Hadoop
1.1 什么是Hadoop

-
Hadoop的概念:
-
Apache™ Hadoop® 是一个开源的, 可靠的(reliable), 可扩展的(scalable)分布式计算框架
-
允许使用简单的编程模型跨计算机集群分布式处理大型数据集
-
可扩展: 从单个服务器扩展到数千台计算机,每台计算机都提供本地计算和存储
-
可靠的: 不依靠硬件来提供高可用性(high-availability),而是在应用层检测和处理故障,从而在计算机集群之上提供高可用服务
-
-
-
Hadoop名字的由来
-
作者:Doug cutting
-
Hadoop项目作者的孩子给一个棕黄色的大象样子的填充玩具-Hadoop
- MySQL-主要创始人Monty女儿名字——My
-
Structured Query Language:结构化查询语言SQL
-
-
Hadoop能做什么?
-
搭建大型数据仓库
-
PB级数据的存储 处理 分析 统计等业务
-
搜索引擎
-
日志分析
-
数据挖掘
-
商业智能(Business Intelligence,简称:BI)
商业智能通常被理解为将企业中现有的数据(订单、库存、交易账目、客户和供应商等数据)转化为知识,帮助企业做出明智的业务经营决策的工具。从技术层面上讲,是数据仓库、数据挖掘等技术的综合运用。
-
-
1.2 为什么使用Hadoop
数据挖掘
1、“从已有数据中提取出隐含在过去、未知且有价值的潜在信息”
2、“一门从大量资料或者数据中提取有用信息的科学。
使用场景:
农夫山泉用大数据卖矿泉水

上海城乡结合部九亭镇新华都超市的一个角落,农夫山泉的矿泉水堆静静地摆放在这里。来自农夫山泉的业务员每天例行公事地来到这个点,拍摄10张 照片:水怎么摆放、位置有什么变化、高度如何……这样的点每个业务员一天要跑15个,按照规定,下班之前150张照片就被传回了杭州总部。每个业务员,每 天会产生的数据量在10M,这似乎并不是个大数字。但农夫山泉全国有10000个业务员,这样每天的数据就是100G,每月为3TB。当这些图片如雪花般飘入农夫山泉在杭州的机房时,这家公司的CIO 首席信息官 就会有这么一种感觉:守着一座金山,却不知道从哪里挖下第一锹。

胡健想知道的问题包括:怎样摆放水堆更能促进销售?什么年龄的消费者在水堆前停留更久,他们一次购买的量多大?气温的变化让购买行为发生了哪些改变?竞争对手的新包装对销售产生了怎样的影响?不少问题目前也可以回答,但它们更多是基于经验,而不是基于数据。
谷歌的意图
如果说有一家科技公司准确定义了“大数据”概念的话,那一定是谷歌。根据搜索研究公司comScore的数据,仅2012年3月一个月的时间,谷歌处理的搜索词条数量就高达122亿条。谷歌的体量和规模,使它拥有比其他大多数企业更多的应用大数据的途径。
https://about.google/products/ 谷歌产品合集
谷歌意图:谷歌不仅存储了搜索结果中出现的网络连接,还会储存用户搜索关键词的行为,它能够精准地记录下人们进行搜索行为的时间、内容和方式,坐拥人们在谷歌网站进行搜索及经过其网络时所产生的大量机器数据。这些数据能够让谷歌优化广告排序,并将搜索流量转化为盈利模式。谷歌不仅能追踪人们的搜索行为,而且还能够预测出搜索者下一步将要做什么。用户所输入的每一个搜索请求,都会让谷歌知道他在寻找什么,所有人类行为都会在互联网上留下痕迹路径,谷歌占领了一个绝佳的点位来捕捉和分析该路径。换言之,谷歌能在你意识到自己要找什么之前预测出你的意图。这种抓取、存储并对海量人机数据进行分析,然后据此进行预测的能力,就是数据驱动的产品。

位于芬兰哈米纳的Google数据中心
数据挖掘就是指从大量的数据中自动搜索隐藏于其中的有特殊关系性的信息和知识的过程。面对现在海量的、不完整的数据,运用数据挖掘算法对数据进行查找,找出人们所不知道的、有实用价值的信息,这一过程就是数据挖据·。
1.1 大数据概念
**1B(Byte 字节)=8bit,**
1KB (Kilobyte 千字节)=1024B,
1MB (Megabyte 兆字节 简称“兆”)=1024KB,
1GB (Gigabyte 吉字节 又称“千兆”)=1024MB,
1TB (Trillion Byte 万亿字节 太字节)=1024GB,其中1024=2^10 ( 2 的10次方),
1PB(Petabyte 千万亿字节 拍字节)=1024TB,
1EB(Exabyte 百亿亿字节 艾字节)=1024PB,
1ZB (Zettabyte 十万亿亿字节 泽字节)= 1024 EB,
1YB (Yottabyte 一亿亿亿字节 尧字节)= 1024 ZB,
1BB (Brontobyte 一千亿亿亿字节)= 1024 YB.
