HTTP协议简介
HTTP是一个客户端终端(用户)和服务器端(网站)请求和应答的标准(TCP)。通过使用网
页浏览器、网络爬虫或者其它的工具,客户端发起一个HTTP请求到服务器上指定端口(默认端
口为80. 我们称这个客户端为用户代理程序(user agent)。应答的服务器上存储着一些资源,
比如HTML文件和图像。我们称这个应答服务器为源服务器(origin server)。在用户代理和源
服务器中间可能存在多个“中间层”,比如代理服务器、网关或者隧道(tunnel)。
尽管TCP/IP协议是互联网上最流行的应用,HTTP协议中,并没有规定必须使用它或它支持的
层。事实上,HTTP可以在任何互联网协议上,或其他网络上实现。HTTP假定其下层协议提供
可靠的传输。因此,任何能够提供这种保证的协议都可以被其使用。因此也就是其在TCP/IP协
议族使用TCP作为其传输层。
通常,由HTTP客户端发起一个请求,创建一个到服务器指定端口(默认是80端口)的TCP连
接。HTTP服务器则在那个端口监听客户端的请求。一旦收到请求,服务器会向客户端返回一个
状态,比如"HTTP/1.1 200 OK",以及返回的内容,如请求的文件、错误消息、或者其它信息。
HTTP工作原理
HTTP 默认端口是80 ; HTTPs默认端口是443
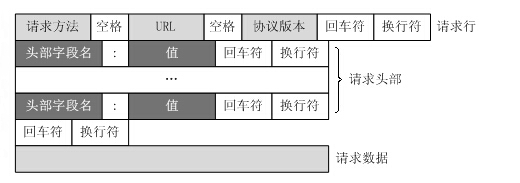
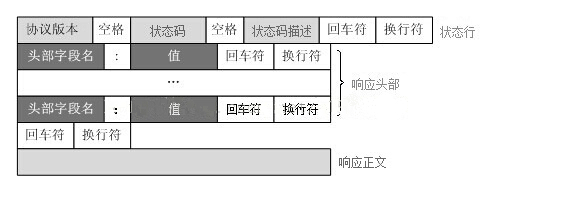
HTTP协议定义Web客户端如何从Web服务器请求Web页面,以及服务器如何把Web页面传送给客户端。HTTP协议采用了请求/响应模型。客户端向服务器发送一个请求报文,请求报文包含请求的方法、URL、协议版本、请求头部和请求数据。服务器以一个状态行作为响应,响应的内容包括协议的版本、成功或者错误代码、服务器信息、响应头部和响应数据。
以下是 HTTP 请求/响应的步骤:
1. 客户端连接到Web服务器
一个HTTP客户端,通常是浏览器,与Web服务器的HTTP端口(默认为80)建立一个TCP套接字连接。例如,http://www.baidu.com。
2. 发送HTTP请求
通过TCP套接字,客户端向Web服务器发送一个文本的请求报文,一个请求报文由请求行、请求头部、空行和请求数据4部分组成。
3. 服务器接受请求并返回HTTP响应
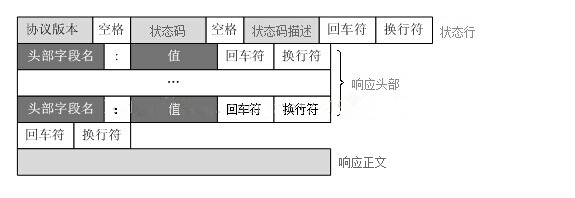
Web服务器解析请求,定位请求资源。服务器将资源复本写到TCP套接字,由客户端读取。一个响应由状态行、响应头部、空行和响应数据4部分组成。
4. 释放连接TCP连接
若connection 模式为close,则服务器主动关闭TCP连接,客户端被动关闭连接,释放TCP连接;若connection 模式为keepalive,则该连接会保持一段时间,在该时间内可以继续接收请求;
5. 客户端浏览器解析HTML内容
客户端浏览器首先解析状态行,查看表明请求是否成功的状态代码。然后解析每一个响应头,响应头告知以下为若干字节的HTML文档和文档的字符集。客户端浏览器读取响应数据HTML,根据HTML的语法对其进行格式化,并在浏览器窗口中显示。
例如:在浏览器地址栏键入URL,按下回车之后会经历以下流程:
- 浏览器向 DNS 服务器请求解析该 URL 中的域名所对应的 IP 地址;
- 解析出 IP 地址后,根据该 IP 地址和默认端口 80,和服务器建立TCP连接;
- 浏览器发出读取文件(URL 中域名后面部分对应的文件)的HTTP 请求,该请求报文作为 TCP 三次握手的第三个报文的数据发送给服务器;
- 服务器对浏览器请求作出响应,并把对应的 html 文本发送给浏览器;
- 释放 TCP连接;
- 浏览器将该 html 文本并显示内容;
HTTP请求方法
HTTP/1.1 协议中一共定义了八种方法(也叫'动作') 来以不同方式操作指定的资
源:
get : 向指定的资源发出'显示'请求.使用get方法应该只用在读取资源数据,而不
应该被用于产生'副作用'的操作中,例如在Web Application中.其中一个原因是
get可能会被网络蜘蛛等随意访问.
head :与get方法一样,都是向服务器发出指定资源的请求.只不过服务器将不传
回资源的文本部分.它的好处在于,使用这个方法可以在不必传输全部内容的情
况下,就可以获取其中'关于该资源的信息'(元信息或元数据).
post : 向指定资源提交数据,请求服务器进行处理(例如提交表单或者上传文件).
