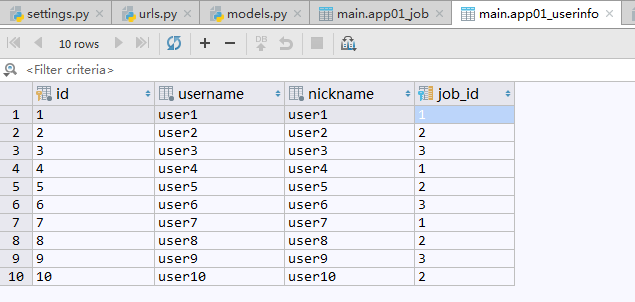
现在有一张用户信息的数据表,表中记录了10个用户的姓名,昵称,年龄,工作等信息,
models文件
from django.db import models
class Job(models.Model):
title=models.CharField(max_length=32)
class UserInfo(models.Model):
username=models.CharField(max_length=32)
nickname=models.CharField(max_length=32)
job=models.ForeignKey(to="Job",to_field="id",null=True)
数据表中记录
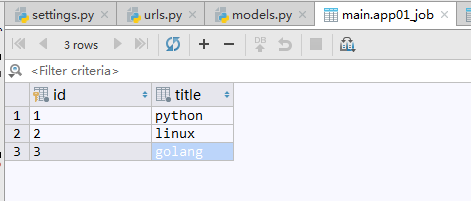
另外一张表中记录用户工作表,关联用户的工作字段
要查出每个用户的用户名,昵称和工作信息
def index(request):
user_list=models.UserInfo.objects.all()
print(user_list.query) # 打印查询时使用的语句
print(type(user_list)) # 打印查询结果的数据类型
for user in user_list:
print("%s-->%s-->%s" %(user.username,user.nickname,user.job.title))
return render(request,'index.html')
打印信息
SELECT "app01_userinfo"."id", "app01_userinfo"."username", "app01_userinfo"."nickname", "app01_userinfo"."job_id" FROM "app01_userinfo" <class 'django.db.models.query.QuerySet'> user1-->user1-->python user2-->user2-->linux user3-->user3-->golang user4-->user4-->python user5-->user5-->linux user6-->user6-->golang user7-->user7-->python user8-->user8-->linux user9-->user9-->golang user10-->user10-->linux
在服务端进行这些操作,这些查询语句的性能是很低的,遍历取出这10个用户的姓名,昵称,工作等重要信息要在两张数据库中执行11次查询操作,首先只从user表中查出所有用户记录,需要执行一次查询操作,查询job数据表,每次循环一次用户信息的列表,都需要从job表中查询一次用户的工作信息,数据表中总共记录了10条用户记录,所以还需要循环10次才能从job表中查询完成所有用户的工作信息,所以一共需要执行11次数据库查询操作,那么有么有好的办法能够提高数据库查询的效率?
def index(request):
user_list=models.UserInfo.objects.values("username","nickname","job")
print(user_list.query) # 打印查询时使用的语句
print(type(user_list)) # 打印查询结果的数据类型
print("user_list:",user_list)
for user in user_list:
print(user["username"], user["nickname"], user["job"])
return render(request,'index.html')
运行程序,在服务端后台打印信息:
SELECT "app01_userinfo"."username", "app01_userinfo"."nickname", "app01_userinfo"."job_id" FROM "app01_userinfo"
<class 'django.db.models.query.QuerySet'>
user_list: <QuerySet [{'username': 'user1', 'nickname': 'user1', 'job': 1}, {'username': 'user2', 'nickname': 'user2', 'job': 2}, {'username': 'user3', 'nickname': 'user3', 'job': 3}, {'username': 'user4', 'nickname': 'user4', 'job': 1}, {'username': 'user5', 'nickname': 'user5', 'job': 2}, {'username': 'user6', 'nickname': 'user6', 'job': 3}, {'username': 'user7', 'nickname': 'user7', 'job': 1}, {'username': 'user8', 'nickname': 'user8', 'job': 2}, {'username': 'user9', 'nickname': 'user9', 'job': 3}, {'username': 'user10', 'nickname': 'user10', 'job': 2}]>
user1 user1 1
user2 user2 2
user3 user3 3
user4 user4 1
user5 user5 2
user6 user6 3
user7 user7 1
user8 user8 2
user9 user9 3
user10 user10 2
可以看到,查询的user_list依然是一个queryset,但是这个对象集合内部确是一个字典,而且这次的查询只执行了两次数据库查询操作,通过这种方式,只需要两次查询就能得到想要的数据,优化了数据库的查询效率
Django数据库优化之select_related主动连表查询
上面的例子中,去对象的集合的时候,难道只能查询当前数据表,不能查询其他数据表吗?当然不是,在这里还可以使用select_related这个方法,在第一次查询的时候,在all()后面加上一个select_related来主动的连表查询,在创建这两张数据表时,job在user数据表中作为一个foreignkey存在的,所以加上select_后不仅只查询到了user数据库的记录,同时也查询了job数据表中的记录
def index(request):
user_list=models.UserInfo.objects.all().select_related("job")
print(user_list.query) # 打印查询时使用的语句
print(type(user_list)) # 打印查询结果的数据类型
print("user_list:",user_list)
for user in user_list:
print("%s-->%s-->%s" %(user.username,user.nickname,user.job.title))
return render(request,'index.html')
服务端打印结果
SELECT "app01_userinfo"."id", "app01_userinfo"."username", "app01_userinfo"."nickname", "app01_userinfo"."job_id", "app01_job"."id", "app01_job"."title" FROM "app01_userinfo" LEFT OUTER JOIN "app01_job" ON ("app01_userinfo"."job_id" = "app01_job"."id")
<class 'django.db.models.query.QuerySet'>