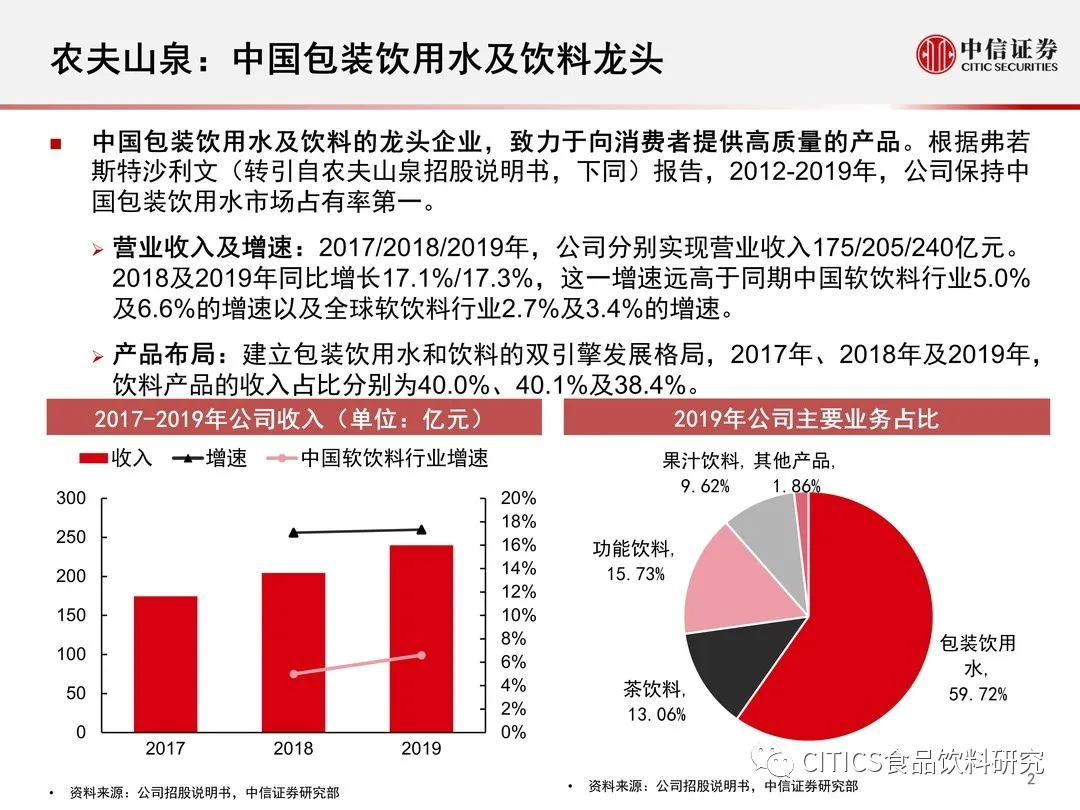
1.2 大数据特点(4V)
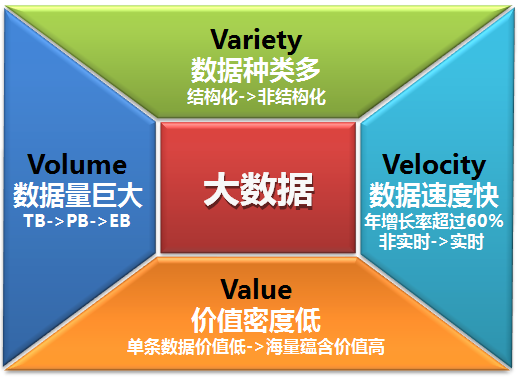
1.3Hadoop发展史
-
-
2003-2004年 Google发表了三篇论文
-
GFS:Google的分布式文件系统Google File System
-
MapReduce: Simplified Data Processing on Large Clusters 简化大规模集群上的数据处理
-
BigTable:一个大型的分布式数据库
-
-
2006年2月Hadoop成为Apache的独立开源项目( Doug Cutting等人实现了DFS和MapReduce机制)。
-
2006年4月— 标准排序(10 GB每个节点)在188个节点上运行47.9个小时。
-
2008年4月— 赢得世界最快1TB数据排序在900个节点上用时209秒。
-
2008年— 淘宝开始投入研究基于Hadoop的系统–云梯。云梯总容量约9.3PB,共有1100台机器,每天处理18000道作业,扫描500TB数据。
-
2009年3月— Cloudera推出CDH(Cloudera’s Dsitribution Including Apache Hadoop)
-
2009年5月— Yahoo的团队使用Hadoop对1 TB的数据进行排序只花了62秒时间。
-
2009年7月— Hadoop Core项目更名为Hadoop Common;
-
2009年7月— MapReduce和Hadoop Distributed File System (HDFS)成为Hadoop项目的独立子项目。
-
2012年11月— Apache Hadoop 1.0 Available
-
2018年4月— Apache Hadoop 3.1 Available
-
搜索引擎时代
- 有保存大量网页的需求(单机 集群)
- 词频统计 word count PageRank
-
数据仓库时代
- FaceBook推出Hive
- 曾经进行数分析与统计时, 仅限于数据库,受数据量和计算能力的限制, 我们只能对最重要的数据进行统计和分析(决策数据,财务相关)
- Hive可以在Hadoop上运行SQL操作, 可以把运行日志, 应用采集数据,数据库数据放到一起分析
-
数据挖掘时代
- 啤酒尿不湿
- 关联分析
- 用户画像/物品画像
-
机器学习时代 广义大数据
- 大数据提高数据存储能力, 为机器学习提供燃料
- alpha go
- siri 小爱 天猫精灵
-
1.4 Hadoop核心组件
- Hadoop是所有搜索引擎的共性问题的廉价解决方案
- 如何存储持续增长的海量网页: 单节点 V.S. 分布式存储
- 如何对持续增长的海量网页进行排序: 超算 V.S. 分布式计算
- HDFS 解决分布式存储问题
- MapReduce 解决分布式计算问题
Hadoop Distributed File System (HDFS™)
A distributed file system that provides high-throughput access to application data.(提供对应用程序数据的高吞吐量访问的分布式文件系统分布式文件系统)