数据被包含在请求本文中,这个请求可能会创建新的资源或修改现有资源,或二
者皆有.
put : 向指定资源位置上传其最新内容.
delete : 请求服务器删除 request-url所以标识的资源.
trace : 回显服务器收到的请求,主要用于测试或诊断.
options : 这个方法可以使服务器传回该资源所支持的所有HTTP请求方法.用 *
来代替资源名称,向Web服务器发送options请求,可以测试服务器功能是否正常
运作.
connect : HTTP/1.1 协议中预留给能够将连接改为管道方式的代理服务器.通常
用于ssl加密服务器的连接(仅有非加密的HTTP代理服务武器).
注意:
- 方法名称是区分大小写的。当某个请求所针对的资源不支持对应的请求方法的时候,服务器应当返回状态码405(Method Not Allowed),当服务器不认识或者不支持对应的请求方法的时候,应当返回状态码501(Not Implemented)。
- HTTP服务器至少应该实现GET和HEAD方法,其他方法都是可选的。当然,所有的方法支持的实现都应当匹配下述的方法各自的语义定义。此外,除了上述方法,特定的HTTP服务器还能够扩展自定义的方法。例如PATCH(由 RFC 5789 指定的方法)用于将局部修改应用到资源.
HTTP状态码
所有HTTP响应的第一行都是状态行,依次是当前HTTP版本号,3位数组成的状
态代码,以及描述的短语,彼此由空格分隔.
状态码的第一个数字代表当前响应的类型:
-
- 1xx消息——请求已被服务器接收,继续处理
- 2xx成功——请求已成功被服务器接收、理解、并接受
- 3xx重定向——需要后续操作才能完成这一请求
- 4xx请求错误——请求含有词法错误或者无法被执行
- 5xx服务器错误——服务器在处理某个正确请求时发生错误
虽然RFC2616中已经推荐了描述状态的短语,例如'200 OK','404 Not Found',
但是WEB开发者仍然能够自行决定采用何种短语,用以显示本地化的状态描述
或者自定义信息.
URL
超文本传输协议(HTTP)的统一资源定位符将从因特网获取的五个基本元素包
括在一个简单的地址中:
- 传送协议。
- 层级URL标记符号(为[//],固定不变)
- 访问资源需要的凭证信息(可省略)
- 服务器。(通常为域名,有时为IP地址)
- 端口号。(以数字方式表示,若为HTTP的默认值“:80”可省略)
- 路径。(以“/”字符区别路径中的每一个目录名称)
- 查询。(GET模式的窗体参数,以“?”字符为起点,每个参数以“&”隔开,再以“=”分开参数名称与数据,通常以UTF8的URL编码,避开字符冲突的问题)
- 片段。以“#”字符为起点
例:http://baidu.com:80/news/index.html?id=250&page=1 其中:
http,是协议; www.baidu.com 是服务器;
80 是服务器上的网络端口; /news/index.html 是路径;
?id=250&page=1 是查询;
大多数网页浏览器不要求用户输入网页中“http://”的部分,因为绝大多数网页内容是超文本传输协议文件。同样,“80”是超文本传输协议文件的常用端口号,因此一般也不必写明。一般来说用户只要输入统一资源定位符的一部分(www.luffycity.com:80/news/index.html?id=250&page=1)就可以了。
由于超文本传输协议允许服务器将浏览器重定向到另一个网页地址,因此许多服务器允许用户省略网页地址中的部分,比如 www。从技术上来说这样省略后的网页地址实际上是一个不同的网页地址,浏览器本身无法决定这个新地址是否通,服务器必须完成重定向的任务。
请求和响应
HTTP协议中:
浏览器给服务端发送消息的过程叫请求
服务端给浏览器回复消息的过程叫响应.
HTTP请求格式
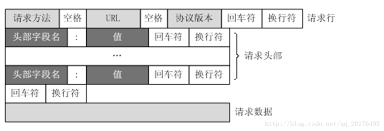
HTTP响应格式

Web开发的本质:
互联网上俩台机器之间通信: ip 端口 协议
浏览器输入URL 回车返回页面的过程:
域名->DNS解析->ip地址->服务端->返回消息->浏览器
服务器把写好的HTML页面,返回给浏览器,浏览器按照HTML格式渲染(显示)
web框架
web本质就是一个socket服务端,而用户浏览器就是一个socket客户端.但是不
同的浏览器(客户端)就有不同的规则,所以在与服务端互动时就需要统一格式,
HTTP协议主要规定可客户端与服务器之间的通信格式.
