spark任务运行原理
一:spark运行组件的介绍
如下图为分布式spark应用中的组件:
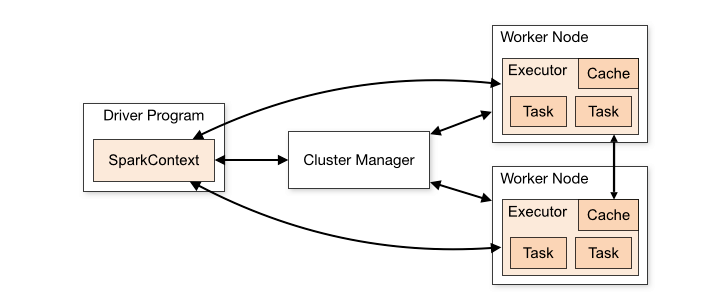
1 驱动器节点的任务:
(1)-把用户程序转化为任务(多个物理服务器执行的单元);
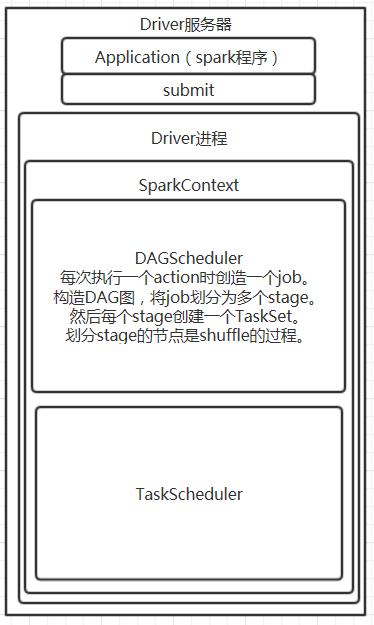
Driver进程首先构造SparkConf,接着创建SparkContext。SparkContext创建时,会构造DAGSchedule和TaskScheduler。
创建一个操作上路基上执行的有向无环图(DAG),驱动器运行时,会按照这个执行计划进行执行。有队此计划进行优化。
TaskScheduler通过启动自己的后台进程,去连接Master,向Master注册Application。
(2)-为执行节点调度任务;
2 执行器节点的任务:1-运行应用任务,并将结果返回给驱动器程序;2-提供内存式存储;
3 集群管理器的作用:集群管理器是spark可插拔式组件,不进可以使用独立集群管理器,还可以使用其他外部的管理器,例如yarn。
详细步骤:
1.用户通过spark-submit脚本提交应用;
2.spark-submit脚本启动驱动器程序,调用用户的main()方法。
3.Driver服务器构造SparkConf,进一步构造SparkContext。
sparkContext创建的同时,会构造DAGSchedule和TaskScheduler.
4.TaskScheduler启动自己后台程序,去连接Master。向Master注册Application。申请资源以启动执行器节点。
5.集群管理器(Master)收到注册后,使用自己的资源调度算法,分配计算资源。然后Worker节点启动Executor.
6. Executor启动后反向注册到TaskScheduler上去。
7. DAGScheduler会将job划分多个stage,每个stage创建一个TaskSet。划分标准,shuffle或者程序的最后一个task。
taskScheduler会把TaskSet里的没一个task提交到executor上执行。
8.驱动器程序执行用户应用中的操作。根据程序中所定义的对RDD的转化操作和行为操作,驱动器节点把工作以任务的形式发送到执行器进程。
9.任务在执行器程序中进行计算和保存结果。运行在Exector下的TaskRunner进程中运行。
10.如果驱动器程序的main()方法退出,或者调用了sparkContext.stop(),驱动器程序会终止执行器进程,并且通过集群资源管理器释放资源。
二、Spark作业基本运行原理
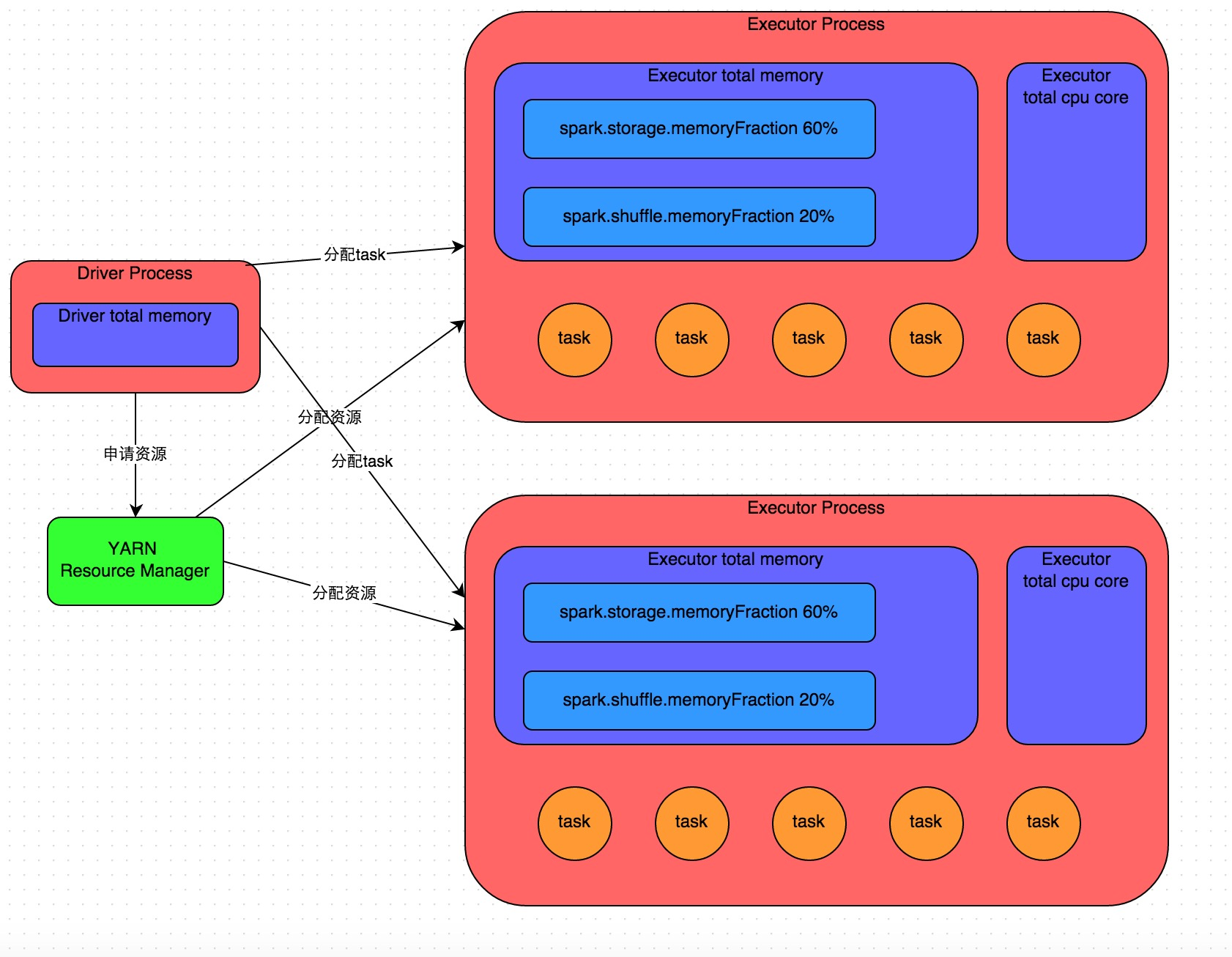
详细原理见上图。我们使用spark-submit提交一个Spark作业之后,这个作业就会启动一个对应的Driver进程。根据你使用的部署模式(deploy-mode)不同,Driver进程可能在本地启动,也可能在集群中某个工作节点上启动。Driver进程本身会根据我们设置的参数,占有一定数量的内存和CPU core。而Driver进程要做的第一件事情,就是向集群管理器(可以是Spark Standalone集群,也可以是其他的资源管理集群,美团•大众点评使用的是YARN作为资源管理集群)申请运行Spark作业需要使用的资源,这里的资源指的就是Executor进程。YARN集群管理器会根据我们为Spark作业设置的资源参数,在各个工作节点上,启动一定数量的Executor进程,每个Executor进程都占有一定数量的内存和CPU core。
