最近在使用erlang做游戏服务器,而字符串在服务器编程中的地位是十分重要的,于是便想仔细研究下字符编码,以及erlang下的字符串处理。先从Unicode开始吧....
【Unicode】
Unicode标准确定世界绝大部分的字符编码值(code point),而对于code point的编码方式有很多种,这些编码方式称为UTF。我们需要区分开Unicode字符与Unicode编码,Unicode字符指的是Unicode标准中定义的编码值,这个值代表世界上独一无二的一个字符,而Unicode编码则是这些值在计算机中的表达方式,比如UTF-8就是Unicode的一种编码。这里我们主要谈论下Unicode编码在erlang下的处理,先谈谈以下几种编码吧...
(1)单字节编码
使用单个字节来保存字符编码,这种编码不能算是Unicode编码,因为它在Unicode标准出现前就有了,但他还是可以表示Unicode中编码小于256的符号。这部分字符集对应ISO-Latin-1字符集,在erlang中它就是latin1编码,这里的ISO-Latin-1和latin1不是同一个东东,一个是字符集,一个是编码.
(2)UTF-8
多字节编码,它使用1到4个字节来进行编码,也就是说UTF-8是变长的,使用的字节数会根据字符的编码大小而变化.它兼容按单字节编码的7bitASCII字符,因为这些字符在UTF-8中也只需要占据1个字节。当编码值大于127时UTF-8将使用多个字节来保存,并且在第一个字节里使用几个位来标注该字符是多字节的。因此UTF-8与大于127的单字节编码并不兼容,所以latin1与UTF-8并不是完全兼容的。
(3)UTF-16
它与UTF-8相似,也是多字节编码,只是它的基本单位是16位,也就是说所有Unicode字符至少占用2个字节,编码数大甚至会使用4个字节。一些系统和程序只允许UTF-16使用2个字节,因为它基本足够表达大多数字符了。当然由于基本单位大于了1个字节,UTF-16就存在大编,小编两个变种。
(4)UTF-32,UCS-4
最直接的编码方式,使用4个字节来保存字符。与UTF-16一样,存在大编,小编两个变种。
研究到这里,我产生了一个疑问,UTF-8和UTF16,32一样都是多字节编码,为什么UTF-8就不存在大编小编的变种呢?要解决这个问题,必须得明白UTF-8的具体编码方式才行,于是google...
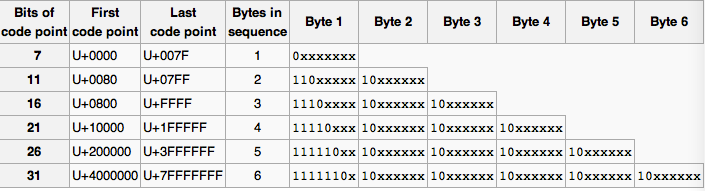
如上图所示,UTF-8在表示128以下的字符时,使用一个字节,并且最高位是0,表示该字符是单字节。当需要多字节时,首位字节的高位由一个或多个1占据,并且1后面跟随一个0,来与code point的字节位分隔,后面的字节以10开始,10后面是code point的字节位。首位字节的1的个数表示了这个字符需要的字节数,这样处理字符的程序就不要去查看后面以10开始的字节数量,便知道了该字符需要的字节数是多少。
好了,了解了UTF-8的具体编码方式了,但还是没有解决之前的那个问题,就是UTF-8为什么没有大小编的变种?仔细研究了后,发现UTF-8还有一个约定,就是编码的高字节位在首字节,后面接着的字节依次保存后面的编码字节位。这样就约定了UTF-8固定的编码字节保存方式。而UTF-16,UTF-32并没有约定自己的编码保存方式,他们依赖与编码保存的环境,所以他们需要区别大小编。
UTF-16,32在文本流的第一个字符前,使用BOM(bytes order mark)来区别大小编。以UTF-16为例,它的BOM是FEFF,如果编码方编码的是FEFF,而解码方解码得到的是FFFE,那说明大小编不一致,就需要对解码的字节进行处理。当然解码方不处理BOM,那么FEFF会被当作ZWNBSP character处理,估计就是什么都不做的意思。BOM除了用来区分大小编码外,还可以区分编码类型,比如UTF-8的BOM是EF BB BF。
【erlang字符串与Unicode处理】
了解了Unicode,接着谈谈erlang下对字符串和Unicode的处理。在erlang下,没有单独的string类型,它使用list包含一组int来表示,一个int代表一个字符编码。在R13版本之前,它使用ISO-latin-1 (ISO8859-1)字符集来编码,在R13之后扩展到Unicode。list的表示方式很容易扩展到Unicode字符集,因为它使用一个int来表示字符。但如果要将list转换成二进制类型,Unicode就会有点问题。当code point < 256 时,字符是单字节编码,erlang可以使用latin1,那么code point在内存中的表示是一个挨着一个的,这样就可以直接使用erlang:iolist_to_binary/1将list转换到二进制数据。(在erlang中会使用这种方式来处理字符串,因为list是使用一个int来表示字符串,当只需要单字节编码时,用二进制类型保存更节约空间) 但是当code point >= 256时,转换成二进制时,就需要确定Unicode的编码方式,不能直接使用erlang:iolist_to_binary/1接口,需要使用unicode:characters_to_binary/{1,2,3}来转换。默认情况下,转换时erlang使用UTF-8作为标准的Unicode编码。
-
在R16B版本之后,erlang允许使用UTF-8来对源代码编码,默认下使用latin1编码。可以通过在源代码文件前加入 %% -*- coding: utf-8 -*- 来设置编码方式。string和注释可以使用UTF-8,但函数名和atom还是使用ISO-latin-1字符集,这个有可能在R18改变。
-
二进制类型的位语法中也加入了对Unicode的处理:
<<Ch/utf8,_/binary>> = Bin1, <<Ch/utf16-little,_/binary>> = Bin2, Bin3 = <<$H/utf32-little, $e/utf32-little, $l/utf32-little, $l/utf32-little, $o/utf32-little>>, Bin4 = <<"Hello"/utf16>> 非常方便。。
-
