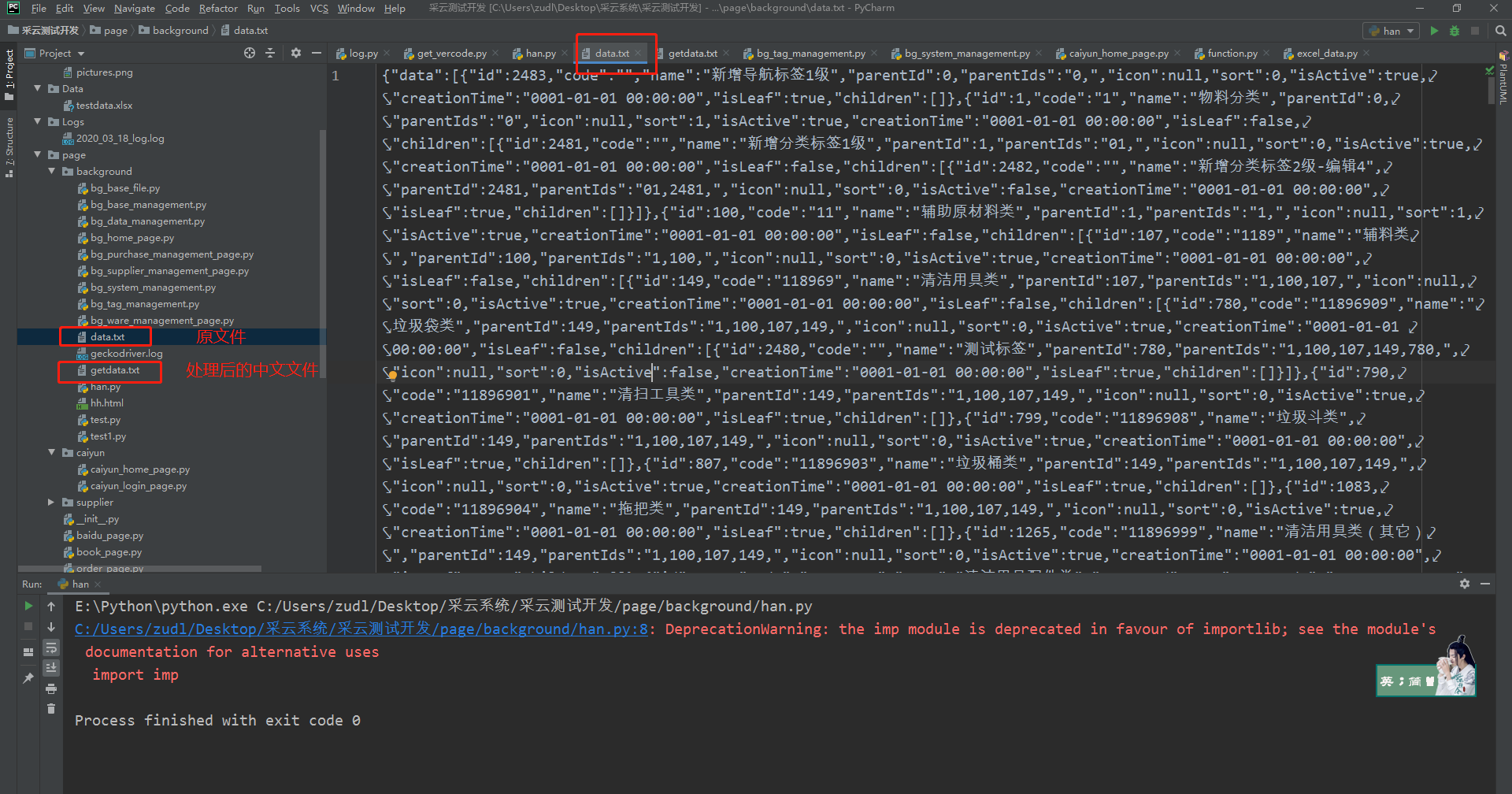
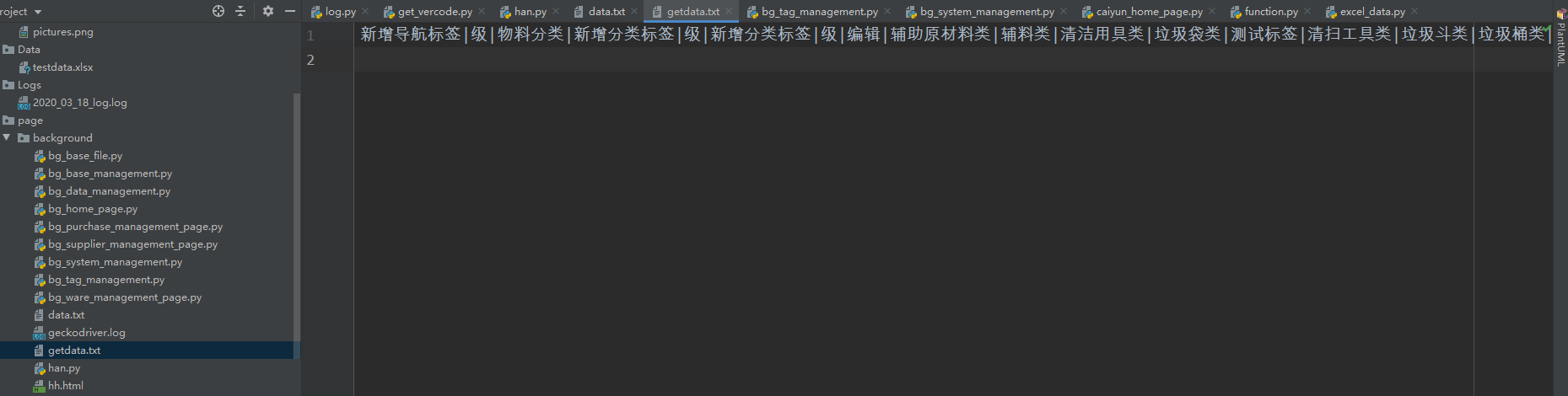
一、问题背景
在做一个接口的测试工作,想要整理出所有的分类项,结果获取到一大堆的返回信息
二、python实现
1 # coding=utf-8 2 3 import imp 4 import sys 5 import re 6 imp.reload(sys) 7 # sys.setdefaultencoding('utf-8') # 设置默认编码,只能是utf-8,下面u4e00-u9fa5要求的 8 pchinese = re.compile('([u4e00-u9fa5]+)+?') #判断是否为中文的正则表达式 9 f = open("data.txt", encoding='utf-8', errors='ignore') # 打开要提取的文件 10 fw = open("getdata.txt", "w") # 打开要写入的文件 11 for line in f.readlines(): # 循环读取要读取文件的每一行 12 m = pchinese.findall(str(line)) # 使用正则表达获取中文 13 if m: 14 str1 = '|'.join(m) # 同行的中文用竖杠区分 15 str2 = str(str1) 16 fw.write(str2) # 写入文件 17 fw.write(" ") # 不同行的要换行 18 f.close() 19 fw.close()