目录
k8s网络CNI之flannel
k8s网络模型
- Container to Container
- Pod to Pod
- Service to Pod
- external to Service
常见CNI项目
- Flannel,提供叠加网络,基于linux TUN/TAP,使用UDP封装IP报
文来创建叠加网络,并借助etcd维护网络分配情况 - Calico,基于BGP的三层网络,支持网络策略实现网络的访问控制。在每台机器上运行一个vRouter,利用内核转发数据包,并借助iptables实现防火墙等功能
- Canal,由Flannel和Calico联合发布的一个统一网络插件,支持网络策略
- Weave Net,多主机容器的网络方案,支持去中心化的控制平面,数据平面上,通过UDP封装实现L2 Overlay
- Contiv,思科方案,直接提供多租户网络,支持L2(VLAN)、L3(BGP)、Overlay(VXLAN)
- OpenContrail,Juniper开源
- kube-router,K8s网络一体化解决方案,可取代kube-proxy实现基于ipvs的Service,支持网络策略、完美兼容BGP的高级特性
重点了解Flannel, Calico, Canal, kube-router
Flannel插件
| 首先,flannel会利用Kubernetes API或者etcd用于存储整个集群的网络配置,其中最主要的内容为设置集群的网络地址空间,例如,设定整个集群内所有容器的IP都取自网段“10.1.0.0/16”。接着,flannel会在每个主机中运行flanneld作为agent,它会为所在主机从集群的网络地址空间中,获取一个小的网段subnet,本主机内所有容器的IP地址都将从中分配。然后,flanneld再将本主机获取的subnet以及用于主机间通信的Public IP,同样通过kubernetes API或者etcd存储起来。最后,flannel利用各种backend mechanism,例如udp,vxlan等等,跨主机转发容器间的网络流量,完成容器间的跨主机通信。 大家都知道Kubernetes是通过CNI标准对接网络插件的,但是当你去看Flannel(coreos/flannel)的代码时,并没有发现它实现了CNI的接口。如果你玩过其他CNI插件,你会知道还有一个二进制文件用来供kubele调用,并且会调用后端的网络插件。对于Flannel(coreos/flannel)来说,这个二进制文件是什么呢? 这个二进制文件就对应宿主机的/etc/cni/net.d/flannel |
flannel原理说明
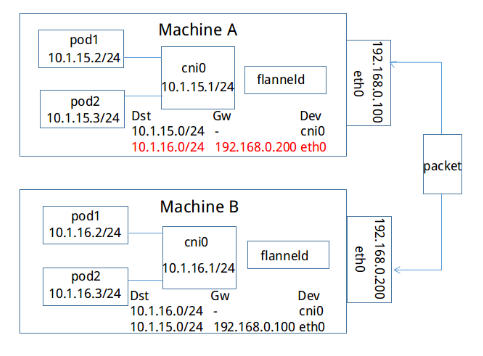
现在,我们来简单看一下,如果上方Machine A中IP地址为10.1.15.2/24的容器要与下方Machine B中IP地址为10.1.16.2/24的容器进行通信,封包是如何进行转发的。从上文可知,每个主机的flanneld会将自己与所获取subnet的关联信息存入etcd中,例如,subnet 10.1.15.0/24所在主机可通过IP 192.168.0.100访问,subnet 10.1.16.0/24可通过IP 192.168.0.200访问。反之,每台主机上的flanneld通过监听etcd,也能够知道其他的subnet与哪些主机相关联。如下图,Machine A上的flanneld通过监听etcd已经知道subnet 10.1.16.0/24所在的主机可以通过Public 192.168.0.200访问,而且熟悉docker桥接模式的同学肯定知道,目的地址为10.1.16.2/24的封包一旦到达Machine B,就能通过cni0网桥转发到相应的pod,从而达到跨宿主机通信的目的。
因此,flanneld只要想办法将封包从Machine A转发到Machine B就OK了,而上文中的backend就是用于完成这一任务。不过,达到这个目的的方法是多种多样的,所以我们也就有了很多种backend。在这里我们举例介绍的是最简单的一种方式`hostgw`:因为`Machine A和Machine B处于同一个子网内`,它们原本就能直接互相访问。因此最简单的方法是:在Machine A中的容器要访问Machine B的容器时,我们可以将Machine B看成是网关,当有封包的目的地址在subnet 10.1.16.0/24范围内时,就将其直接转发至B即可。而这通过下图中那条红色标记的路由就能完成,对于Machine B同理可得。由此,在满足仍有subnet可以分配的条件下,我们可以将上述方法扩展到任意数目位于同一子网内的主机。而任意主机如果想要访问主机X中subnet为S的容器,只要在本主机上添加一条目的地址为R,网关为X的路由即可。
