上一片文章我们讲过了,B 树索引是 MySql 常用引擎(InnoDB,MyISAM)的索引。
提出问题
什么是 B 树,它有什么特性那?B+ 树与 B 树有什么区别?我们平常用的二叉搜索树的时间复杂度不是 LogN 吗?难道不够优秀吗?
解决问题
预备知识
磁盘 IO:系统读取磁盘是将磁盘的基本单位---磁盘块读取出来。磁盘读取 IO 是机械动作,时间大概为内存读取的十多万倍。所以磁盘 IO 读写速度称为索引性能的主要指标。
二叉搜索树
二叉搜索树(Binary Search Tree,BST),它的时间复杂度为 LogN。
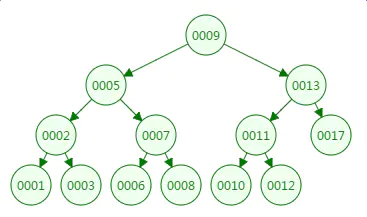
在二叉搜索树中,我们要执行搜索,最好情况是搜索 0009,也就是 BST 的根结点,只需要一次磁盘 IO。最坏情况就是树最深的底层叶子节点(深度为 N 就需要 N 次磁盘 IO)。
二叉搜索树已经很优秀了,还有没有优化的空间?我们从以下几个点来考虑。
- BST 的最坏情况怎么优化。
- 二叉搜索树是由树的深度决定的,我们能不能压缩它。
B 树
B 树,平衡多路查找树。B 树是为磁盘等存储设备设计的一种平衡查找树。B 树结构的数据可以让系统高效的找到数据所在的磁盘块。
我们以主键索引为例子。
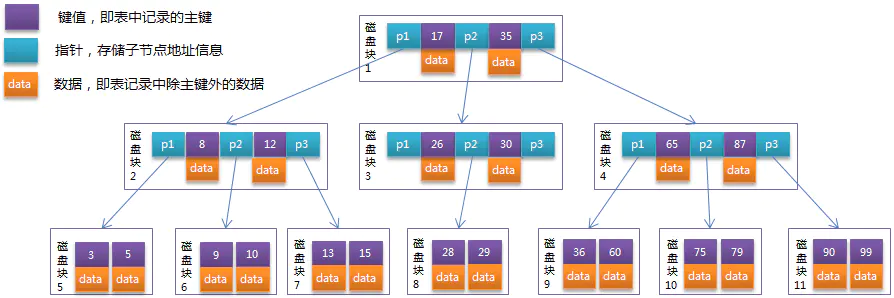
上图就是一个 B 树,紫色为 Key,黄色为 data,蓝色为指针。
相比于之前的 BST 多了在每一个磁盘页的索引比较,但是因为磁盘页已经被磁盘 IO 操作读取到了内存中。因为内存 IO 操作比磁盘 IO 操作省时很多根本不在一个数量级所以可以忽略不计,所以磁盘 IO 操作仍然是最重要的性能指标。
B 树相比于二叉搜索树压缩了深度,所以磁盘 IO 会比二叉搜索树少,能有效地提高新能,所以 B 树更适合索引。
B+ 树
B+ 树是在 B 树的基础上的一种优化,使其更适合实现外存储索引结构。InnoDB 和 MyISAM 存储引擎都是使用 B+ 树实现其索引结构。
我们说过,B 树的索引和关键自 key-data 存储在磁盘里面,然后被磁盘 IO 操作读入内存。如果这个 data 很大的话,每次家在到内存中的 key 就会减少,这会使得 B 树的深度增加,这样还是会增加磁盘 IO 查询。
为了解决这个问题,B+ 树将所有数据记录节点按照键值的大小顺序存放在同一层叶子节点上,而非叶子节点只存储 key 值信息,这样可以大大增加每个节点存储的 key 值的数量,降低 B+ 树的高度。
非叶子节点只存储键值信息,所有叶子节点之间都有一个链指针,数据记录都存储于叶子节点中。
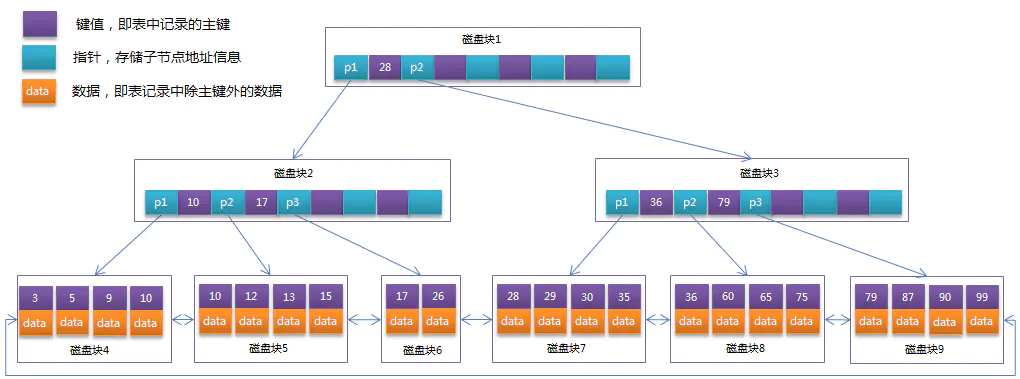
B 树与 B+ 树的区别
- B+ 树的磁盘读写更低,因为非叶子节点可以存储更多的索引 key,而 key 索引在同一层更集中,那么会降低磁盘 IO 读写次数。
- B+ 树的查询效率更稳定,任何查询都必须从根节点到叶子节点,路径是相似的,所以更稳定(最好最坏都在底层)。
- 区间访问友好性,MySQL 是关系型数据库,所以经常会按照区间来访问某个索引,B+ 树的叶子节点会按照顺序建立起链状指针,增强了区间访问性。
MySQL 为什么使用 B/B+ 树来实现索引那?
MySQL 是基于磁盘的数据库,索引是以索引文件的形式存于磁盘中的。索引的过程就是磁盘 IO 的过程,磁盘 IO 消耗比内存 IO 消耗好几个数量级,所以能有效减少磁盘 IO 的数据结构适合用来实现数据库索引。