- 索引的修复可以通过2种方式,(关于pehoenix的索引的生命周期可以参考 https://community.hortonworks.com/articles/58818/phoenix-index-lifecycle.html
- 一 手工执行修复命令
- 依赖phoenix的自动修复命令
- 自动修复
- Phoenix 对于索引状态异常的情况,按照设计会自动进行修复的,也就是autorebuild,不过发现在HDP2.2 下,不能正常修复,后台(regionserver)提示找不到schema
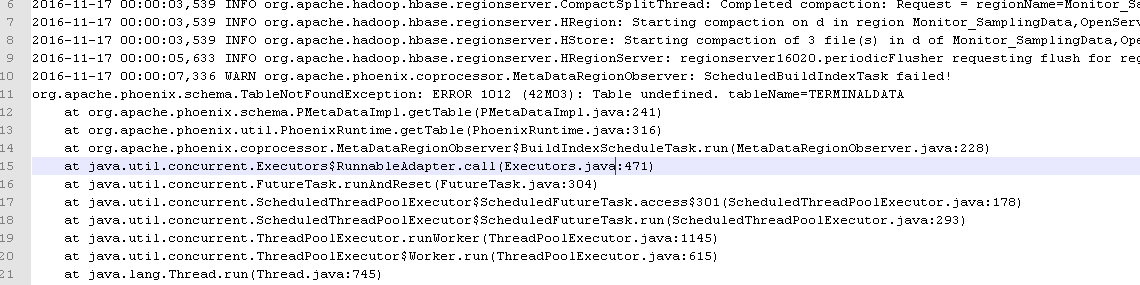
针对这个bug,社区已经反馈为HDP2.2的bug,在2.3版本已经修复.可以参考 https://community.hortonworks.com/questions/66446/phoenix-index-becom-unavaiable.html#comment-67349
- Phoenix 对于索引状态异常的情况,按照设计会自动进行修复的,也就是autorebuild,不过发现在HDP2.2 下,不能正常修复,后台(regionserver)提示找不到schema
- 手工修复
- 当数据量比较小的时候,正常的修复命令可以正常执行,但是由于数据量较大,出现了修复超时、修复错误等问题
- 当数据量较大的时候,采用修复命令的时候,比较曲折,由于各方面原因最终没有修复成功,
- 下面的一个场景为修复我们的一个数据库表原始数据800G,索引数据70个G左右,regionserver 是3台,8core 14g
- 修复流程如下
- 查看当前索引的状态
;
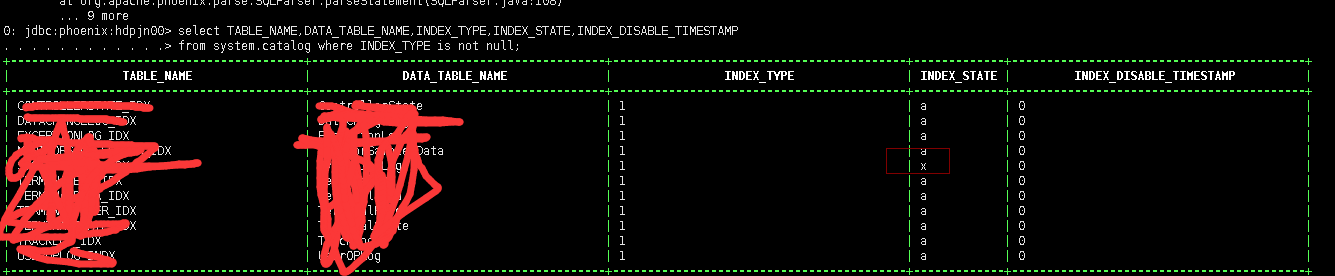
验证sql 是否走索引 发现没有走
.修复索引
-
-
-
- ALTER INDEX IF EXISTS SysActionLog_idx ON "SysActionLog" REBUIL3
-
- 执行出现超时
Error: org.apache.phoenix.exception.PhoenixIOException: Failed after attempts=36, exceptions: -
-
Wed Nov 16 11:06:26 GMT 2016, null, java.net.SocketTimeoutException: callTimeout=60000, callDuration=73626: row '' on table 'SYSACTIONLOG_IDX' at region=SYSACTIONLOG_IDX,,1463835204579.ce4eb5993504052a305c8807d6234d93., hostname=workernode2.reddog.microsoft.com,16020,1479228656092, seqNum=1438608 (state=08000,code=101)
-
- 再次查询。
此时索引的状态已经 变为正在进行修复
-
-
 修改phoenix 的执行超时(index.phoenix.querytimeout) ,后执行 再次 仍然出现错误
修改phoenix 的执行超时(index.phoenix.querytimeout) ,后执行 再次 仍然出现错误-
-
- org.apache.hadoop.hbase.UnknownScannerException: org.apache.hadoop.hbase.UnknownScannerException: Name: 5, already closed?
-
- at org.apache.hadoop.hbase.regionserver.HRegionServer.scan(HRegionServer.java:3186)
at org.apache.hadoop.hbase.ipc.RpcServer.call(RpcServer.java:2080)
at org.apache.hadoop.hbase.ipc.CallRunner.run(CallRunner.java:108)
at org.apache.hadoop.hbase.ipc.RpcExecutor.consumerLoop(RpcExecutor.java:114
at org.apache.hadoop.hbase.ipc.RpcExecutor$1.run(RpcExecutor.java:94)
at java.lang.Thread.run(Thread.java:74 -
5修改超时时间
针对上面的错误,分析regionserve的日志,发现是由于一些超时时间导致,在每个regionserver 的节点上增加如下参数 -
-
-
-
-
-
<property>
<name>hbase.client.scanner.timeout.period</name>
<value>9200000</value>
</property>
<property>
<name>hbase.rpc.timeout</name>
<value>9200000</value>
</property>
<property>
<name>hbase.regionserver.lease.period</name>
<value>9200000</value>
</property>
<property>
<name>phoenix.query.timeoutMs</name>
<value>9200000</value>
</property>
-
-
-

-
目前 怀疑 应该在HDInsight 节点下的phoenix 目录下的hbase-site.xml 增加上面的几个参数,但是原生的HDP下phoenix的目录下没有这个hbase-site.xml。 有时间进一步验证....
- 在Hdp 原生的集群执行时,也出现了超时,由于时微软的azure windows 平台上 不知HDP在window上是否有问题,同样的操作和参数配置 在测试的HDP liux集群出现了如下错误,需要进一步解决,(调整zk的时间)
-

- 未完 待续