首先看服务端接收到的消息:
import socket
sk = socket.socket()
sk.bind(("127.0.0.1", 80))
sk.listen()
while True:
conn, addr = sk.accept()
data = conn.recv(8096)
print(data) # 将浏览器发来的消息打印出来
conn.send(b"OK")
conn.close()
输出
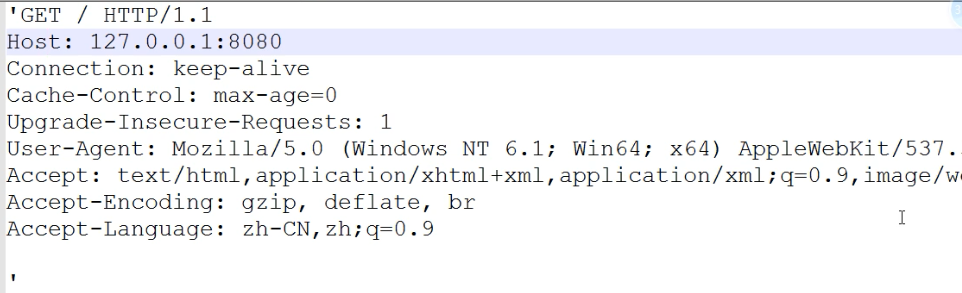
b'GET / HTTP/1.1
Host: 127.0.0.1:8080
Connection: keep-alive
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.186 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8
DNT: 1
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9
Cookie: csrftoken=RKBXh1d3M97iz03Rpbojx1bR6mhHudhyX5PszUxxG3bOEwh1lxFpGOgWN93ZH3zv '
再看访问博客园时浏览器收到的响应消息:
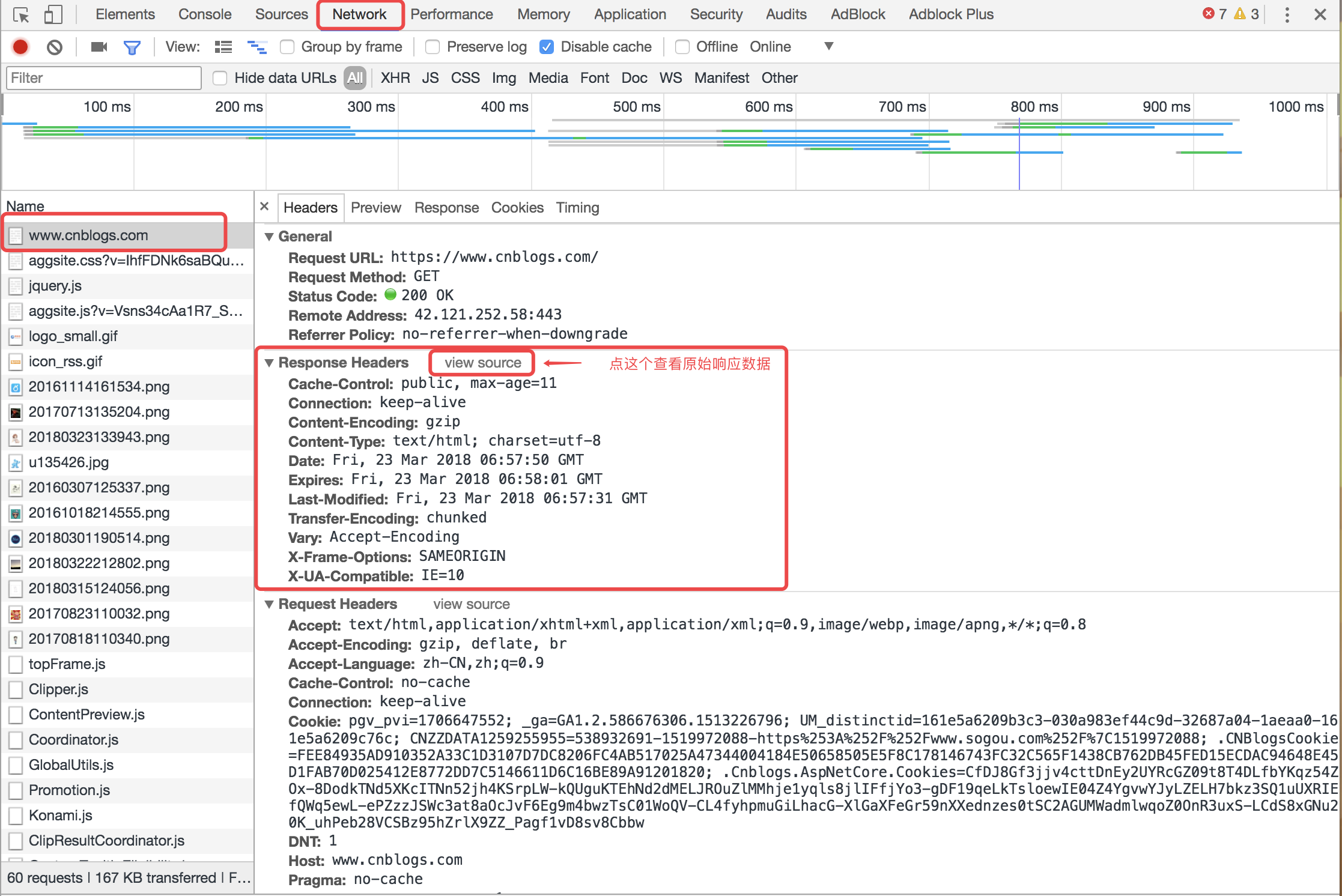
点击view source之后显示如下图:

HTTP协议对收发消息的格式要求:
每个HTTP请求和响应都遵循相同格式,一个HTTP包含header和body俩部
分,其中body是可选的.HTTP响应的header中有一个content-type表明响应
的内容格式.如:text/html 表示HTML网页.