flannel配置参数
Network,全局CIDR格式的IPv4网络,字符串格式,必选
SubnetLen,子网,默认为24位
SubnetMin,分配给节点的起始子网
SubnetMax,分配给节点的最大子网
Backend,flannel要使用的后端
flannel初始配置
[root@master bin]# cat /run/flannel/subnet.env
FLANNEL_NETWORK=10.244.0.0/16
FLANNEL_SUBNET=10.244.0.1/24
FLANNEL_MTU=1450
FLANNEL_IPMASQ=true
flannel后端实现原理
host-gw
hostgw是最简单的backend,它的原理非常简单,直接添加路由,将目的主机当做网关,直接路由原始封包。例如,我们从etcd中监听到一个EventAdded事件:subnet为10.1.15.0/24被分配给主机Public IP 192.168.0.100,hostgw要做的工作非常简单,在本主机上添加一条目的地址为10.1.15.0/24,网关地址为192.168.0.100,输出设备为上文中选择的集群间交互的网卡即可。对于EventRemoved事件,删除对应的路由即可。
VxLAN
| 当有一个EventAdded到来时,flanneld如何进行配置的,以及封包是如何在flannel网络中流动的。 |
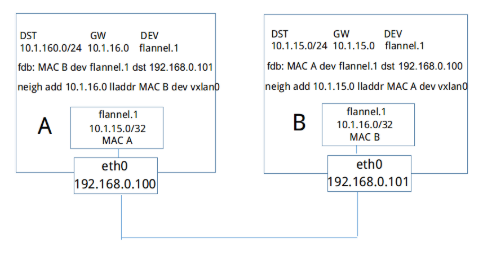
如上图所示,当主机B加入flannel网络时,和其他所有backend一样,它会将自己的subnet 10.1.16.0/24和Public IP 192.168.0.101写入etcd中,和其他backend不一样的是,它还会将vtep设备flannel.1的mac地址也写入etcd中。
之后,主机A会得到EventAdded事件,并从中获取上文中B添加至etcd的各种信息。这个时候,它会在本机上添加三条信息:
-
路由信息:所有通往目的地址10.1.16.0/24的封包都通过vtep设备flannel.1设备发出,发往的网关地址为10.1.16.0,即主机B中的flannel.1设备。
-
fdb信息:MAC地址为MAC B的封包,都将通过vxlan首先发往目的地址192.168.0.101,即主机B
-
arp信息:网关地址10.1.16.0的地址为MAC B
| 现在有一个容器网络封包要从A发往容器B,和其他backend中的场景一样,封包首先通过网桥转发到主机A中。此时通过,查找路由表,该封包应当通过设备flannel.1发往网关10.1.16.0。通过进一步查找arp表,我们知道目的地址10.1.16.0的mac地址为MAC B。到现在为止,vxlan负载部分的数据已经封装完成。由于flannel.1是vtep设备,会对通过它发出的数据进行vxlan封装(这一步是由内核完成的,相当于udp backend中的proxy),那么该vxlan封包外层的目的地址IP地址该如何获取呢?事实上,对于目的mac地址为MAC B的封包,通过查询fdb,我们就能知道目的主机的IP地址为192.168.0.101。最后,封包到达主机B的eth0,通过内核的vxlan模块解包,容器数据封包将到达vxlan设备flannel.1,封包的目的以太网地址和flannel.1的以太网地址相等,三层封包最终将进入主机B并通过路由转发达到目的容器。 |
虚拟网络数据帧添加到VxLAN首部后,封装在物理网络UDP报文中,到达目地主机后,去掉物理网络报文头部及VxLAN首部,再将报文交付给目的终端
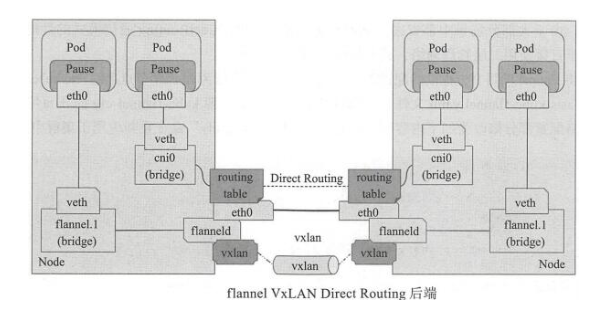
