慢慢才意识到概率统计的重要性,当时学的时候只知道很重要,是机器学习基础啥的,但是却没有真正意识到( ╯□╰ )。我现在的理解是,统计学习可以从大数据中挖掘出规律(其实和数据挖掘还是很相关的),在科研工作和生活中都可以帮助和指导我们。生活中,我们可以通过分析数据,“透过现象看本质” (learning from data),参考大概率发生的事件,帮助我们少走一些弯路,做出正确的决策。
最开始的概率思维来自大一的近现代史老师,老师说 “为什么公司要区分985,211等学位?”,其实我当时也不是很理解,我觉得哪里都会有优秀的人,但是老师说因为985,211大概率会比较优秀,这是来自大量公司的统计(不过撇过部分公司的硬性条件,不管是哪种学位,只要自己努力去变优秀,金子一定不会被埋没的!(ง •_•)ง)。后来的概率思维来自一位哲学老师分享的案例,比如分析理科学者,学术年龄38岁是个分界线,在38岁学术产出率达到高峰;还有对诺奖得主的工作岗位分析,发现多数都有在不同机构间流动的这一特征,得出流动性与职业成功的关系。显然,我们可以借鉴这些分析结果。(废话太多,进入正题)
学统计学,R语言是必不可少的,以下参考W3Cschool的教程:https://www.w3cschool.cn/r/
这里只是简单的总结,基本部分和其他语言都差不多,学习完这些基本之后,多写程序,需要的再查。
安装:使用conda安装R及Rstudio,但是我用conda-navigator装Rstudio报错,所以直接从Rstudio官网手动安装。
执行方式:和python一样,R的执行方式有两种,命令行和脚本文件
• 命令行:直接键入R
• 脚本:创建好脚本文件.R 之后,使用命令 Rscript xxx.R
注意事项:R 不支持多行注释,单行注释用#
数据类型:并不会声明为某种数据类型,而是直接赋予对象(动态类型语言)
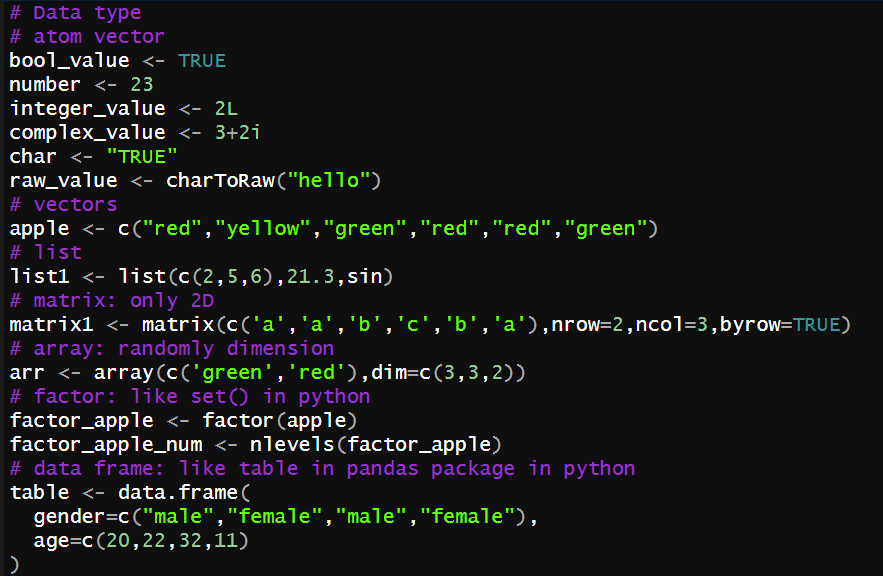
变量:
字母,数字,下划线,点;以字母或不以数字后跟的点开头
如:.2a × .ab √
变量赋值:向左 向右 等于
打印:print() 和连续打印 cat()
查找工作空间中所有可用的变量print(ls()) print(ls(pattern="var")),以.开头的变量被自动隐藏,要输出:print(ls(all.names=TRUE))
运算符:
算数运算符: + - * /(正常除法) %%(余数) %/%(整除) ^
关系运算符:> < == <= >= !=
逻辑运算符: & | ! &&(仅作用于两个向量的第一个元素) ||(仅作用于两个向量的第一个元素)
赋值运算符: 左分配:= <- <<- 右分配:-> ->>
其他: : %*%(矩阵乘以其转置) %in%(判断某一元素是否在其内)
条件循环语句:
条件:
if:
else if:
else:
switch case
循环:
repeat
while
for
break; next (like continue in python);
包相关操作:
默认只有默认的R包可用,如果需要用自定义安装的则需要显示加载
.libPaths() 获取R包库位置
library() 获取已安装的所有包
search() 获取当前加载的所有包
安装:从cran自动安装 (install.packages("xxx") )+ 手动安装(从R pkgs(https://cran.r-project.org/web/packages/available_packages_by_name.html)下载对应zip,使用命令
install.packages("E:/XML_3.98-1.3.zip", repos = NULL, type = "source")
安装)
加载包到当前环境:library("")
数据重塑
cbind()函数连接多个向量来创建数据帧(连接列组成frame)。 此外,我们可以使用rbind()函数合并两个数据帧(合并sample)。
merge() melt() cast()
函数
自定义 : Name <- function(args){}
R有大量内置函数:seq() mean() max() sum() paste()
字符串
paste(..., sep = " ", collapse = NULL) sep是分割字符串的符号 collapse是字符串之间的空格操作
format()
nchar()
tolower()toupper()
substring("",begin,end)
数据类型详细
访问向量元素:t[c(index/bool/01)]
两个向量进行操作长度不同时,较短的会循环自身补足长度
sort(data,decreasing=TRUE)inverse
listdata中的每个元素可以赋予名字:names(list)<- c("","")
列表可以通过索引或者名字访问,list[1] list$name
通过赋值操作对列表实现增删改(增删只能末尾),删除时赋值为NULL
合并列表c(list1,list2)
使用unlist将列表转换为向量
图表
R语言强大的地方之一就在于其绘图功能,这里只是简单的内置函数的示意,还有很多强大的绘图包,如ggplot2。
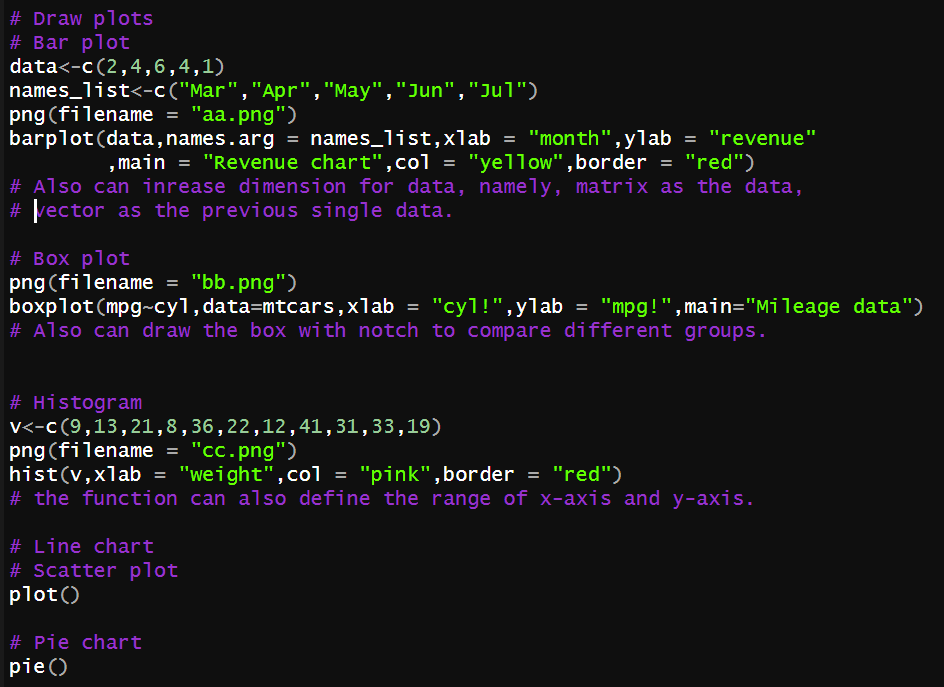
结果如下:
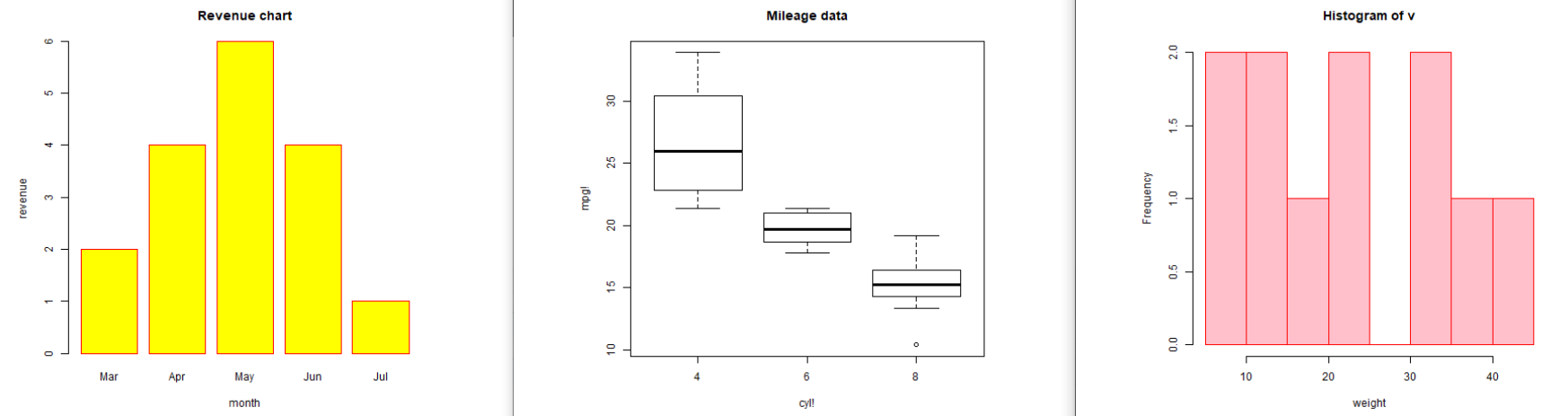
箱线图可以反应数据集中数据的分布,也可以用来比较数据集之间的数据分布;直方图可以反应连续范围数据的频数/频率情况;折线图可以反应数据中发展的趋势。学会用图可以更加清晰直观的表达含义,一图胜千言,这在学术论文写作中也是非常有必要学习的。
还有其他文件读取,统计方法等R的语法,用到再查即可。