查询表达式和LINQ to object(下)
连接
LINQ中的连接与Sql上面的连接的概念相似,只不过LINQ上面的连接操作的序列。LINQ有三种各类型的联结,但并不是都是用join关键字,首先来看与sql中的内连接(inner join)相似的join联结。
关于连接,我准备先说一个最重要的结论:①使用join的连接(内连接)左边会进行流式传输,而右边会进行缓冲传输,所以,在连接两个序列时,应该尽可能的将较小的那个序列放到连接的右侧。②使用join...into的连接(左连接)与内连接一样,分组连接要对右边序列进行缓冲,而对左边序列进行流处理。③多个from子句的连接(交叉联接)的执行完全是流式的。这个结论很重要,所以我准备在章节中多次提及。
勘误:MSDN文档在描述计算内联结的jon方法时,将相关的序列称作inner和outer(可以查看IEnumerable<T>.Join()方法。)。这个只是用来区分两个序列的叫法而已,不是真的在指内联结和外联结。对于IEnumerable<T>.Join()来说,outer是指Join的左边,inner是指Join的右边。
使用join做内连接
特点:延迟执行,右边序列缓冲执行,左边序列流式执行。会被编译器转译为Join()
首先看一下join的语法:
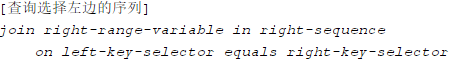
left-key-selector的类型必须要与right-key-selector的类型匹配(能够进行合理的转换也是有效的),意义上面来说也要相等,我们不能吧一个人的出生日期和一个城市的人口做关联。
联结的符号是”equals“而不是“=”或者“==”。
我们也完全有可能用匿名类型来作为键, 因为匿名类型实现了适当的相等性和散列。 如果想创建一个多列的键, 就可以使用匿名类型。
实例:
static void Main(string[] args) { var query = from defect in SampleData.AllDefects join subscription in SampleData.AllSubscriptions on defect.Project equals subscription.Project select new { defect.Summary, subscription.EmailAddress }; foreach (var item in query) { Console.WriteLine($"{item.EmailAddress}-{item.Summary}"); } Console.ReadKey(); }
我们通常需要对序列进行过滤,而在联接前进行过滤比在联接后过滤效率要高得多。
static void Main(string[] args) { var query = from defect in SampleData.AllDefects where defect.Status==Status.Closed join subscription in SampleData.AllSubscriptions on defect.Project equals subscription.Project select new { defect.Summary, subscription.EmailAddress }; foreach (var item in query) { Console.WriteLine($"{item.EmailAddress}-{item.Summary}"); } Console.ReadKey(); }
我们也能在join右边的序列上执行类似的查询,不过稍微麻烦一些:
static void Main(string[] args) { var query = from subscription in SampleData.AllSubscriptions join defect in (from defect in SampleData.AllDefects where defect.Status == Status.Closed select defect) on subscription.Project equals defect.Project select new {subscription.EmailAddress, defect.Summary}; foreach (var item in query) { Console.WriteLine($"{item.EmailAddress}-{item.Summary}"); } Console.ReadKey(); }
内联被编译器转译后的结果如下:

用于LINQ to object的重载签名如下:

当联接的后面不是select子句时,C#3编译器就会引入透明标识符,这样,用于两个序列的范围变量就能用于后面的子句,并且创建了一个匿名类型,简化了对resultSelector参数使用的映射。然而,如果查询表达式的下一 部分是select子句,那么select子句的投影就直接作为resultSelector参数—— 当你可以一步完成这些转换的时候,创建元素对,然后调用Select是没有意义的。你仍然可以把它看做是“select” 步骤所跟随的“join” 步骤, 尽管两者都被压缩到了一个单独的方法调用中。在我看来,这样在思维模式上更能保持一致,而且这种 思维模式也容易理解。除非你打算研究生成的代码,不然可以忽略编译器为你完成的这些优化。令人高兴的是,在学懂了内联接的相关知识后,下一种联接类型就很容易理解了。
使用join... into子句进行分组连接
特点:相当于sql的左连接。延迟执行。右边的序列缓冲执行,左边的序列流式执行。
分组联接结果中的每个元素由左边序列(使用它的原始范围变量)的某个元素和右边序列的所有匹配元素的序列组成。
我们吧之前的例子改成分组联接:
static void Main(string[] args) { var query = from defect in SampleData.AllDefects join subscription in SampleData.AllSubscriptions on defect.Project equals subscription.Project into groupedSubscriptions select new {Defect = defect, Subscriptions = groupedSubscriptions}; foreach (var itemOuter in query) { Console.WriteLine(itemOuter.Defect.Summary); foreach (var itemInner in itemOuter.Subscriptions) { Console.WriteLine(itemInner.EmailAddress); } Console.WriteLine("--------------------"); } Console.ReadKey(); }
每个条目的Subscriptions都是一个内嵌的序列。该序列包含了匹配defect的所有subscription。
分组连接和普通分组(下面会讲这个group....by的连接),对于分组连接来说,在左边序列和结果序列之间是一对一的对应关系, 即使左边序列中的某些元素在右边序列中没有任何匹配的元素, 也无所谓。 这是非常重要的, 有时会用于模拟SQL的左外联接。在左边元素不匹配任何右边元素的时候,嵌入序列就是空的。
下面是一个按时间进行累计的例子:
static void Main(string[] args) { var dates = new DateTimeRange(SampleData.Start, SampleData.End); var query = from date in dates join defect in SampleData.AllDefects on date equals defect.Created.Date into defectDate select new { Date = date, Count = defectDate.Count() }; foreach (var item in query) { Console.WriteLine($"{item.Date}---{item.Count}"); } Console.ReadKey(); }
上面的例子使用了书上的样例。
编译器将分组联接转译为简单地调用GroupJoin方法,就像Join一样。Enumerable.GroupJoin的签名如下:
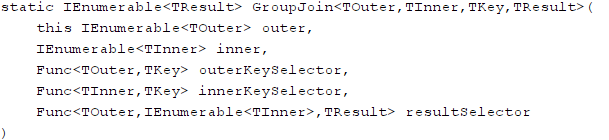
这个方法签名和内联接的方法签名非常相似,只不过resultSelector参数必须要用于处理右边元素的序列,不能处理单一的元素。同内联接一致,如果分组联接后面紧跟着select子句,那么投影就用作GroupJoin调用的结果选择器, 否则,就引入一个 透明标识符。在这个 例子中,分组联接之后紧接着select子句,所以转译后的查询如下:

