yarn多租户配置管理(CapacityScheduler)
hadoop的版本为2.7
一: 多租户实现前,只有一个default队列
二 配置文件修改
yarn-site.xml
<?xml version="1.0"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<configuration>
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value> <!--设置资源调度器-->
</property>
<property>
<name>yarn.resourcemanager.scheduler.monitor.enable</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>FoxLog17.engine.wx</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>4</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>16000</value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.FileSystemRMStateStore</value>
</property>
<property>
<name>yarn.resourcemanager.fs.state-store.uri</name>
<value>/tmp/yarn/system/rmstore</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>6192</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>1280</value>
</property>
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>607800</value>
</property>
<property>
<name>yarn.log-aggregation.retain-check-interval-seconds</name>
<value>10800</value> </property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/hdpdata/hadoop/tmp/nm-local-dirs</value>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>/hdpdata/hadoop/tmp/nm-log-dirs</value>
</property>
<property>
<name>yarn.nodemanager.log.retain-seconds</name>
<value>10800</value>
</property>
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/tmp/logs</value>
</property>
<property>
<name>yarn.nodemanager.remote-app-log-dir-suffix</name>
<value>logs</value>
</property>
<property>
<name>yarn.nodemanager.delete.debug-delay-sec</name>
<value>600</value>
</property>
<!--property>
<name>yarn.nodemanager.localizer.cache.target-size-mb</name>
<value>2048</value>
</property-->
<!--多租户配置,新增,用于队列的权限管理,和mapred-site.xml配置文件配合使用,例如不同租户不能随意kill任务,只能kill属于自己的队列任务,超级用户除外-->
<property>
<name>yarn.acl.enable</name>
<value>true</value>
</property>
<property>
<name>yarn.admin.acl</name>
<value>hadp</value>
</property>
</configuration>
mapred-site.xml
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.reduce.shuffle.parallelcopies</name> <value>10</value> </property> <!--property> <name>yarn.app.mapreduce.am.resource.mb</name> <value>1024</value> </property--> <!--property> <name>mapreduce.task.io.sort.mb</name> <value>100</value> </property--> <!--property> <name>mapreduce.task.io.sort.factor</name> <value>10</value> </property--> <property> <name>mapreduce.jobhistory.address</name> <value>FoxLog17.engine.wx:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>FoxLog17.engine.wx:19888</value> </property> <!--property> <name>mapred.child.java.opts</name> <value>-Xmx6000m</value> </property> <property> <name>mapred.map.child.java.opts</name> <value>-Xmx2000</value> </property> <property> <name>mapred.reduce.child.java.opts</name> <value>-Xmx3024m</value> </property--> <property> <name>mapreduce.map.memory.mb</name> <value>2048</value> </property> <property> <name>mapreduce.map.java.opts</name> <value>-Xmx1536M</value> </property> <property> <name>mapreduce.reduce.memory.mb</name> <value>4096</value> </property> <property> <name>mapreduce.reduce.java.opts</name> <value>-Xmx3584M</value> </property> <property> <name>mapred.child.env</name> <value>LD_LIBRARY_PATH=/home/hadoop/lzo/lib</value> </property> <!--多租户配置,新增,和yarn-site.xml中acl配合使用--> <property> <name>mapreduce.cluster.acls.enabled</name> <value>true</value> </property> </configuration>
capacity-scheduler.xml
<!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <configuration> <property> <name>yarn.scheduler.capacity.maximum-applications</name> <value>10000</value> <description> Maximum number of applications that can be pending and running. </description> </property> <property> <name>yarn.scheduler.capacity.maximum-am-resource-percent</name> <value>0.1</value> <description> Maximum percent of resources in the cluster which can be used to run application masters i.e. controls number of concurrent running applications. </description> </property> <property> <name>yarn.scheduler.capacity.resource-calculator</name> <value>org.apache.hadoop.yarn.util.resource.DefaultResourceCalculator</value> <description> The ResourceCalculator implementation to be used to compare Resources in the scheduler. The default i.e. DefaultResourceCalculator only uses Memory while DominantResourceCalculator uses dominant-resource to compare multi-dimensional resources such as Memory, CPU etc. </description> </property> <property> <name>yarn.scheduler.capacity.root.queues</name> <value>default,analysis</value> <!