分布式系统是一组电脑,透过网络相互连接传递消息与通信后并协调它们的行为而形成的系统。[1]组件之间彼此进行交互以实现一个共同的目标。把需要进行大量计算的工程数据分割成小块,由多台计算机分别计算,再上传运算结果后,将结果统一合并得出数据结论的科学。
-
源自于Google的GFS论文, 论文发表于2003年10月
-
HDFS是GFS的开源实现
-
HDFS的特点:扩展性&容错性&海量数量存储
-
数据切分、多副本、容错等操作对用户是透明的
-
数据计算: 某个节点崩溃, 会自动重新调度作业计算
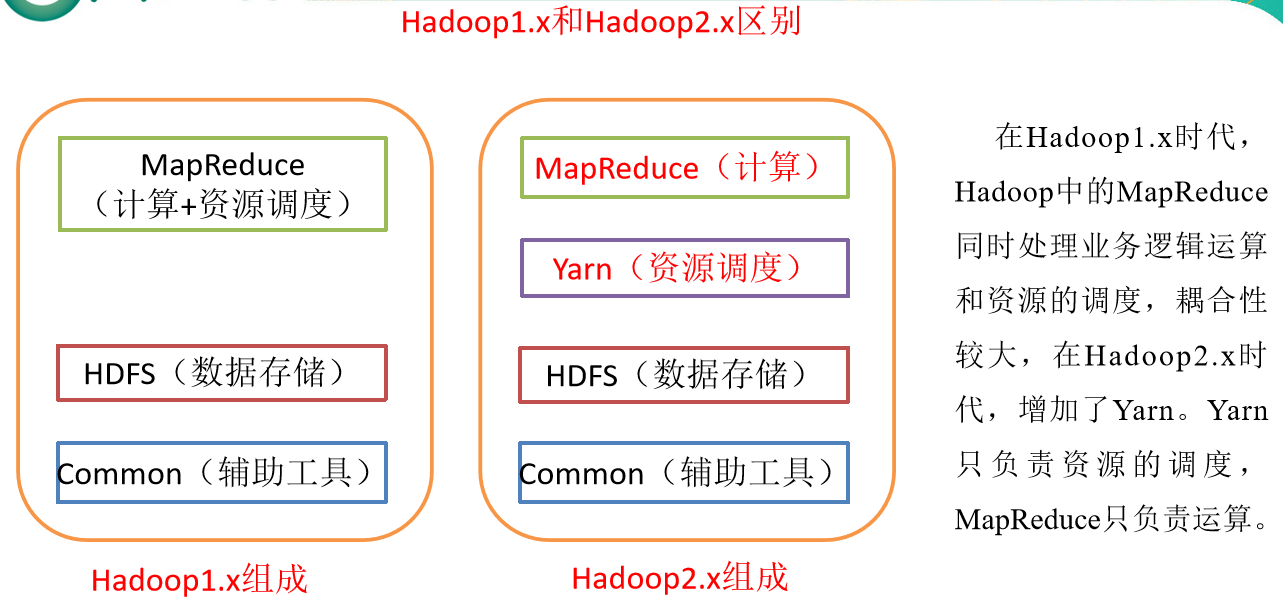
HDFS 遵循主/从架构,由单个 NameNode(NN) 和多个 DataNode(DN) 组成:
NameNode : 负责执行有关 文件系统命名空间 的操作,例如打开,关闭、重命名文件和目录等。 它同时还负责集群元数据的存储,记录着文件中各个数据块的位置信息。
DataNode:负责提供来自文件系统客户端的读写请求,执行块的创建,删除等操作
思考:NameNode中的元数据是存储在哪里的?
首先,我们做个假设,如果存储在NameNode节点的磁盘中,因为经常需要进行随机访问,还有响应客户请求,必然是效率过低
(磁盘IO)。因此,元数据需要存放在内存中。
但如果只存在内存中,一旦断电,元数据丢失,整个集群就无法工作了。因此产生在磁盘中备份元数据的FsImage。
这样又会带来新的问题,当在内存中的元数据更新时,如果同时更新FsImage,就会导致效率过低,但如果不更新,就会发生一致性问题,一旦NameNode节点断电,就会产生数据丢失。因此,引入Edits文件(只进行追加操作,效率很高)。每当元数据有更新或者添加元数据时,修改内存中的元数据并追加到Edits中。这样,一旦NameNode节点断电,可以通过FsImage和Edits的合并,合成元数据。
但是,如果长时间添加数据到Edits中,会导致该文件数据过大,效率降低,而且一旦断电,恢复元数据需要的时间过长。因此,需要定期进行FsImage和Edits的合并,如果这个操作由NameNode节点完成,又会效率过低。因此,引入一个新的节点SecondaryNamenode,专门用于FsImage和Edits的合并。
高可靠-多副本
-
数据存储: 数据块多副本
-
Hadoop分布式文件系统(HDFS)旨在将数据存储在廉价且更不可靠的硬件上。廉价的产品吸引人,但确实引起了人们对整个系统可靠性的担忧,特别是对于确保数据的高可用性。
提前计划灾难,HDFS的头脑决定了系统的设置决定,以便该系统可以存储每个数据块的三个(count'em-三个)副本。
HDFS假定每个磁盘驱动器和每个从属节点本质上都不可靠,因此,显然,在选择存储数据块的三个副本的位置时必须格外小心。
HDFS 将每一个文件存储为一系列块,每个块由多个副本来保证容错,块的大小和复制 因子可以自行配置(默认情况下,块大小是 128M,默认复制因子是 3)。
机架感知
在大多数情况下,副本系数是3,HDFS的存放策略:
如果请求来自本地集群,那么是将第一个副本存放在本地机架的节点上,另一个副本放在同一机架的另一个节点上,最后一个副本放在不同机架的节点上。
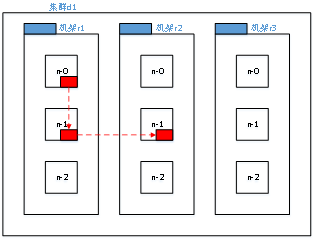
