-
Study notes for Sparse Coding
Sparse Coding
- Sparse coding is a class of unsupervised methods for learning sets of over-complete bases to represent data efficiently. The aim of sparse coding is to find a set of basis vectors
 such that an input vector
such that an input vector ) can be represented as a linear combination of these basis vectors:
can be represented as a linear combination of these basis vectors:
- The advantage of having an over-complete basis is that our basis vectors are better able to capture structures and patterns inherent in the input data
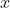 .
.
- However, with an over-complete basis, the coefficients are no longer uniquely determined by the input vector. Therefore, in sparse coding, we introduce the additional criterion of sparsity to resolve the degeneracy introduced by over-completeness.
- The sparse coding cost function is defined on a set of m input vectors as:
where
) is a sparsity function which penalizes
is a sparsity function which penalizes 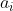 for being far from zero. We can interpret the first term of the sparse coding objective as a reconstruction term which tries to force the algorithm to provide a good representation of , and the second term as a sparsity penalty which forces our representation of (i.e., the learned features) to be sparse. The constant
for being far from zero. We can interpret the first term of the sparse coding objective as a reconstruction term which tries to force the algorithm to provide a good representation of , and the second term as a sparsity penalty which forces our representation of (i.e., the learned features) to be sparse. The constant 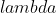 is a scaling constant to determine the relative importance of these two contributions.
is a scaling constant to determine the relative importance of these two contributions.
- Although the most direct measure of sparsity is the
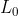 norm, it is non-differentiable and difficult to optimize in general. In practice, common choices for the sparsity cost are the
norm, it is non-differentiable and difficult to optimize in general. In practice, common choices for the sparsity cost are the 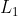 penalty and the log sparsity
penalty and the log sparsity=log(1+a_i^2))
- It is also possible to make the sparsity penalty arbitrary small by scaling down and scaling up by some large constant. To prevent this from happening, we will constrain
 to be less than some constant
to be less than some constant 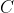 . The full sparse coding cost function hence is:
where the constant is usually set
. The full sparse coding cost function hence is:
where the constant is usually set 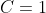
- One problem is that the constraint cannot be forced using simple gradient-based methods. Hence, in practice, this constraint is weakened to a "weight decay" term designed to keep the entries of small:
- Another problem is that the L1 norm is not differentiable at 0, and hence poses a problem for gradient-based methods. We will "smooth out" the L1 norm using an approximation which will allow us to use gradient descent. To "smooth out" the L1 norm, we use
 in place of
in place of 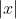 , where
, where  is a "smoothing parameter" which can also be interpreted as a sort of "sparsity parameter" (to see this, observe that when is large compared to , the
is a "smoothing parameter" which can also be interpreted as a sort of "sparsity parameter" (to see this, observe that when is large compared to , the  is dominated by , and taking the square root yield approximately
is dominated by , and taking the square root yield approximately  .
.
- Hence, the final objective function is:
- The set of basis vectors are called "dictionary" (
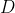 ). is "adapted" to if it can represent it with a few basis vectors, that is, there exists a sparse vector
). is "adapted" to if it can represent it with a few basis vectors, that is, there exists a sparse vector 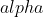 in
in  such that
such that  . We call the sparse code. It is illustrated as follows:
. We call the sparse code. It is illustrated as follows:
Learning
- Learning a set of basis vectors
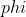 using sparse coding consists of performing two separate optimizations (i.e., alternative optimization method):
using sparse coding consists of performing two separate optimizations (i.e., alternative optimization method):
- The first being an optimization over coefficients for each training example
- The second being an optimization over basis vectors across many training examples at once.
- However, the classical optimization alternates between D and can achieve good results, but very slow.
- A significant limitation of sparse coding is that even after a set of basis vectors have been learnt, in order to "encode" a new data example, optimization must be performed to obtain the required coefficients. This significant "runtime" cost means that sparse coding is computationally expensive to implement even at test time, especially compared to typical feed-forward architectures.
Remarks
- From my view, due to the sparseness enforced in the dictionary learning (i.e., sparse code), the restored matrix is able to remove noise of original matrix, i.e., having some effect of denoising. Hence, Sparse coding could be used to denoise images.
References
-
相关阅读:
python之----------字符编码具体原理
css部分复习整理
秘钥登录服务器执行shell脚本
idea配置github
InteliJ IDEA 简单使用:配置项目所需jdk
IntelliJ IDEA 中安装junit插件
IDEA 运行maven命令时报错: -Dmaven.multiModuleProjectDirectory system propery is not set
idea如何编译maven项目
idea项目左边栏只能看到文件看不到项目结构
idea如何导入一个maven项目
-
原文地址:https://www.cnblogs.com/pangblog/p/3317940.html
Copyright © 2020-2023
润新知
