NameNode类成分
首先来一张NameNode类的截图
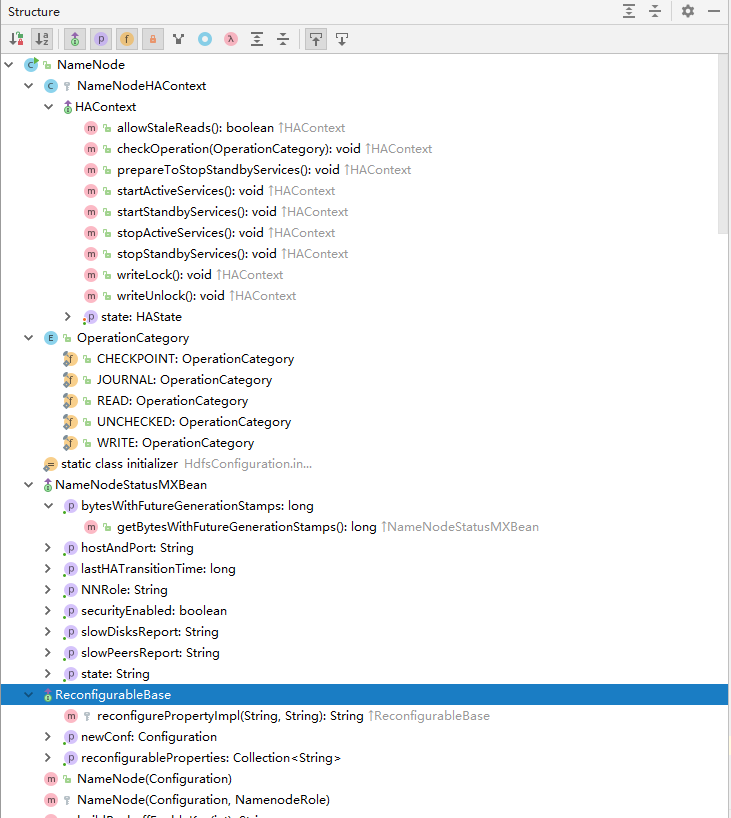
- NameNode 类继承了ReconfigurableBase 类 实现了 NameNodeStatusMXBean 接口
- NameNode 类中有一枚举类 OperationCategory ‘’
- 有一内部类NameNodeHAContext
- 有一静态块(static class initializer)
启动脚本后流程
之前看到启动脚本执行了namenode 这个主类,从类结构来看,首先执行的是静态块的初始化
//调用了 HdfsConfiguration 的init 方法
static{
HdfsConfiguration.init();
}
接下来看这个init()方法
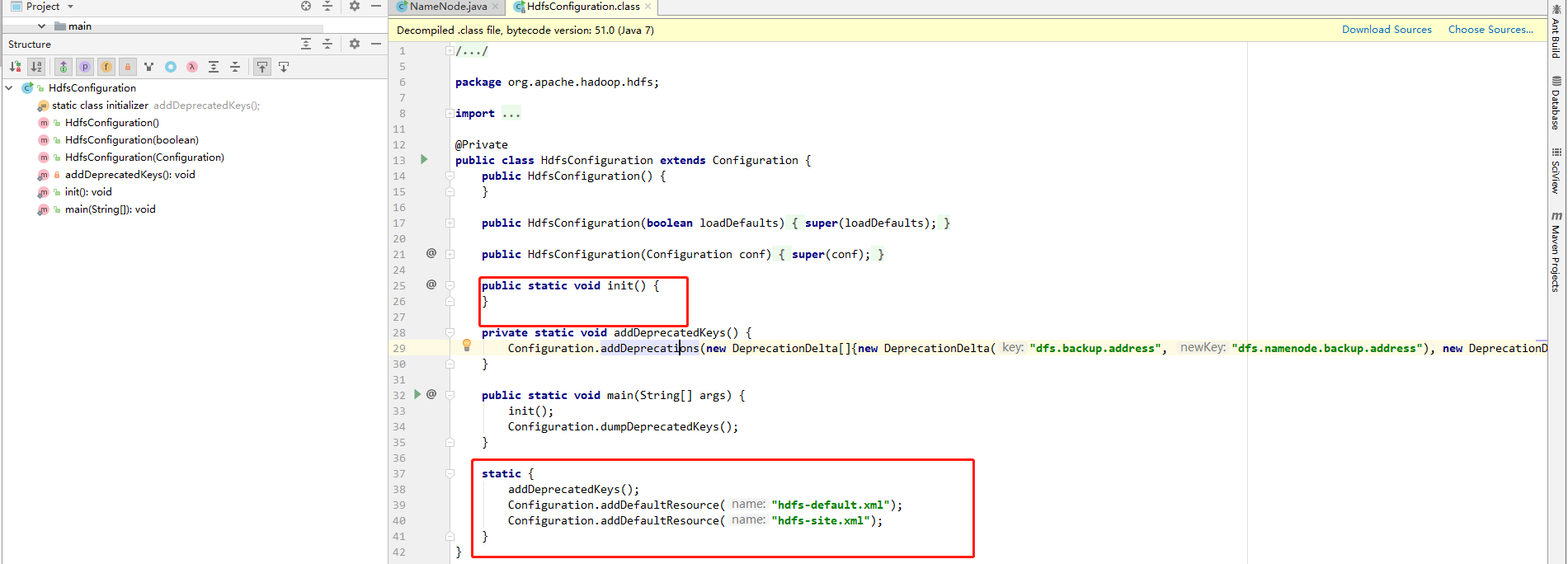
发现init 方法是空的,但是调用init()方法必然回先执行静态块
//弃用属性名和更新后的属性名的对应关系,防止旧的属性名不可以用(再还维护的时候)
addDeprecatedKeys();
//加载配置文件
Configuration.addDefaultResource("hdfs-default.xml");
Configuration.addDefaultResource("hdfs-site.xml");
配置文件放到静态块初始化,可以实现全局唯一,单例的一种实现方式。接下来就是执行main 函数了
public static void main(String argv[]) throws Exception {
//检查传入的参数是不是帮助参数 例如 --help 等,是的话打印使用信息 NameNode.USAGE并退出
if (DFSUtil.parseHelpArgument(argv, NameNode.USAGE, System.out, true)) {
System.exit(0);
}
// 不是帮助参数的话 真正执行集群相关操作
try {
//打印相关日志,如 starting className,hostname ,version,javaVersion,date等
StringUtils.startupShutdownMessage(NameNode.class, argv, LOG);
//重点在这 createNameNode
NameNode namenode = createNameNode(argv, null);
if (namenode != null) {
namenode.join();
}
} catch (Throwable e) {
LOG.error("Failed to start namenode.", e);
terminate(1, e);
}
}
// createNameNode 方法
public static NameNode createNameNode(String argv[], Configuration conf)
throws IOException {
LOG.info("createNameNode " + Arrays.asList(argv));
if (conf == null)
conf = new HdfsConfiguration();
// Parse out some generic args into Configuration.
GenericOptionsParser hParser = new GenericOptionsParser(conf, argv);
argv = hParser.getRemainingArgs();
// Parse the rest, NN specific args.