HTTP GET请求格式:
HTTP响应格式:
自定义web框架
import socket
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.bind(('127.0.0.1', 8000))
sock.listen()
while True:
conn, addr = sock.accept()
data = conn.recv(8096)
# 给回复的消息加上响应状态行
conn.send(b"HTTP/1.1 200 OK
")
conn.send(b"OK")
conn.close()
根据不同的路径返回不同的内容:
"""
根据URL中不同的路径返回不同的内容
"""
import socket
sk = socket.socket()
sk.bind(("127.0.0.1", 8080)) # 绑定IP和端口
sk.listen() # 监听
while 1:
# 等待连接
conn, add = sk.accept()
data = conn.recv(8096) # 接收客户端发来的消息
# 从data中取到路径
data = str(data, encoding="utf8") # 把收到的字节类型的数据转换成字符串
# 按
分割
data1 = data.split("
")[0]
url = data1.split(' ')[1] # url是我们从浏览器发过来的消息中分离出的访问路径
conn.send(b'HTTP/1.1 200 OK
') # 因为要遵循HTTP协议,所以回复的消息也要加状态行
# 根据不同的路径返回不同内容
if url == "/index/":
response = b"index"
elif url == "/home/":
response = b"home"
else:
response = b"404 not found!"
conn.send(response)
conn.close()
根据不同的路径返回不同内容(函数版)
"""
根据URL中不同的路径返回不同的内容--函数版
"""
import socket
sk = socket.socket()
sk.bind(("127.0.0.1", 8080)) # 绑定IP和端口
sk.listen() # 监听
# 将返回不同的内容部分封装成函数
def index(url):
s = "这是{}页面!".format(url)
return bytes(s, encoding="utf8")
def home(url):
s = "这是{}页面!".format(url)
return bytes(s, encoding="utf8")
while 1:
# 等待连接
conn, add = sk.accept()
data = conn.recv(8096) # 接收客户端发来的消息
# 从data中取到路径
data = str(data, encoding="utf8") # 把收到的字节类型的数据转换成字符串
# 按
分割
data1 = data.split("
")[0]
url = data1.split()[1] # url是我们从浏览器发过来的消息中分离出的访问路径
conn.send(b'HTTP/1.1 200 OK
') # 因为要遵循HTTP协议,所以回复的消息也要加状态行
# 根据不同的路径返回不同内容,response是具体的响应体
if url == "/index/":
response = index(url)
elif url == "/home/":
response = home(url)
else:
response = b"404 not found!"
conn.send(response)
conn.close()
根据不同的路径返回不同的内容(函数进阶)
"""
根据URL中不同的路径返回不同的内容--函数进阶版
"""
import socket
sk = socket.socket()
sk.bind(("127.0.0.1", 8080)) # 绑定IP和端口
sk.listen() # 监听
# 将返回不同的内容部分封装成函数
def index(url):
s = "这是{}页面!".format(url)
return bytes(s, encoding="utf8")
def home(url):
s = "这是{}页面!".format(url)
return bytes(s, encoding="utf8")
# 定义一个url和实际要执行的函数的对应关系
list1 = [
("/index/", index),
("/home/", home),
]
while 1:
# 等待连接
conn, add = sk.accept()
data = conn.recv(8096) # 接收客户端发来的消息
# 从data中取到路径
data = str(data, encoding="utf8") # 把收到的字节类型的数据转换成字符串
# 按
分割
data1 = data.split("
")[0]
url = data1.split()[1] # url是我们从浏览器发过来的消息中分离出的访问路径
conn.send(b'HTTP/1.1 200 OK
') # 因为要遵循HTTP协议,所以回复的消息也要加状态行
# 根据不同的路径返回不同内容
func = None # 定义一个保存将要执行的函数名的变量
for i in list1:
if i[0] == url:
func = i[1]
break
if func:
response = func(url)
else:
response = b"404 not found!"