使用多个from子句的交叉联接
特点:相当于sql的交叉连接。延迟执行。完全的流式执行。
交叉联接的结果和SQL的笛卡儿积一样,是从两个序列中找出所有可能的匹配结果:
static void Main(string[] args) { var query = from firstNumber in Enumerable.Range(1, 2) from secondNumber in Enumerable.Range(1, 2) select new { firstNumber, secondNumber }; foreach (var item in query) { Console.WriteLine($"{item.firstNumber}--{item.secondNumber}"); } Console.ReadKey(); }
上面输出的结果是firstNumber序列中的结果乘以secondNumber序列中的结果,一共是2*2=4个结果。
交叉联接就是通过多个from子句来进行交叉匹配的——前两个from子句的匹配结果在和第三个from子句继续交叉,以此类推。
交叉联接非常像笛卡儿积,但是它更加强大:在任意特定时刻使用的右边序列依赖于左边序列的“当前” 值。也就是说,左边序列中的每个元素都用来生成右边的一个序列,然后左边这个元素与右边新生成序列的每个元素都组成一对。这并不是通常意义上的交叉联接,而是将多个序列高效地合并(flat)成一个序列。不管我们是否使用真正的交叉联接,查询表达式的转译是相同的, 所以为了理解转译过程,我们需要研究一下更复杂的情形。
static void Main(string[] args) { var query = from firstNumber in Enumerable.Range(1, 2) from secondNumber in Enumerable.Range(1, 2)
select new
{
firstNumber,
secondNumber
};
var anotherQuery = Enumerable.Range(1, 2).SelectMany(a => Enumerable.Range(1, 1), (b, c) => new {b, c});
foreach (var item in anotherQuery) { Console.WriteLine($"{item.b}--{item.c}"); }
Console.ReadKey(); }
上面的代码段中query是查询表达式,anotherQuery是查询表达式转译后的代码,二者的输出完全一致。下面是Enumerable.SelectMany的方法签名:

和其他联接一样,如果查询表达式中联接操作后面紧跟的是select子句,那么投影就作为最后的实参;否则,引入一个透明标识符,从而使左右序列的范围变量在后续查询中都能被访问。
SelectMany的一个有意思的特性是,执行完全是流式的——一次只需处理每个序列的一个元素,因为它为左边序列的每个不同元素使用最新生成的右边序列。把它与内联接和分组联接进行比较,就能看出:在开始返回任何结果之前,它们(内联接和分组联接)都要完全加载右边序列。你应该在心中谨记如下问题:序列的预期大小,以及计算多次可能的资源开销,何时考虑要使用哪种类型的联接,哪个作为左边序列,哪个作为右边序列。
SelectMany的合并行为是非常有用的。例如,你可能需要处理大量日志文件,每次处理一行。几乎不用花太多力气,我们就能处理所有行的无缝序列。在可下载的源代码中(C# in depth,网上有源代码,百度吧)有下面伪代码的完整版本,其完整的含义和有效性已经非常清晰:

在短短的5行代码中,我们检索、解析并过滤了整个日志文件集,返回了表示错误的日志项的序列。至关重要的是,我们不会一次性向内存加载单个日志文件的全部内容, 更不会一次性加载所有文件——所有的数据都采用流式处理。
还有一个好的例子是将一个字符串数组分解成一个char数组
分组(group......by)和延续(into子句)
分组
特点:被转译为GroupBy()。延迟执行。缓冲执行。
分组的语法是:group projection by grouping
该子句与select子句一样,出现在查询表达式的末尾。但它们的相似之处不止于此:projection表达式和select子句使用的投影是同样的类型。只不过生成的结果稍有不同。
grouping表达式通过其键来决定序列如何分组。整个结果是一个序列,序列中的每个元素本身就是投影后元素的序列,还具有一个 Key属性,即用于分组的键;这样的组合是封装在IGrouping<TKey,TElement>接口中的,它扩展了IEnumerable <TElement>。同样,如果 你想根据多个值来进行分组,可以使用一个匿名类型作为键。
static void Main(string[] args) { var query = from defect in SampleData.AllDefects where defect.AssignedTo != null group new{defect.Status,defect.Summary} by defect.AssignedTo; foreach (var item in query) { Console.WriteLine(item.Key.Name); foreach (var defect in item) { Console.WriteLine($" {defect.Status} ({defect.Summary})"); } } Console.ReadKey(); }
请注意group new{defect.Status,defect.Summary} by defect.AssignedTo;这个group后面跟的这个new{defect.Status,defect.Summary}就是投影,如果有需要的话,和select一样,可以用一个匿名对象来进行横向的缩小序列。
by后面定义的是要作为分组的键(key)。还可以在by后面跟一个匿名类型,如果你有这个需求的话。
注意,分组无法对结果进行流处理,因为要进行分组,它会对每个元素应用键选择和投影,并缓冲被投影元素的分组序列。尽管它不是流式的,但执行仍然是延迟的,直到开始获取其结果。
分组(group...by)和分组联接(join...into)在功能上面很相似,但是有一个需要注意的地方是分组联接(join...into)会显示左边序列的所有元素,不管左边序列中的元素有没有匹配到东西,这个很像SQL中的左联接,而分组(group...by)则不是。
分组(group...by)被转译成GroupBy。很简单,不说了。
查询延续
到目前为止,我们的查询表达式以至于整个表达式都是以select或group...by子句作为结尾。而有些时候,你也许打算对结果进行更多的处理——此时,就可以用到查询延续。
查询延续提供了一种方式,把一个查询表达式的结果用作另外一个查询表达式的初始序列。它可以应用于group...by和select子句上,语法对于两者是一样的——你只需使用上下文关键字into,并为新的范围变量提供一个名称就可以了。范围变量接着能用在查询表达式的下一部分。
C#语言规范在解释这个术语时,将它从这种形式:
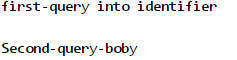
转译为

下面是一个例子:
static void Main(string[] args) { var query = from defect in SampleData.AllDefects where defect.AssignedTo != null group defect by defect.AssignedTo into grouped select new { Ass=grouped.Key,Count=grouped.Count()}; foreach (var item in query) { Console.WriteLine(item.Ass+"-"+item.Count); } Console.ReadKey(); }
延续的前提是使用into来将前面投影的结果作为范围变量进行了传递。上述代码是用另外一个投影(select new { Ass=grouped.Key,Count=grouped.Count()};)来延续分组结果。
按照规范,上述的查询表达式被转译为下述:

接着,又会被转译为这样:

理解延续的另一种方式是, 可以把它们看做两个分开的语句。从实际编译器转译的角度看,这不够准确,不过我发现这样可以更容易明白所发生的事情。在这个例子中,查询表达式(以及对query变量进行分配的表达式)可以看做是如下两个语句:

如果你发现这样更容易阅读的话也可以在代码中做这样的拆分,并且在你开始执行前,不会执行任何计算。
注意:join ... into不是延续 你很容易掉进这样的陷阱, 即看到了上下文关键字into,就认为这是查询延续。对于联接来说,这是不对的。用于分组联接的join ...into子句不能形成一个延续的结构。主要的区别在于,在分组联接中,你仍然可以使用所有的早期范围变量( 用于联接右边名称的范围变量除外)。而对比本节的查询不难发现,延续会清除之前的范围变量,只有在延续中声明的范围变量才能在供后续使用。
在查询表达式和点标记之间做出选择
正如我们在本章看到的,查询表达式在编译之前,先被转译成普通的C#。用普通的C#调用LINQ查询操作符来代替查询表达式,这种做法并没有官方名称,很多开发者称其为点标记(dot notation)。每个查询表达式都可以写成点标记的形式,反之则不成立:很多LINQ操作符在C#中不存在等价的查询表达式。最重要的问题是:什么时候使用哪种语法?(when,which)
最明显的必须使用点标记的情形是调用Reverse、ToDictionary这类没有相应的查询表达式语法的方法。然而即使查询表达式支持你要使用的查询操作符,也很有可能无法使用你想使用的特定重载。
我总结的一些使用查询表达式要优于使用点标记操作符的地方如下:
存在表(序列)的联接的地方,并且需要使用let操作符定义一个透明标识符的时候。
排序,复杂的排序。