-
Study notes for B-tree and R-tree
B-tree
- B-tree is a tree data structure that keeps data sorted and allows searches, sequential access, insertions, and deletions in logarithmic time.
- B-trees are balanced search trees: height
) for the worst case, where t >2 is the order of tree, i.e., the maximum number of pointers for each node.
for the worst case, where t >2 is the order of tree, i.e., the maximum number of pointers for each node.
- Note that t is typically set so that one node fits into one disk block or page.
- B-tree is a generalization of a binary search tree (i.e., a multiway tree) in that a node can have more than two children.
- Similar to red-black trees, but show better performance on disk I/O operations.
- Binary trees may be useful for rapid searching in main memory, but not appropriate for data stored on disks.
- When accessing data on a disk, an entire block (or page) is input at once, so it makes sense to design the tree so that each node essentially occupies one entire block.
- B-tree is optimized for systems that read and write large blocks of data. B-trees (and its variants) are commonly used in databases and file systems.
- Structure: every node x has four fields
- The number of keys currently stored in node x, i.e., n, which is between [t/2]-1 and t-1.
- The n keys themselves, stored in non-decreasing order:
- A boolean value
- n+1 pointers:
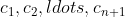 to its children, represented by:
to its children, represented by:
- Properties:
- All leaves have the same height, which is the tree's height h.
- B-tree guarantees a storage utilization of at least 50%, i.e., at least half of each allocated page actually stores index entries.
- There are upper and lower bounds on the number of keys on a node.
- Lower bound: every node other than root must have at least t-1 keys => at least t children
- Upper bound: every node can contain at most 2t-1 keys => every internal node has at most 2t children.
- Example is shown as follows:
- Conventions:
- Root of B-tree is always in main memory
- Any node pased as parameter must have had a Disk-Read operation performed on them.
B+-tree
- A B-tree is very efficient with respect to search and modification operations that involve a single record.
- But it is not particularly suited for sequential operations nor for range searches, B+-tree is to solve this issue.
- B+-tree is the most widely used index structure for databases.
- Main idea:
- The leaf nodes contain all the key values (and the associated information)
- The internal nodes (organized as a B-tree) store some separators which have the only function of determining the path to follow during searching
- The leaf nodes are linked in a (doubly linked) list, in order to efficiently support range searches or sequential searches.
- Comparison with B-trees:
- The search of a single key value is in general more expensive in a B+-tree because we have always to reach a leaf node to fetch the pointer to the data file.
- For operations requiring an ordering of the retrieved records according to the search key values or for range queries, the B+-tree is to be preferred.
- The B-tree requires less storage since the key values are stored only once.
B*-tree
- B*-tree is a variation of the B+-tree where the storage utilization for nodes must be at least 66% (2/3) instead of 50%.
- The non-root and non-leaf nodes of B*-tree contain pointers to sibling nodes.
R-tree
- The B-tree and its variants are useful to index and search data in one-dimensional space (where data is stored on disks rather than main memory). The basic idea is to separate a line into several segments and gradually reduce to the minimum segment where the searched data is located, illustrated as follows (figure is obtained from July et al.'s blog):
- However, for high-dimensional data, B-tree and its variants are not efficient. Other tree index structures such as R-tree, kd-tree are more suited in this case.
- R-tree is a generalization of B-tree for indexing and searching multi-dimensional data such as geographical coordinates, rectangles or polygons.
- A commonly real-world usage for an R-tree might be to store spatial objects such as restaurant locations, or the polygons that typical maps are made of scuh as streets, buildings, outlines of lakes, coastlines, etc, and then find answers quickly to queries such as "Find all museums within 2km of my current location". => It is useful for map.
- Main points:
- The key idea is to group nearby objects and represent them with their minimum bounding rectangle in the next higher level of the tree.
- At the leaf level, each rectangle describes a single object; at higher levels, the aggregation of an increasing number of objects.
- R-tree is a balanced search tree (i.e., all leaf nodes are at the same height), organizes the data in pages, and is designed for storage on disk (as used in databases).
- R-tree only guarantees a minimum usage of 30-40%. The reason is the more complex balancing required for spatial data as opposed to linear data stored in B-trees.
- The key difficulty of R-tree is to build an efficient tree that on one hand is balanced, on the other hand the rectangles do not cover too much empty space and do not overlap too much.
- A typical R-tree is represented as follows (figure is originally from Wikipedia).
References
-
相关阅读:
loadrunner基础学习笔记五-场景
loadrunner基础学习笔记四
loadrunner基础学习笔记三
loadrunner基础学习笔记二
loadrunner 基础-学习笔记一
jmeter创建基本的FTP测试计划
简单FTP服务器搭建
Vitya and Strange Lesson CodeForces
Ancient Printer HDU
ZYB loves Xor I HDU
-
原文地址:https://www.cnblogs.com/pangblog/p/3315287.html
Copyright © 2020-2023
润新知