//解析参数,确认具体的操作类型 例如-format
StartupOption startOpt = parseArguments(argv);
if (startOpt == null) {
printUsage(System.err);
return null;
}
setStartupOption(conf, startOpt);
switch (startOpt) {
//这个就是我们格式化集群的时候执行的操作,暂时先不看了,直接看case 的最后 默认的default
case FORMAT: {
boolean aborted = format(conf, startOpt.getForceFormat(),
startOpt.getInteractiveFormat());
terminate(aborted ? 1 : 0);
return null; // avoid javac warning
}
case GENCLUSTERID: {
System.err.println("Generating new cluster id:");
System.out.println(NNStorage.newClusterID());
terminate(0);
return null;
}
case FINALIZE: {
System.err.println("Use of the argument '" + StartupOption.FINALIZE +
"' is no longer supported. To finalize an upgrade, start the NN " +
" and then run `hdfs dfsadmin -finalizeUpgrade'");
terminate(1);
return null; // avoid javac warning
}
case ROLLBACK: {
boolean aborted = doRollback(conf, true);
terminate(aborted ? 1 : 0);
return null; // avoid warning
}
case BOOTSTRAPSTANDBY: {
String toolArgs[] = Arrays.copyOfRange(argv, 1, argv.length);
int rc = BootstrapStandby.run(toolArgs, conf);
terminate(rc);
return null; // avoid warning
}
case INITIALIZESHAREDEDITS: {
boolean aborted = initializeSharedEdits(conf,
startOpt.getForceFormat(),
startOpt.getInteractiveFormat());
terminate(aborted ? 1 : 0);
return null; // avoid warning
}
case BACKUP:
case CHECKPOINT: {
NamenodeRole role = startOpt.toNodeRole();
DefaultMetricsSystem.initialize(role.toString().replace(" ", ""));
return new BackupNode(conf, role);
}
case RECOVER: {
NameNode.doRecovery(startOpt, conf);
return null;
}
case METADATAVERSION: {
printMetadataVersion(conf);
terminate(0);
return null; // avoid javac warning
}
case UPGRADEONLY: {
DefaultMetricsSystem.initialize("NameNode");
new NameNode(conf);
terminate(0);
return null;
}
default: {
//MetrucsSystem 是用来给系统服务做监控,做统计的,hadoop kafka spark 等都用到了暂时先不展开看了
DefaultMetricsSystem.initialize("NameNode");
//返回一个namenode 对象
return new NameNode(conf);
}
}
}
// 上边new NameNode 调取的构造器
// NameNodeRole == NAMENODE
protected NameNode(Configuration conf, NamenodeRole role)
throws IOException {
super(conf);
//初始化NameNode跟踪器
this.tracer = new Tracer.Builder("NameNode").
conf(TraceUtils.wrapHadoopConf(NAMENODE_HTRACE_PREFIX, conf)).
build();
this.tracerConfigurationManager =
new TracerConfigurationManager(NAMENODE_HTRACE_PREFIX, conf);]
//角色为NameNode
this.role = role;
//设置Namenode 的地址便于让客户端来访问 这个值是我们 配置在core-silt.xml 中的 属性:fs.defaultFS
setClientNamenodeAddress(conf);
// 这个一般是 参数 dfs.nameservice.id 的值,也可以是已经弃用的属性值
String nsId = getNameServiceId(conf);
// 配置的nnid <dfs.ha.namenode.id>
String namenodeId = HAUtil.getNameNodeId(conf, nsId);
//是否是高可用
this.haEnabled = HAUtil.isHAEnabled(conf, nsId);
//namenode 状态 active 还是standby
state = createHAState(getStartupOption(conf));
//用于测试 如果在standby 模式下还允许读返回true <dfs.ha.allow.stale.reads>的值,默认为false
this.allowStaleStandbyReads = HAUtil.shouldAllowStandbyReads(conf);
//初始化了内部类 NameNodeHAContext 对象(文章开始提到过)
this.haContext = createHAContext();
try {
//一些地址 defaultFs , 此方法将值从格式为key.nameserviceId的特定键复制到key,以设置通用配置。
//完成此操作后,其余代码仅读取配置的通用版本,以实现向后兼容和更简单的代码更改。
initializeGenericKeys(conf, nsId, namenodeId);
//初始化namenode ,这个方法摘抄在下边
initialize(getConf());
try {
haContext.writeLock();
state.prepareToEnterState(haContext);
state.enterState(haContext);
} finally {
haContext.writeUnlock();
}
} catch (IOException e) {