VxLAN后端使用隧道网络转发会导致一定和流量开销,VxLAN DirectRouting模式,通过添加必要的路由信息使用节点的二层网络直接发送Pod通信报文,仅在跨IP网络时,才启用隧道方式。这样,在不跨IP网络时,性能基本接近二层物理网络
| 已经创建的flannel的网络配置修改后不会生效, 只能删掉flannel, 修改yaml文件后重新创建, 所以一定要提前确定好网络配置 |
canal安装
curl https://docs.projectcalico.org/v3.9/manifests/canal.yaml -O
kubectl apply -f canal.yaml
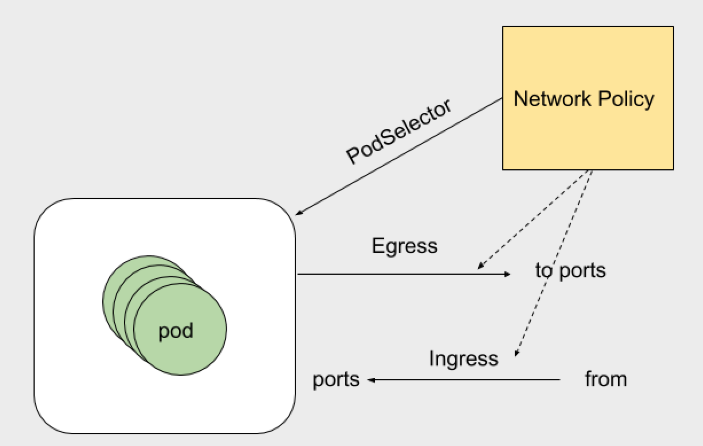
NetworkPolicy相关术语
kubectl explain networkpolicy.spec讲解:
- egress 出站流量规则 可以根据ports和to去定义规则。ports下可以指定目标端口和协议。to(目标地址):目标地址分为ip地址段、pod、namespace
- ingress 入站流量规则 可以根据ports和from。ports下可以指定目标端口和协议。from(来自那个地址可以进来):地址分为ip地址段、pod、namespace
- podSelector 定义NetworkPolicy的限制范围。直白的说就是规则应用到那个pod上。podSelector: {},留空就是定义对当前namespace下的所有pod生效。没有定义白名单的话 默认就是Deny ALL (拒绝所有)
- policyTypes 指定那个规则 那个规则生效,不指定就是默认规则。
实验
创建两个namespace
kubectl create namespace dev
kubectl create namespace prod
创建pod
apiVersion: v1
kind: Pod
metadata:
name: pod-demo
spec:
containers:
- name: myapp
image: ikubernetes/myapp:v1
管理入站流量
kubectl explain networkpolicy.spec.ingress
| NetworkPolicy属于名称空间级别 参数: from,源地址对象列表,多个项目间逻辑关系为或,若为空,表示匹配一切源地址;若至少有一个值,则仅允许列表中流量通过 ports,可被访问的端口对象列表,多个项目间为逻辑或,若为空,表示匹配Pod的所有端口;若至少有一个值,则仅允许访问指定的端口 |
拒绝所有入站流量的规则:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: deny-all-policy
spec:
podSelector: {}
policyTypes:
- Ingress
| 没有定义Ingress规则, 但是写到了policyTypes里, 就表示默认拒绝入方向访问, 没有写Egress, 表示默认允许出方向访问 |
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: allow-all-ingress
spec:
podSelector: {} # 匹配所有Pod
ingress:
- {} # 定义为空, 表示允许访问
policyTypes: ["Ingress"]
放入特定入站流量
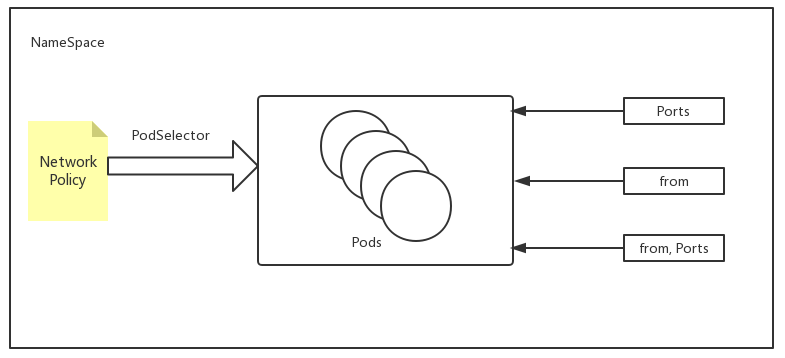
| 仅定义from将默认允许本地Pod所有端口;仅定义ports将默认允许所有源端点;同时定义from和ports时,是逻辑与关系 多个from之间是逻辑或关系 多个ports之间是逻辑或关系 from与ports间是逻辑与关系 from下ipBlock、namespaceSelector、podSelector同时使用多个时,为逻辑或关系 |
# 为pod打标签
[root@master manifests]# kubectl label pod myapp -n dev app=myapp --overwrite
pod/myapp labeled
[root@master manifests]# kubectl get pod -n dev --show-labels
NAME READY STATUS RESTARTS AGE LABELS
