这周老师布置了一项作业,让我们回去将自己喜欢的小说里面的主角出场次数统计出来,我对这个充满了兴趣,但我遇到了三个问题:
(1)一开始选了一部超长的小说(最爱之一),但是运行时老是不行,老是显示下图错误:

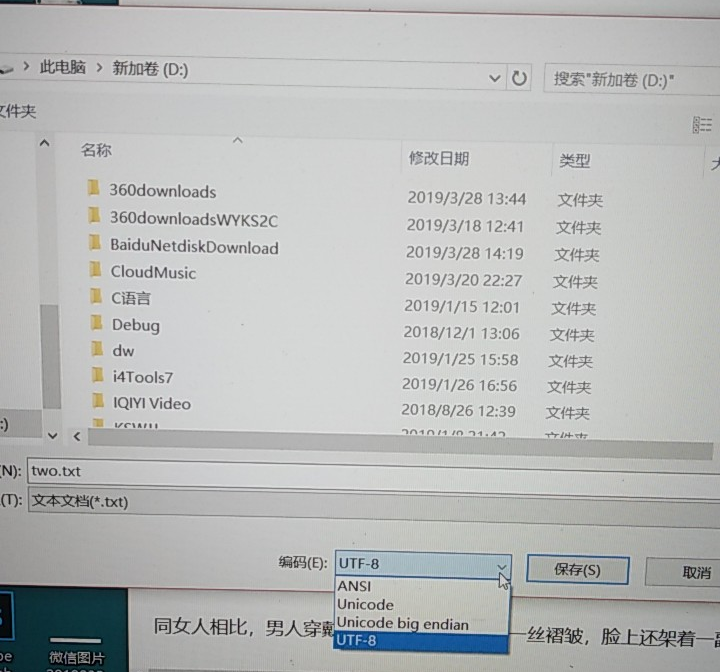
(2)我一开始是像书本那样直接把txt文件名打上去,类似于open(‘two.txt’,'r').read(),但总是出现一下一行字:

(3)三个字的人名总是会有几个人只打了两个字
一、撇开这些问题,开始写代码:
我刚开始以为是小说太长了,运行不了,就找了一部短一些的小说,我最爱的小说——《我和你差之微毫的世界》
结果成功了
代码如下:
import jieba txt=open("d:\《我和你差之微毫的世界》北倾.txt","r").read() others={'有些','自己','已经','知道','时候','刚刚','一下','看着','没有','像是','一个','一眼','好像','什么','声音','这样','起来','这么','回来','就是','微微','一声', '这个','这才','目光','看见','觉得','过来','不是','怎么','现在','突然','一会','还是','几分','一起','顿时','回去','眼神','安然','只是','原本','出去','似乎', '眼睛','下来','整个','手指','两个','因为','一直','电话','语气','问道','出来','心里','开始','门口','这里','那么','房间','那个','格外','灯光','时间','回答','一般','转身', '几乎','事情','坐在','说话','表情'} words= jieba.lcut(txt) #jieba将txt分成多个分词 counts={} #建立一个空字典 for word in words: #这里的word是指遍历从txt的第一个分词到最后一个分词 if len(word)==1: continue elif word=="小叔" or word=='温少远'or word=='温少': rword="小叔" else: rword=word counts[rword]=counts.get(rword,0)+1 for word in others: del(counts[word]) items=list(counts.items()) items.sort(key=lambda x:x[1],reverse=True) for i in range(5): word,count=items[i] print("{0:<10}{1:>5}".format(word,count))
结果:

实在是太开心啦啦啦啦,虽然others那里耗费了很长时间,做出来还是很开心的。
二、解决问题(1)
我还是对第一篇小说百思不得其解,上网百度了后才知道,原来是我第一篇小说另存为是选择编码方式不是utf-8,只要改成utf-8就可以了
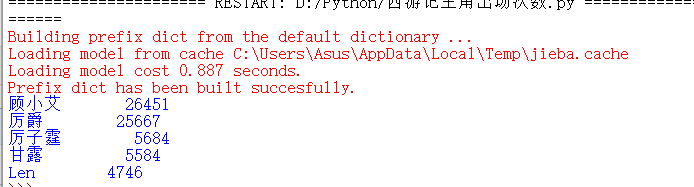
我改了一下代码,换成了第一部超长小说的统计,代码就不贴了,类似的,但不知道为什么厉爵风只出现了厉爵(有待考证???):
三、解决问题(2)
上百度搜一下,找到了一个解决方法:把命令改为txt=open(‘d:\two.txt’,'r').read()就可以了
原因:在python中‘’为转义字符,要想输出‘’,要么多加一个"",写成\,要么在字符串前加r,txt=open(r'd:\two.txt','r').read()
四、解决问题(3)
只要在程序里添加一个jieba.add_word()就可以自定义一个新的分词了,但该新的分词只对该程序有效,并不是永久添加
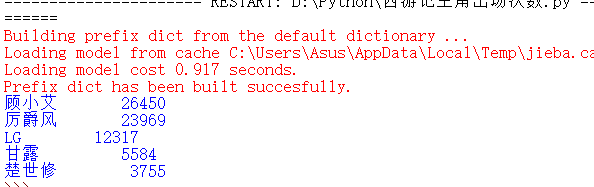
import jieba jieba.add_word('厉爵风') txt=open("d://two.txt","r",encoding='utf-8').read() others={'有些','自己','已经','知道','时候','刚刚','一下','看着','没有','像是','一个','一眼','好像','什么','声音','这样','起来','这么','回来','就是','微微','一声','说道', '这个','这才','目光','看见','觉得','过来','不是','怎么','现在','突然','一会','还是','几分','一起','顿时','回去','眼神','安然','只是','原本','出去','似乎', '眼睛','下来','整个','手指','两个','因为','一直','电话','语气','问道','出来','心里','开始','门口','这里','那么','房间','那个','格外','灯光','时间','回答','一般','转身', '几乎','事情','坐在','说话','表情'} words= jieba.lcut(txt) #jieba将txt分成多个分词 counts={} #建立一个空字典 for word in words: #这里的word是指遍历从txt的第一个分词到最后一个分词 if len(word)==1: continue elif word=="厉子霆" or word=='Len'or word=='LG': rword="LG" else: rword=word counts[rword]=counts.get(rword,0)+1 for word in others: del(counts[word]) items=list(counts.items()) items.sort(key=lambda x:x[1],reverse=True) for i in range(5): word,count=items[i] print("{0:<10}{1:>5}".format(word,count))
结果如图:
小结:问题都解决啦,超级开心的