this.stopAtException(e);
throw e;
} catch (HadoopIllegalArgumentException e) {
this.stopAtException(e);
throw e;
}
this.started.set(true);
}
//------------------------------------------------------------------------------------------------------------------------------------
//initialize()方法
{
//系统服务统计的一些设置 使用metrics框架
if (conf.get(HADOOP_USER_GROUP_METRICS_PERCENTILES_INTERVALS) == null) {
String intervals = conf.get(DFS_METRICS_PERCENTILES_INTERVALS_KEY);
if (intervals != null) {
conf.set(HADOOP_USER_GROUP_METRICS_PERCENTILES_INTERVALS,
intervals);
}
}
//hadoop 用户组的一些配置 ,用于安全认证 Kerberos
UserGroupInformation.setConfiguration(conf);
//获取namenode Server 的 RpcSeverAdress 然后以NameNode的已配置用户身份登录。
loginAsNameNodeUser(conf);
//统计信息
NameNode.initMetrics(conf, this.getRole());
StartupProgressMetrics.register(startupProgress);
pauseMonitor = new JvmPauseMonitor();
pauseMonitor.init(conf);
pauseMonitor.start();
metrics.getJvmMetrics().setPauseMonitor(pauseMonitor);
if (NamenodeRole.NAMENODE == role) {
//初始化 NameNodeHttServer 并启动 绑定地址为 <dfs.namenode.http-address>的值 默认为0.0.0.0:50070
startHttpServer(conf);
}
//加载fsimage 到内存
loadNamesystem(conf);
//启动HadoopRpcServer 绑定地址<dfs.namenode.servicerpc-address>
rpcServer = createRpcServer(conf);
//备注 createRpcServer部分代码------------------------------开始
this.serviceRpcServer = new RPC.Builder(conf)
.setProtocol(
org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolPB.class) //hadoop 自己实现的协议
.setInstance(clientNNPbService)
.setBindAddress(bindHost)
.setPort(serviceRpcAddr.getPort()).setNumHandlers(serviceHandlerCount)
.setVerbose(false)
.setSecretManager(namesystem.getDelegationTokenSecretManager())
.build();
lifelineRpcServer = new RPC.Builder(conf) //这个给lifelineRpcServer 不太清楚是干什么的
.setProtocol(HAServiceProtocolPB.class)
.setInstance(haPbService)
.setBindAddress(bindHost)
.setPort(lifelineRpcAddr.getPort())
.setNumHandlers(lifelineHandlerCount)
.setVerbose(false)
.setSecretManager(namesystem.getDelegationTokenSecretManager())
.build();
this.clientRpcServer = new RPC.Builder(conf)
.setProtocol(
org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolPB.class)
.setInstance(clientNNPbService).setBindAddress(bindHost)
.setPort(rpcAddr.getPort()).setNumHandlers(handlerCount)
.setVerbose(false)
.setSecretManager(namesystem.getDelegationTokenSecretManager()).build();
//备注 插入rpcServer 部分代码------------------------------结束
//后退 不太清楚是什么配置
initReconfigurableBackoffKey();
if (clientNamenodeAddress == null) {
// This is expected for MiniDFSCluster. Set it now using
// the RPC server's bind address.
clientNamenodeAddress =
NetUtils.getHostPortString(getNameNodeAddress());
LOG.info("Clients are to use " + clientNamenodeAddress + " to access"
+ " this namenode/service.");
}
if (NamenodeRole.NAMENODE == role) {
httpServer.setNameNodeAddress(getNameNodeAddress());
//设置加载后的系统镜像
httpServer.setFSImage(getFSImage());
}
//启动服务 (东西挺多,后续补充)
startCommonServices(conf);
//启动一个定时器把namenode 的统计信息写入文件,可通过配置文件关闭
startMetricsLogger(conf);
}
//------------------------------------------------------------------------------------------------------------------------------------
//-- NameNode 对象的join 方法
public void join() {
try {
//while server is running server.wait (serviceRpcServer/ClientRpcServer/lifelineRpcServer)
rpcServer.join();
} catch (InterruptedException ie) {
LOG.info("Caught interrupted exception ", ie);
}
}