这种策略减少了机架间的数据传输,这就提高了写操作的效率。机架的错误远远比节点的错误少,所以这个策略不会影响到数据的可靠性和可用性。于此同时,因为数据块只放在两个(不是三个)不同的机架上,所以此策略减少了读取数据时需要的网络传输总带宽。在这种策略下,副本并不是均匀分布在不同的机架上。三分之一的副本在一个节点上,三分之二的副本在一个机架上,其他副本均匀分布在剩下的机架中,这一策略在不损害数据可靠性和读取性能的情况下改进了写的性能。
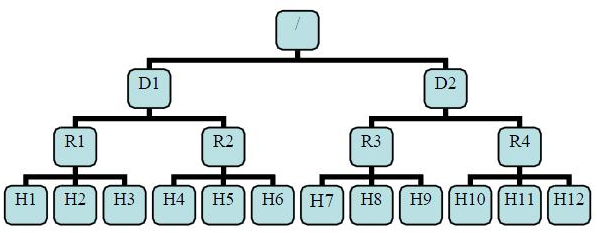
有了机架感知,NameNode就可以画出上图所示的Datanode网络拓扑图。D1,R1都是交换机,最底层是datanode。则H1的rackid=/D1/R1/H1,H1的parent是R1,R1的是D1。这些rackid信息可以通过topology.script.file.name配置。有了这些rackid信息就可以计算出任意两台datanode之间的距离。
distance(/D1/R1/H1,/D1/R1/H1)=0 相同的datanode distance(/D1/R1/H1,/D1/R1/H2)=2 同一rack下的不同datanode distance(/D1/R1/H1,/D1/R1/H4)=4 同一IDC下的不同datanode distance(/D1/R1/H1,/D2/R3/H7)=6 不同IDC下的datanodeHDFS里面,DataNode上的块大小默认是128MB或256MB原因
原因:(普通文件系统的数据块大小一般为4KB)减少硬盘寻道时间(disk seek time)
HDFS设计为持大容量的流式数据操作,所以即使是一般的数据读写操作,涉及到的数据量都是比较大的。
假如数据块设置过小,那需要读取的数据块就比较多,由于数据块在硬盘上非连续存储,
普通硬盘因为需要移动磁头,所以随机寻址较慢,读越多的数据块就增大了总的硬盘寻道时间。当硬盘寻道时间比数据传输时间还要长的多时,那么硬盘寻道时间就成了系统的一个瓶颈。合适的块大小有助于减少硬盘,寻道时间,提高系统吞吐量。
NameNode内存消耗
对于HDFS,他只有一个Namenode节点,他的内存相对于Datanode来说,是极其有限的。
然而,Namenode需要在其内存FSImage文件中中记录在Datanode中的数据块等元数据信息,假如数据块大小设置过少,而需要维护的数据块信息就会过多,那Namenode的内存可能就会伤不起了
如果设置过大,那么从磁盘传输数据的时间 会明显大于定位这个Block块的时间,导致程序处理数据时会非常慢。
磁盘IO
这里先简单介绍一下磁盘IO,磁盘读取数据靠的是机械运动,每次读取数据花费的时间可以分为寻道时间、旋转延迟、传输时间三个部分,寻道时间指的是磁臂移动到指定磁道所需要的时间,主流磁盘一般在5ms以下;旋转延迟就是我们经常听说的磁盘转速,比如一个磁盘7200转,表示每分钟能转7200次,也就是说1秒钟能转120次,旋转延迟就是1/120/2 = 4.17ms;传输时间指的是从磁盘读出或将数据写入磁盘的时间,一般在零点几毫秒,相对于前两个时间可以忽略不计。那么访问一次磁盘的时间,即一次磁盘IO的时间约等于5+4.17 = 9ms左右,听起来还挺不错的,但要知道一台500 -MIPS(Million Instructions Per Second)的机器每秒可以执行5亿条指令,因为指令依靠的是电的性质,换句话说执行一次IO的时间可以执行约450万条指令,数据库动辄十万百万乃至千万级数据,每次9毫秒的时间,显然是个灾难。
