是由HashTable实现的,所以可以适当增加HashTable桶的个数,来减少字符串放入串池所需要的时间
-XX:StringTableSize=xxxxCopy -
考虑是否需要将字符串对象入池
可以通过intern方法减少重复入池