在申请到了作业执行所需的资源之后,Driver进程就会开始调度和执行我们编写的作业代码了。Driver进程会将我们编写的Spark作业代码分拆为多个stage,每个stage执行一部分代码片段,并为每个stage创建一批task,然后将这些task分配到各个Executor进程中执行。task是最小的计算单元,负责执行一模一样的计算逻辑(也就是我们自己编写的某个代码片段),只是每个task处理的数据不同而已。一个stage的所有task都执行完毕之后,会在各个节点本地的磁盘文件中写入计算中间结果,然后Driver就会调度运行下一个stage。下一个stage的task的输入数据就是上一个stage输出的中间结果。如此循环往复,直到将我们自己编写的代码逻辑全部执行完,并且计算完所有的数据,得到我们想要的结果为止。
Spark是根据shuffle类算子来进行stage的划分。如果我们的代码中执行了某个shuffle类算子(比如reduceByKey、join等),那么就会在该算子处,划分出一个stage界限来。可以大致理解为,shuffle算子执行之前的代码会被划分为一个stage,shuffle算子执行以及之后的代码会被划分为下一个stage。因此一个stage刚开始执行的时候,它的每个task可能都会从上一个stage的task所在的节点,去通过网络传输拉取需要自己处理的所有key,然后对拉取到的所有相同的key使用我们自己编写的算子函数执行聚合操作(比如reduceByKey()算子接收的函数)。这个过程就是shuffle。
当我们在代码中执行了cache/persist等持久化操作时,根据我们选择的持久化级别的不同,每个task计算出来的数据也会保存到Executor进程的内存或者所在节点的磁盘文件中。
因此Executor的内存主要分为三块:第一块是让task执行我们自己编写的代码时使用,默认是占Executor总内存的20%;第二块是让task通过shuffle过程拉取了上一个stage的task的输出后,进行聚合等操作时使用,默认也是占Executor总内存的20%;第三块是让RDD持久化时使用,默认占Executor总内存的60%。
task的执行速度是跟每个Executor进程的CPU core数量有直接关系的。一个CPU core同一时间只能执行一个线程。而每个Executor进程上分配到的多个task,都是以每个task一条线程的方式,多线程并发运行的。如果CPU core数量比较充足,而且分配到的task数量比较合理,那么通常来说,可以比较快速和高效地执行完这些task线程。
以上就是Spark作业的基本运行原理的说明,大家可以结合上图来理解。理解作业基本原理,是我们进行资源参数调优的基本前提。
还有很多内容没有加上,有兴趣的请看
https://www.cnblogs.com/qingyunzong/p/8945933.html
https://www.cnblogs.com/LiCheng-/p/8151160.html 中华石杉-spark入门到精通视频
参考文献:spark快速大数据分析—7.2节