数据分块-多副本回顾
高可靠-容错
常见错误类型
节点/通讯故障-心跳机制
在 Hadoop Name节点和数据节点中,使用Heartbeat进行通信 。因此,“心跳”是数据节点在常规时间间隔后发送到名称节点的信号,以指示其存在(即,表示它还处于活动状态)。
如果在心跳一定时间后,名称节点未收到来自数据节点的任何响应,则该特定数据节点以前被声明为已死。
默认的心跳间隔为3秒。如果HDFS 中的DataNode在 十分钟内未将心跳发送到NameNode,则NameNode认为该DataNode停止服务,并且该 DataNode托管的 Blocks副本不可用。然后,NameNode计划在其他DataNode上创建这些块的新副本。
从DataNode接收心跳信号的NameNode还携带诸如总存储容量,正在使用的存储比例以及当前正在进行的数据传输数量之类的信息。对于NameNode的块分配和负载平衡决策,我们使用这些统计信息。
基于Apache文档:
1)dfs.heartbeat.interval的默认值为3,以秒为单位。
2)dfs.blockreport.intervalMec的默认值为21600000,以毫秒为单位。
HDFS默认的超时时间为10分钟+30秒。
这里暂且定义超时时间为timeout
计算公式为:
timeout = 2 * heartbeat.recheck.interval + 10 * dfs.heartbeat.interval
数据损坏-校验和
由于存储设备故障以及网络传输等原因,存储在 DataNode 上的数据块也会发生损坏。为了避免读取到已经损坏的数 据而导致错误,HDFS 提供了数据完整性校验机制来保证数据的完整性。
具体操作如下: 当客户端创建 HDFS 文件时,它会 计算文件的每个块的 校验和 ,并将 校验和 存储在同一 HDFS 命名空 间下的单独的隐藏文件中。当客户端检索文件内容时,它会验证从每个 DataNode 接收的数据是否与存 储在关联校验和文件中的 校验和 匹配。如果匹配失败,则证明数据已经损坏,此时客户端会选择从其 他 DataNode 获取该块的其他可用副本。
- 高扩展性
- 存储/计算资源不够时,可以横向的线性扩展机器
- 一个集群中可以包含数以千计的节点
- 集群可以使用廉价机器,成本低
HDFS读数据回顾
HDFS shell 操作
-
调用文件系统(FS)Shell命令应使用 bin/hadoop fs
的形式 -
ls
使用方法:hadoop fs -ls
如果是文件,则按照如下格式返回文件信息:
文件名 <副本数> 文件大小 修改日期 修改时间 权限 用户ID 组ID
如果是目录,则返回它直接子文件的一个列表,就像在Unix中一样。目录返回列表的信息如下:
目录名修改日期 修改时间 权限 用户ID 组ID
示例:
hadoop fs -ls /user/hadoop/file1 /user/hadoop/file2 hdfs://host:port/user/hadoop/dir1 /nonexistentfile
返回值:
成功返回0,失败返回-1。 -
text
使用方法:hadoop fs -text
将源文件输出为文本格式。允许的格式是zip和TextRecordInputStream。