# 返回具体的响应消息
conn.send(response)
conn.close()
让网页动态起来
选择使用字符串替换来实现这个需求(这里使用时间戳来模拟动态数据)
"""
根据URL中不同的路径返回不同的内容--函数进阶版
返回HTML页面
让网页动态起来
"""
import socket
import time
sk = socket.socket()
sk.bind(("127.0.0.1", 8080)) # 绑定IP和端口
sk.listen() # 监听
# 将返回不同的内容部分封装成函数
def index(url):
with open("index.html", "r", encoding="utf8") as f:
s = f.read()
now = str(time.time())
s = s.replace("@@oo@@", now) # 在网页中定义好特殊符号,用动态的数据去替换提前定义好的特殊符号
return bytes(s, encoding="utf8")
def home(url):
with open("home.html", "r", encoding="utf8") as f:
s = f.read()
return bytes(s, encoding="utf8")
# 定义一个url和实际要执行的函数的对应关系
list1 = [
("/index/", index),
("/home/", home),
]
while 1:
# 等待连接
conn, add = sk.accept()
data = conn.recv(8096) # 接收客户端发来的消息
# 从data中取到路径
data = str(data, encoding="utf8") # 把收到的字节类型的数据转换成字符串
# 按
分割
data1 = data.split("
")[0]
url = data1.split()[1] # url是我们从浏览器发过来的消息中分离出的访问路径
conn.send(b'HTTP/1.1 200 OK
') # 因为要遵循HTTP协议,所以回复的消息也要加状态行
# 根据不同的路径返回不同内容
func = None # 定义一个保存将要执行的函数名的变量
for i in list1:
if i[0] == url:
func = i[1]
break
if func:
response = func(url)
else:
response = b"404 not found!"
# 返回具体的响应消息
conn.send(response)
conn.close()
python web框架分类
a. 收发socket消息 , 按照HTTP协议解析消息 web服务
wsgiref,gunicorn,uWSGI
b. 字符串替换
c.业务逻辑处理
web 应用程序:
自己实现 a b c 的 tornado
自己实现b c 使用别人a Django
自己实现c 使用别人的a b flask
安装:
在py的安装文件中找出scripts文件夹,shift+右键 打开powershell:
pip install django==1.11.11
创建Django项目:
在cmd命令行中创建: django-admin startproject 项目名
在pycharm中创建: 专业版(自己建) 非专业版(没有)
在命令行中运行 Django项目:
Python manage.py runserver 127.0.0.1:8000(默认本机端口,可自己