myapp 1/1 Running 0 29m app=myapp
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: allow-myapp-ingress
name: default
spec:
podSelector: # 该规则只在当前的namespace下,携带app: myapp标签的pod生效。限制请求的类型包括Ingress和Egress
matchLabels:
app: myapp
policyTypes: ["Ingress"]
ingress:
- from:
- ipBlock: # 网络地址块
cidr: 10.244.0.0/16 # 允许某个网段访问
except: # 排除某个网段或ip访问(只拒绝掉10.244.1.5)
- 10.244.1.5/32
- podSelector: # 携带了app: myapp标签的pod可以访问
matchLabels:
app: myapp
ports:
- protocol: TCP
port: 80
管理出站流量
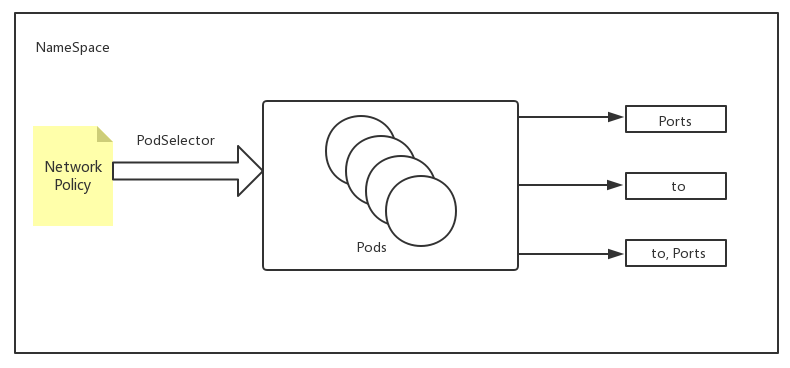
拒绝所有出站流量
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: deny-all-egress
spec:
podSelector: {}
policyTypes: ["Egress"]
放行特定的出站流量
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: allow-tomcat-egress
spec:
podSelector:
matchLabels:
app: tomcat
policyTypes: ["Egress"]
egress:
- to:
- podSelector:
matchLabels:
app: nginx
- ports:
- protocol: TCP
port: 80
- to:
- podSelector:
matchLabels:
app: mysql
ports:
- protocol: TCP
port: 3306
| 对app=tomcat的Pod,限制只能访问app=nginx的80端口和app=mysql的3306端口 |
隔离名称空间
隔离名称空间,应该放行与kube-system名称空间中Pod的通信,以实现监控和名称解析等各种管理功能
kubectl explain networkpolicy.spec.ingress.from.namespaceSelector.matchExpressions
kubectl explain networkpolicy.spec.egress.to.namespaceSelector.matchExpressions
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: namespace-deny-all
namespace: default
spec:
policyTypes: ["Ingress","Egress"]
podSelector: {}
---
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: namespace-
namespace: default
spec:
policyTypes: ["Ingress","Egress"]
podSelector: {}
ingress:
- from:
- namespaceSelector:
matchExpressions:
- key: name
operator: In
values: ["default","kube-system"]
egress:
- to:
- namespaceSelector:
matchExpressions:
- key: name
operator: In
values: ["default","kube-system"]
参考链接
https://pdf.us/2019/03/27/3129.html
https://my.oschina.net/jxcdwangtao/blog/1624486