user_list: <QuerySet [<UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>]>
user1-->user1-->python
user2-->user2-->linux
user3-->user3-->golang
user4-->user4-->python
user5-->user5-->linux
user6-->user6-->golang
user7-->user7-->python
user8-->user8-->linux
user9-->user9-->golang
user10-->user10-->linux
查看打印出来的查询语句,其中有:
"FROM "app01_userinfo" LEFT OUTER JOIN "app01_job" ON ("app01_userinfo"."job_id" = "app01_job"."id")"
用来做联表查询的,只需要一次就可以查询到所有数据了
同样的,如果还想继续联表,例如在job表中再加一个外键字段desc,只需要在查询语句中把desc加入进来就可以了
user_list=models.UserInfo.objects.all().select_related("job__desc")
这样一来就把三张表联系起来做连表查询了,但是一定要确保所加字段为foreignkey,如果使用类似models.userinfo.objects.all()语句进行查询时,不要做跨表查询,只查询当前表中有的数据,否则查询语句的性能就会下降很多,如果想查其他表中的数据就加上select_related(foreignkey字段名);如果想取多个foreignkey字段的数据,就可以使用select_related(foreignkey字段1, foreignkey字段2,...) 连表查询性能也会降低,select_related就是用来主动联表查询的.
Django数据库优化操作之perfetch_related非主动联表查询
perfetch_related 方法是非主动联表查询,又不进行很多查询语句的一种折衷方案
修改视图函数index
def index(request):
user_list=models.UserInfo.objects.all().prefetch_related("job")
print(user_list.query) # 打印查询时使用的语句
print(type(user_list)) # 打印查询结果的数据类型
print("user_list:",user_list)
for user in user_list:
print("%s-->%s-->%s" %(user.username,user.nickname,user.job.title))
return render(request,'index.html')
后端打印结果:
SELECT "app01_userinfo"."id", "app01_userinfo"."username", "app01_userinfo"."nickname", "app01_userinfo"."job_id" FROM "app01_userinfo" <class 'django.db.models.query.QuerySet'> user_list: <QuerySet [<UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>]> user1-->user1-->python user2-->user2-->linux user3-->user3-->golang user4-->user4-->python user5-->user5-->linux user6-->user6-->golang user7-->user7-->python user8-->user8-->linux user9-->user9-->golang user10-->user10-->linux
使用perfetch_related方法未联表执行两次查询操作,先查用户表中的所有数据,把用户表中的所有job_id全部查询出来,并执行去重操作;结果查询出用户的3种工作,接下来执行select语句的查询job数据表中的title字段,这样一来就执行了两次数据表的查询操作,在perfetch_related方法中加入一个字段job1,执行了两次数据库查询操作;
Django数据库优化操作之only方法:
def index(request):
user_list=models.UserInfo.objects.all().only("username")
print(user_list.query) # 打印查询时使用的语句
print(type(user_list)) # 打印查询结果的数据类型
print("user_list:",user_list)
for user in user_list:
print("%s-->%s" %(user.username,user.nickname))
return render(request,'index.html')
服务端后台打印信息
SELECT "app01_userinfo"."id", "app01_userinfo"."username" FROM "app01_userinfo" <class 'django.db.models.query.QuerySet'> user_list: <QuerySet [<UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>]> user1-->user1 user2-->user2 user3-->user3 user4-->user4 user5-->user5 user6-->user6 user7-->user7 user8-->user8 user9-->user9 user10-->user10
执行查询操作的时候加上only方法,其查询结果还是一个对象集合,但是从打印出的查询语句可以看到,执行查询操作时,只查询了用户的id字段和username字段,并没有查询nickname字段,但是在后面的循环中,又可以打印用户的nickname信息,为什么呢,因为执行了一次查询的请求操作,由此得知,查询操作使用了only方法,在only方法加入哪个查询字段,在后面就是用哪个查询字段,加only参数是从查询结果中只取某个字段,而另外一个defer方法则是从查询解雇中排除某个字段.
Django数据库优化之defer方法
修改defer视图函数
def index(request):
user_list=models.UserInfo.objects.all().defer("username")
print(user_list.query) # 打印查询时使用的语句
print(type(user_list)) # 打印查询结果的数据类型
print("user_list:",user_list)
for user in user_list:
print("%s" % user.nickname)
return render(request,'index.html')
服务端打印信息
SELECT "app01_userinfo"."id", "app01_userinfo"."nickname", "app01_userinfo"."job_id" FROM "app01_userinfo" <class 'django.db.models.query.QuerySet'> user_list: <QuerySet [<UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>]> user1 user2 user3 user4 user5 user6 user7 user8 user9 user10
通过打印的查询语句可以知道,使用defer方法后,只从数据库中查询了用户id字段和用户nickname字段操作,并没有查询username字段,由此也可以提高Django查询数据库的性能