设置)
停止 : Ctrl + c
目录介绍:
mysite/
├── manage.py # 管理文件
└── mysite # 项目目录
├── __init__.py
├── settings.py # 配置
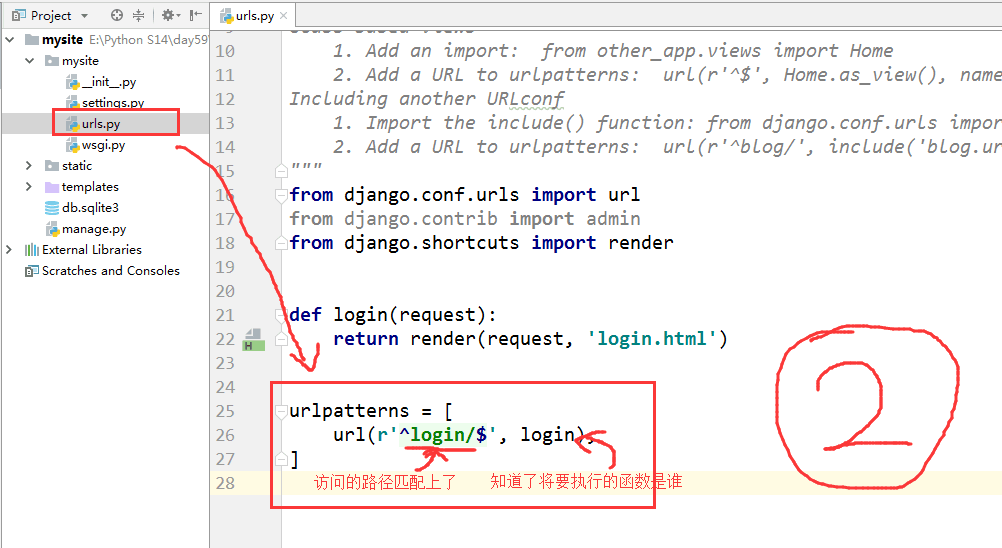
├── urls.py # 路由 --> URL和函数的对应关系
└── wsgi.py # runserver命令就使用wsgiref模块做简单的web server
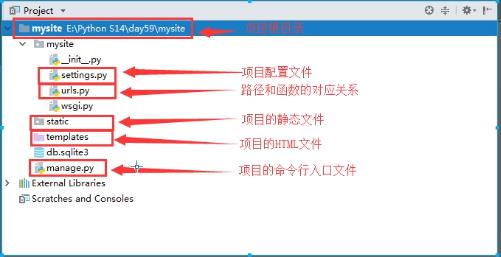
db.sqlite3 Django 开发环境默认的文件数据库
模板文件配置(配置调用的文件路径):
#跟html相关的文件配置
TEMPLATES = [
{
'BACKEND': 'django.template.backends.django.DjangoTemplates',
'DIRS': [os.path.join(BASE_DIR, "template")],# 路径拼接 BASE_DIR(指项目的根目录)和template文件
'APP_DIRS': True,
'OPTIONS': {
'context_processors': [
'django.template.context_processors.debug',
'django.template.context_processors.request',
'django.contrib.auth.context_processors.auth',
'django.contrib.messages.context_processors.messages',
],
},
},
]
静态文件配置(js css images等文件路径):
在调用时能够依次查找需要调用的文件了路径
STATIC_URL = '/static/' # HTML中使用的静态文件夹前缀
STATICFILES_DIRS = [
os.path.join(BASE_DIR, "static"), # 静态文件存放位置,进行静态文件编辑可以在static文件中进行。
]
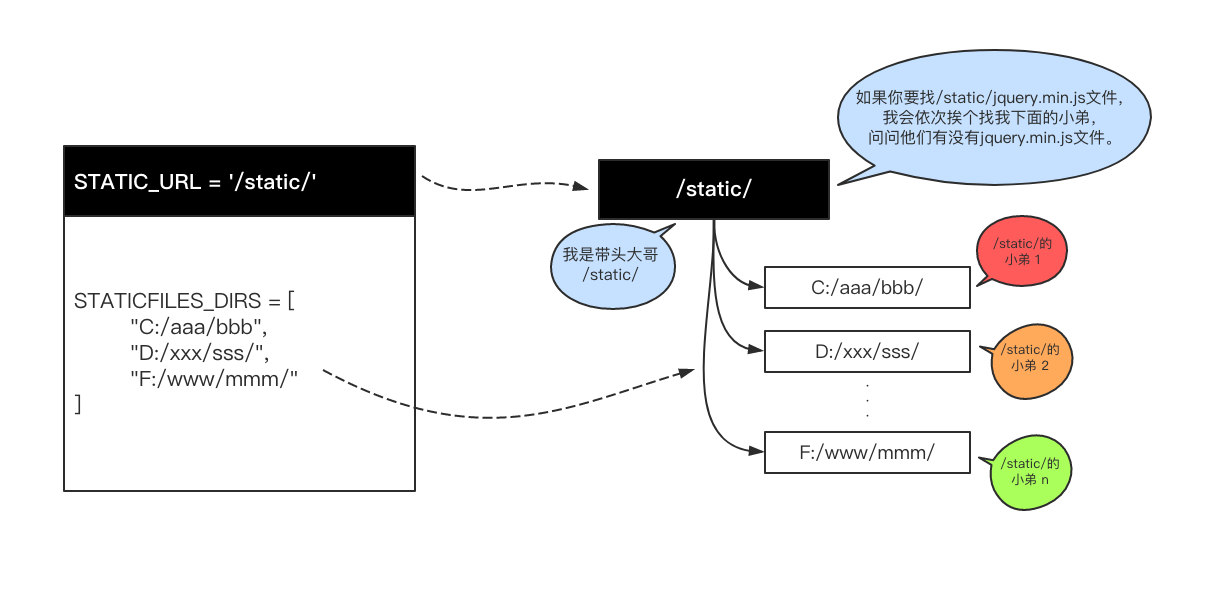
Django三种基础模块
from django.shortcuts import HttpResponse, render, redirect
HttpResponse 内部传入一个字符串参数,返回给浏览器.
例如:
def index(request):
#业务逻辑
return HttpResponse('ok')
render
除request参数外还接受一个待渲染的模板文件和一个保存具体数据的字典参数。
将数据填充进模板文件,最后把结果返回给浏览器。
def index(request):
# 业务逻辑代码
return render(request, "index.html", {"name": "alex", "hobby": ["烫头", "泡吧"]})
redirect
接受一个URL参数 , 表示跳转到指定的URL.
def index(request):
# 业务逻辑代码
return redirect("/home/")
重新定向
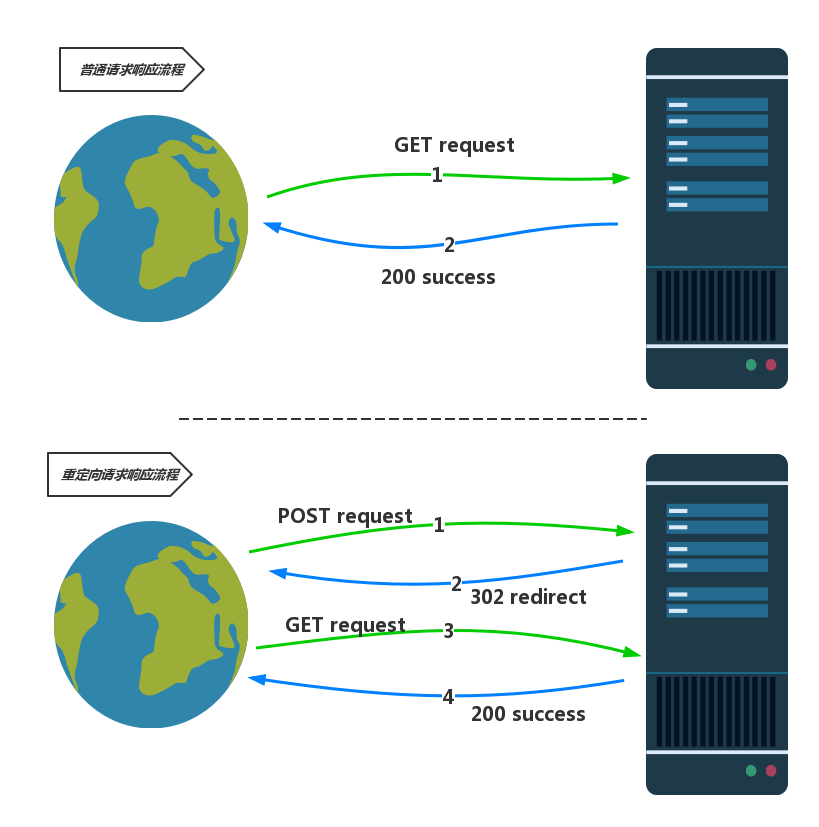
普通请求响应: 浏览器发一个消息,服务器回一个
重定向请求响应: 浏览器发一个消息,服务器发一个跳转的消息,浏览器
根据这条消息向服务器发送请求,服务器再返回一条信息.