-
mv
使用方法:hadoop fs -mv URI [URI …]
将文件从源路径移动到目标路径。这个命令允许有多个源路径,此时目标路径必须是一个目录。不允许在不同的文件系统间移动文件。
示例:- hadoop fs -mv /user/hadoop/file1 /user/hadoop/file2
- hadoop fs -mv hdfs://host:port/file1 hdfs://host:port/file2 hdfs://host:port/file3 hdfs://host:port/dir1
返回值:
成功返回0,失败返回-1。
-
put
使用方法:hadoop fs -put
... 从本地文件系统中复制单个或多个源路径到目标文件系统。也支持从标准输入中读取输入写入目标文件系统。
- hadoop fs -put localfile /user/hadoop/hadoopfile
- hadoop fs -put localfile1 localfile2 /user/hadoop/hadoopdir
- hadoop fs -put localfile hdfs://host:port/hadoop/hadoopfile
- hadoop fs -put - hdfs://host:port/hadoop/hadoopfile
从标准输入中读取输入。
返回值:
成功返回0,失败返回-1。
-
rm
使用方法:hadoop fs -rm URI [URI …]
删除指定的文件。只删除非空目录和文件。请参考rmr命令了解递归删除。
示例:- hadoop fs -rm hdfs://host:port/file /user/hadoop/emptydir
返回值:
成功返回0,失败返回-1。
-
2.4.1 HDFS shell操作练习
-
在centos 中创建 test.txt
touch test.txt -
在centos中为test.txt 添加文本内容
vi test.txt -
在HDFS中创建 hadoop001/test 文件夹
hadoop fs -mkdir -p /hadoop001/test -
把text.txt文件上传到HDFS中
hadoop fs -put test.txt /hadoop001/test/ -
查看hdfs中 hadoop001/test/test.txt 文件内容
hadoop fs -cat /hadoop001/test/test.txt -
将hdfs中 hadoop001/test/test.txt文件下载到centos
hadoop fs -get /hadoop001/test/test.txt test.txt -
删除HDFS中 hadoop001/test/
hadoop fs -rm -r /hadoop001
Hadoop YARN
: A framework for job scheduling and cluster resource management.(资源调度系统)
-
YARN: Yet Another Resource Negotiator
-
负责整个集群资源的管理和调度
-
YARN特点:扩展性&容错性&多框架资源统一调度
作用:
协调多个框架(SparkStorm...)共同访问HDFS存储。
架构:
- ResourceManager: RM 资源管理器
整个集群同一时间提供服务的RM只有一个,负责集群资源的统一管理和调度
处理客户端的请求: submit, kill
监控我们的NM,一旦某个NM挂了,那么该NM上运行的任务需要告诉我们的AM来如何进行处理 - NodeManager: NM 节点管理器
整个集群中有多个,负责自己本身节点资源管理和使用
定时向RM汇报本节点的资源使用情况
接收并处理来自RM的各种命令:启动Container
处理来自AM的命令 - ApplicationMaster: AM
每个应用程序对应一个:MR、Spark,负责应用程序的管理
为应用程序向RM申请资源(core、memory),分配给内部task
需要与NM通信:启动/停止task,task是运行在container里面,AM也是运行在container里面 - Container 容器: 封装了CPU、Memory等资源的一个容器,是一个任务运行环境的抽象
- Client: 提交作业 查询作业的运行进度,杀死作业
- ResourceManager: RM 资源管理器
1,Client提交作业请求
2,ResourceManager 进程和 NodeManager 进程通信,根据集群资源,为用户程序分配第一个Container(容器),并将 ApplicationMaster 分发到这个容器上面
3,在启动的Container中创建ApplicationMaster
4,ApplicationMaster启动后向ResourceManager注册进程,申请资源
5,ApplicationMaster申请到资源后,向对应的NodeManager申请启动Container,将要执行的程序分发到NodeManager上
6,Container启动后,执行对应的任务
7,Tast执行完毕之后,向ApplicationMaster返回结果
8,ApplicationMaster向ResourceManager 请求kill
Hadoop MapReduce
: A YARN-based system for parallel processing of large data sets.
- 分布式计算框架
- 源于Google的MapReduce论文,论文发表于2004年12月
- MapReduce是GoogleMapReduce的开源实现
- MapReduce特点:扩展性&容错性&海量数据离线处理
- input : 读取文本文件; 2. splitting : 将文件按照行进行拆分,此时得到的 K1 行数, V1 表示对应行的文本内容; 3. mapping : 并行将每一行按照空格进行拆分,拆分得到的 List(K2,V2) ,其中 K2 代表每一个单 词,由于是做词频统计,所以 V2 的值为 1,代表出现 1 次; 4. shuffling:由于 Mapping 操作可能是在不同的机器上并行处理的,所以需要通过 shuffling 将相同 key 值的数据分发到同一个节点上去合并,这样才能统计出最终的结果,此时得到 K2 为 每一个单词, List(V2) 为可迭代集合, V2 就是 Mapping 中的 V2; 5. Reducing : 这里的案例是统计单词出现的总次数,所以 Reducing 对 List(V2) 进行归约求和 操作,最终输出。