--增加新的队列--> <description> The queues at the this level (root is the root queue). </description> </property> <property> <name>yarn.scheduler.capacity.root.default.capacity</name> <value>70</value> <!--修改资源配置比--> <description>Default queue target capacity.</description> </property> <property> <name>yarn.scheduler.capacity.root.default.user-limit-factor</name> <value>1.4</value> <description> Default queue user limit a percentage from 0.0 to 1.0. </description> </property> <property> <name>yarn.scheduler.capacity.root.default.maximum-capacity</name> <value>100</value> <description> The maximum capacity of the default queue. </description> </property> <property> <name>yarn.scheduler.capacity.root.default.state</name> <value>RUNNING</value> <description> The state of the default queue. State can be one of RUNNING or STOPPED. </description> </property> <property> <name>yarn.scheduler.capacity.root.default.acl_submit_applications</name> <value>*</value> <description> The ACL of who can submit jobs to the default queue. </description> </property> <property> <name>yarn.scheduler.capacity.root.default.acl_administer_queue</name> <value>*</value> <description> The ACL of who can administer jobs on the default queue. </description> </property> <property> <name>yarn.scheduler.capacity.node-locality-delay</name> <value>40</value> <description> Number of missed scheduling opportunities after which the CapacityScheduler attempts to schedule rack-local containers. Typically this should be set to number of nodes in the cluster, By default is setting approximately number of nodes in one rack which is 40. </description> </property> <!--新添加配置,20191022新增--> <property> <name>yarn.scheduler.capacity.root.analysis.capacity</name> <value>30</value> <!--理想资源配置比,所有队列比之和为100--> </property> <property> <name>yarn.scheduler.capacity.root.analysis.user-limit-factor</name> <value>1.9</value> <!--可以配置为允许单个用户获取更多资源的队列容量的倍数。如果值小于1,那么该用户使用的资源仅限该队列资源,而不会大量去占用其他队列的闲暇资源。--> </property> <property> <name>yarn.scheduler.capacity.root.analysis.maximum-capacity</name> <value>50</value> <!--队列使用的资源上线--> </property> <property> <name>yarn.scheduler.capacity.root.analysis.state</name> <value>RUNNING</value> <!--STOOPED时,意思是该队列不再使用--> </property> <property> <name>yarn.scheduler.capacity.root.analysis.acl_submit_applications</name> <value>*</value> </property> <property> <name>yarn.scheduler.capacity.root.analysis.acl_administer_queue</name> <value>*</value> </property> </configuration>
以上配置的解释,仅个人理解的观点,可以结合官方文档进行对比。
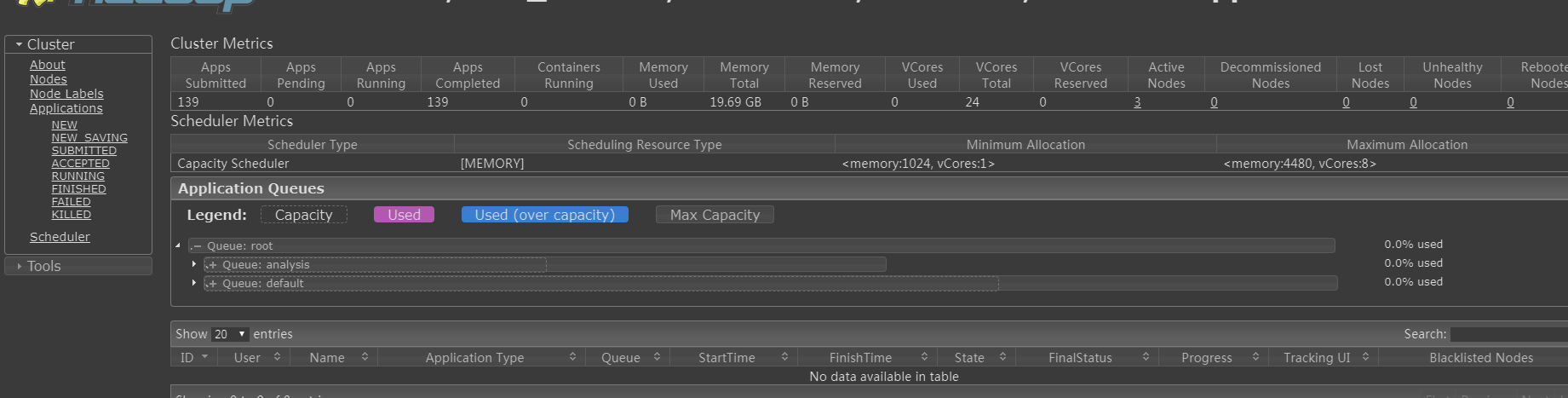
三: 更新yarn参数
yarn rmadmin -refreshQueues
查看ui:
四: 提交任务指定queue(推荐方法,也存在其他方式,不进行列举)
mapreduce:代码中指定队列;
config.set("mapred.job.queue.name", "analysis");
hive:修改配置文件;因为hive一般是用于OLAP平台,可以把队列限制死;
hive-site.xml
<property>
<name>mapreduce.job.queuename</name>
<value>analysis</value>
</property>
spark:运行脚本指定queue 或 代码中指定
1- 脚本方式 --queue analysis 2- 代码方式 saprkConf.set("yarn,spark.queue", "your_queue_name")
五:声明点
1- 抢占资源基于先等待后强制抢占的原则。默认配置是不强制抢占资源。队列借出去的资源被回收后才会归还;也可以强制抢回资源(一般会有延时,默认配置不会强制抢回资源)。以container为单位。 2- 资源可以共用,并且可以达到最大限制资源,一般要配合user-limit-factor参数(默认为1,所以不能占用大量队列外资源,所以该参数一般设置大些); 3- CapacityScheduler资源调度器是没办法解决因资源短缺造成的任务等待问题。 4- 如果资源不足够多,会启动较少的container。(例如想启动一个四个container的任务,由于资源不足,只够启动两个,那么会先启动两个container,如果有资源释放,则会启动预期的四个container)
六: Fair Scheduler与Capacity Scheduler对比(来自Hadoop技术内幕深入解析YARN架构设计与实现原理)
FairScheduler的优点:提高小应用程序响应时间。由于采用了最大最小公平算法,小作业可以快速获取资源并运行完成。
随着Hadoop版本的演化,Fair Scheduler和Capacity Scheduler的功能越来越完善,包括层级队列组织方式、资源抢占、批量调度等,也正因如此,两个调度器同质化越来越严重。目前看来,两个调度器在应用场景、支持的特性、内部实现等方面非常接近,而由于Fair Scheduler支持多种调度策略,因此可以认为Fair Scheduler具备了Capacity Scheduler具有的所有功能。
建议扩展阅读:董西城--Hadoop技术内幕深入解析YARN架构设计与实现原理 6.5 和 6.6节。