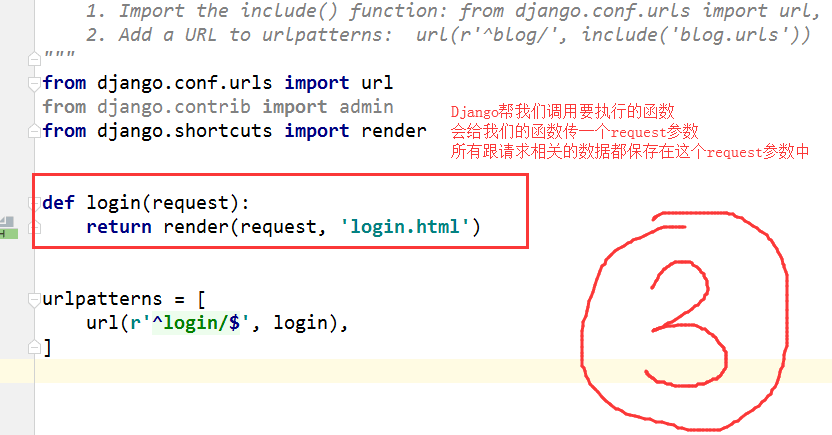
浏览器(客户端)与服务端的交互过程:
---浏览器发送请求(地址栏输入URL)
--- 根据URL匹配要访问的路径即查找要执行的函数
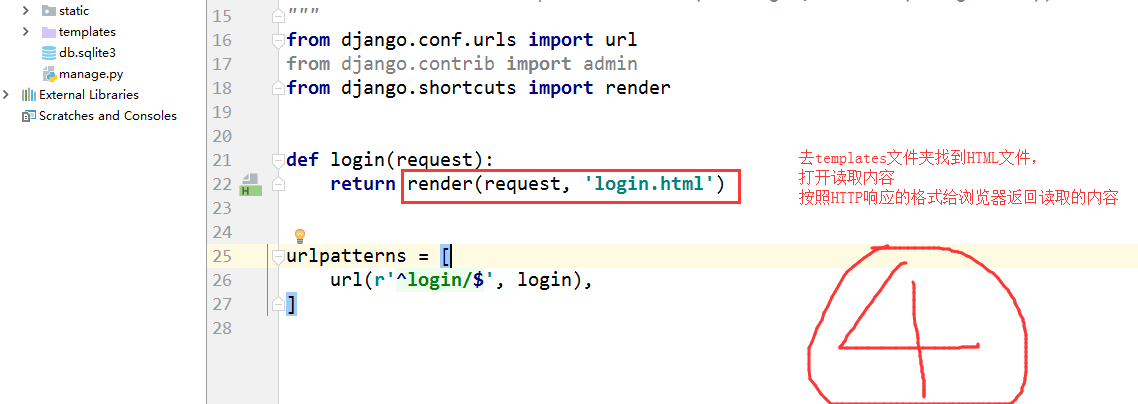
--- Django找到调用的函数,把与请求相关的数据由request参数进行传输.
