Hadoop的架构思路:
(1)分布式存储(Hadoop分布式文件系统HDFS)
采用客户-服务器模式构建分布式存储集群,让Master(存储主节点)管理Slave
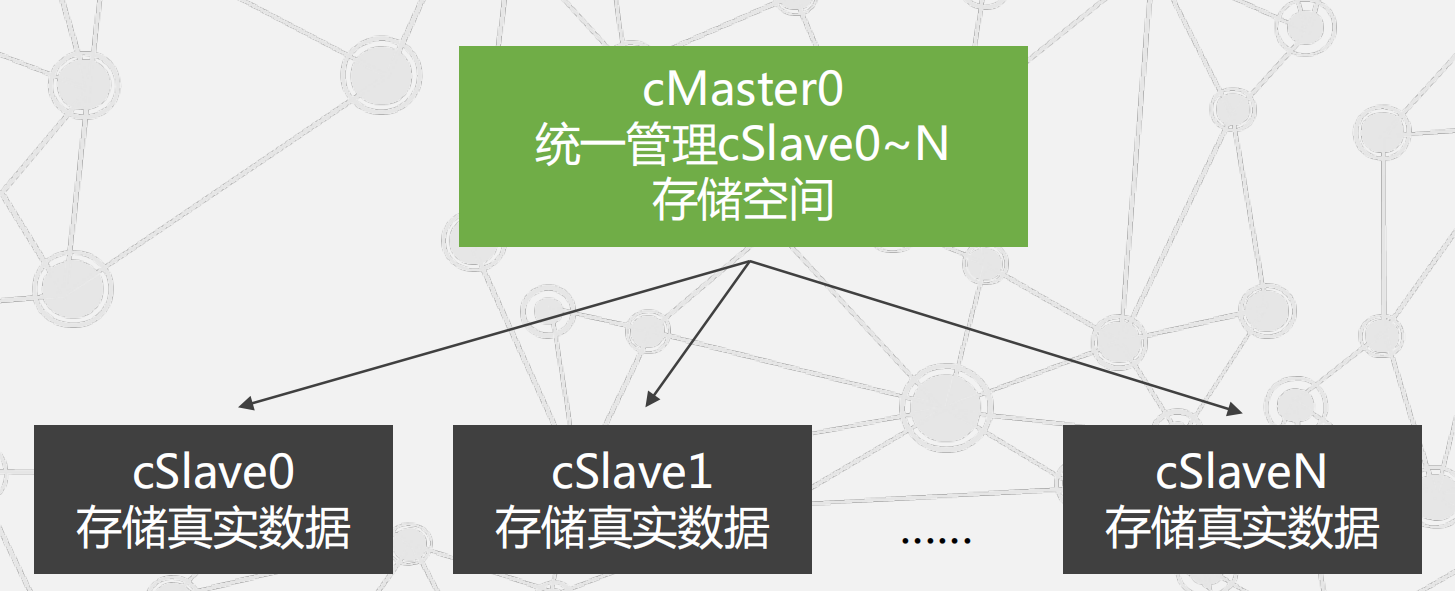
分布式存储,
对内表现为客户-服务器模式。只要保证store master正常工作,我们很容易随意添加store slave,硬盘存储空间无限大。
对外表现为一个统一的存储空间,一个统一的文件接口。整个集群就像是一台机器、一片云,硬盘显示为统一存储空间,文件接口统一。
(2)分布式计算
采用客户-服务器模式构建分布式计算集群: Master为计算主节点
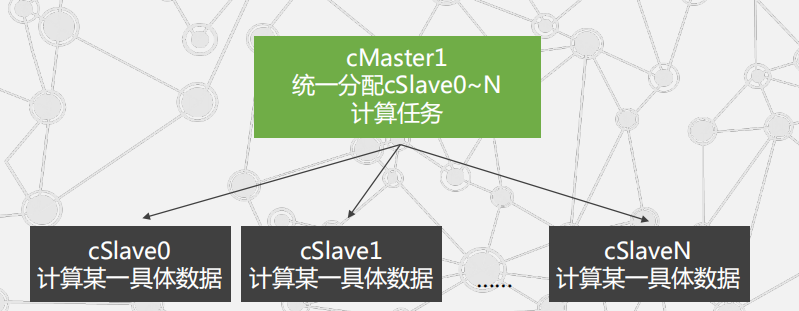
分布式计算步骤流程:
本地计算(Map) --> 洗牌(Shuffle) --> 汇总计算/合并再计算(Reduce) --> 存结果
分布式计算的每一个步骤都是并行的。
第一步 每台机器将各自KV对中的Value连接成一个链表
第二步 各台机器可对<key,valuelist>进行业务处理,称此过程为Reduce。
第三步 将得出的结果再存于DFS。
分布式存储与分布式计算:
分布式存储和分布式计算这两者间并没有关系,它们各自都可以独立存在。

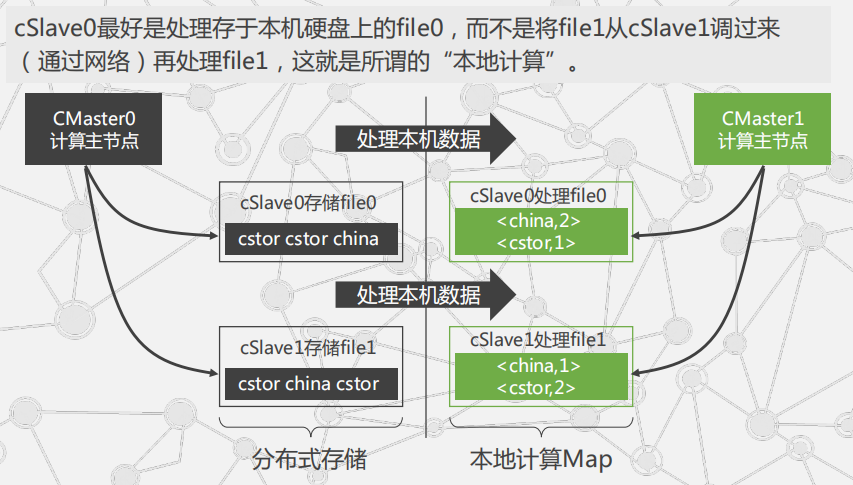
如何能够实现“合并” 过程也由多机执行?洗牌(shuffle)规定将Key值相同的KV对,通过网络发往同一台机器。
Hadoop的冗余存储与冗余计算:
(1)冗余存储:
只要保证存于cSlave0上的数据,同时还存在于别的机器上,即使cSlave0宕机,数据依旧不会丢失。
如引入新机器cSlave2和cSlave3,将存于cSlave0的file0同样存储于cSlave2,存于cSlave1的file1同样存一份于cSlave3。
(2)冗余计算
cSlave0~3的计算任务统一由cMaster1指派。
cMaster1选中先结束的那台机器的计算结果,并停止另一台机器里还在计算的进程
冗余存储于冗余计算的作用:
通过冗余存储,不仅提高了分布式存储可靠性,还提高了分布式计算的可靠性。