erlang的输出函数会启发式的检测输入的list,binariy是否是可以打印的字符。默认检测的字符范围是ISO-Latin-1,也可以在启动时通过+pc指定为UTF-8。对于io(_lib):format/2函数,也可以使用~tp来被指定范围影响。
指定范围为Latin $ erl +pc latin1 Erlang R16B (erts-5.10.1) [source] [async-threads:0] [hipe] [kernel-poll:false] Eshell V5.10.1 (abort with ^G) 1> [1024]. [1024] 2> [1070,1085,1080,1082,1086,1076]. [1070,1085,1080,1082,1086,1076] 3> [229,228,246]. "åäö" 4> <<208,174,208,189,208,184,208,186,208,190,208,180>>. <<208,174,208,189,208,184,208,186,208,190,208,180>> 5> <<229/utf8,228/utf8,246/utf8>>. <<"åäö"/utf8>> 1> io:format("~tp~n",[{<<"åäö">>, <<"åäö"/utf8>>, <<208,174,208,189,208,184,208,186,208,190,208,180>>}]). {<<"åäö">>,<<"åäö"/utf8>>,<<208,174,208,189,208,184,208,186,208,190,208,180>>} 指定范围为UTF-8 $ erl +pc unicode Erlang R16B (erts-5.10.1) [source] [async-threads:0] [hipe] [kernel-poll:false] Eshell V5.10.1 (abort with ^G) 1> [1024]. "Ѐ" 2> [1070,1085,1080,1082,1086,1076]. "Юникод" 3> [229,228,246]. "åäö" 4> <<208,174,208,189,208,184,208,186,208,190,208,180>>. <<"Юникод"/utf8>> 5> <<229/utf8,228/utf8,246/utf8>>. <<"åäö"/utf8>> 1> io:format("~tp~n",[{<<"åäö">>, <<"åäö"/utf8>>, <<208,174,208,189,208,184,208,186,208,190,208,180>>}]). {<<"åäö">>,<<"åäö"/utf8>>,<<"Юникод"/utf8>>}
-
erlang shell的交互Console也可以支持Unicode和输入和输出,在windows上首先要确认是否有合适的字体,如果没有可以使用DejaVu。在Unix系统下,需要检查Console是否支持Unicode,通过echo $LANG或者$LC_CTYPE来察看,还可以通过io:getopts()来检查当前Console使用的编码。
$ LC_CTYPE=en_US.ISO-8859-1 erl Erlang R16B (erts-5.10.1) [source] [async-threads:0] [hipe] [kernel-poll:false] Eshell V5.10.1 (abort with ^G) 1> lists:keyfind(encoding, 1, io:getopts()). {encoding,latin1} 2> q(). ok $ LC_CTYPE=en_US.UTF-8 erl Erlang R16B (erts-5.10.1) [source] [async-threads:0] [hipe] [kernel-poll:false] Eshell V5.10.1 (abort with ^G) 1> lists:keyfind(encoding, 1, io:getopts()). {encoding,unicode} 2>
- 不过虽然字符串变量能够被视为Unicode进行处理,但是erlang的代码还是被限制在ISO-latin-1字符集
2> Юникод.
* 1: illegal character
-
接下来是关于erlang对文件命名不同编码的处理:
目前的操作系统,都支持Unicode编码的文件命名,但不同的操作系统对文件命名编码有不同的约定,所以erlang也有不同的处理。对于windows和macos,所有文件命名的编码都强制性要求使用Unicode,macos要求UTF-8,虽然windows使用特殊的Unicode变种,但两者效果是相同。而Unix下面并不是强制要求使用Unicode编码,只是约定而已,那么在Unix下存在有多种编码的可能性,比如说一个文件名包含的字符串code point 属于128到255之间,可以编码成ISO-lation-1也可以编码成UTF-8(128以下的code point 两者是相兼容的,具体参看前面Unicode的编码介绍)。因此在windows和macos下,Erlang VM的默认行为是工作在"Unicode file name translation mode"下面,在这个模式下,所有的文件名都会以一个Unicode的list返回,并且自动转换成合适的编码传入到底层的文件系统。在Unix下没有自动打开这个模式,默认使用ISO-Latin-1,那么如果文件名编码是使用的UTF-8,那么就会返回“raw file names”,也就是一组包含编码的整型list.(比如使用list_dir_all/1函数时)我们可以通过在VM运行时,加入+fnu来打开"Unicode file name translation mode",默认下它会使用 latin1作为文件名编码,也可以使用file:native_name_encoding/0 来返回当前文件名使用的编码。
http://www.erlang.org/doc/apps/stdlib/unicode_usage.html