--- 去指定文件夹找到相关文件,打开读取内容,按照HTTP响应的格式给浏
览器返回读取内容
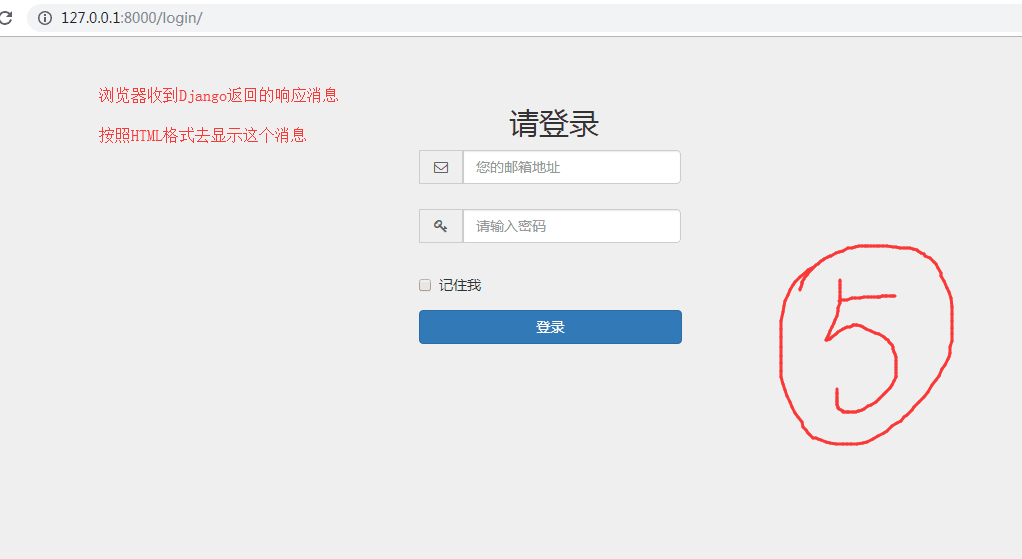
--- 浏览器收到返回的响应消息并按照HTTP格式显示消息.
form表单提交数据的三个要素:
1. form表单标签必须要有action和method属性;
action键的值表示html页面中信息的提交地址, method键的值表示用什
么方法提交
2. 所有获取用户输入的标签必须放在form表单中,必须要有name属性;
name键的值表示要提交的信息
3. 必须要有submit按钮.
request相关属性:
request是指浏览器给服务端发送的请求.
1. request.method --返回的是请求的方法(全大写):GET POST...
注意:观看method源码得知:
![]()
在HTML页面中经常会有 method='post' 之类的对method规定获取值时为小写,此时
大小写都可以,当从method中取值时,'upper'会把method中的请求方法全部大写.
2. request.GET --取得URL里的参数,类似于字典的数据结构(如果用get方
法提交,就要用GET获取)
3. request.POST -- form表单提交的数据,类似于字典的数据结构(若用post方法
提交就要用POST获取)
Django的模板语言
{{变量名}}
连接mysql
使用ORM(Object Relationship Model)来翻译SQL语句.
优点: 开发效率高 ; 开发不用直接写SQL语句
缺点: 执行效率低
Django项目中创建app应用
在项目中创建一个Python包,不同的功能放在不同的包里,
创建app -- Python manage.py startapp app名称(例:app01)
在Django中表明创建了一个app :
在settings.py中找到INSTALLED_APPS,添加新建的app

Django中ORM的使用
用处: 操作数据表 操作数据行
使用:
1. 手动创建一个数据库(ORM不能创建数据库) --- create database
mysite;
2. 在Django中表明要连接的数据库

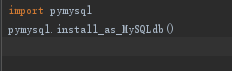
3. 表明连接数据库的途径 (利用第三方的包)
在Django中表明用pymysql模块代替默认的MySQLdb去连接MySQL
数据库:
在settings.py同级的_init_.py文件中配置:
4. 在app应用下的models.py文件中创建类(类名自定),该类必须继承
models.Model,可以用ORM语言在创建的类中编写表结构

5. 在Terminal中执行命令与句,完成对数据库中表的操作
python manage.py makemigrations -- 记录models.py中的变更,更新要
对数据库进行的操作
python manage.py migrate -- 把变更记录翻译成SQL语句,在数据库中
完成操作.
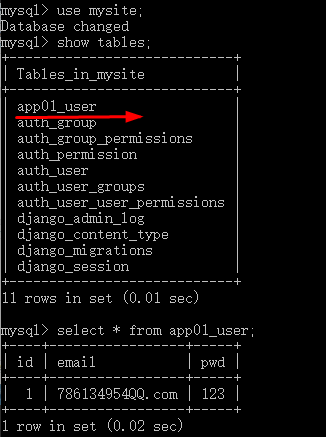
连接数据库
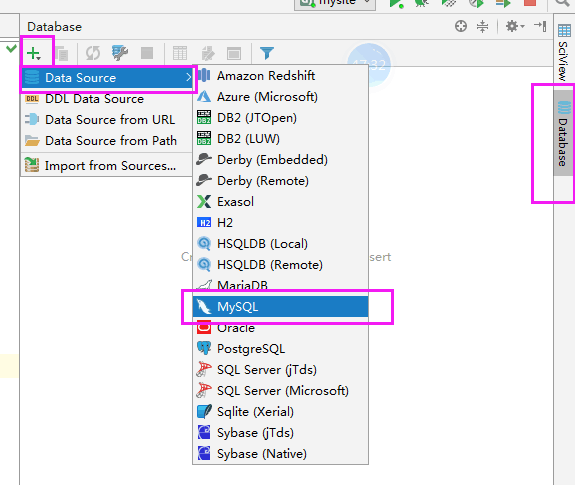
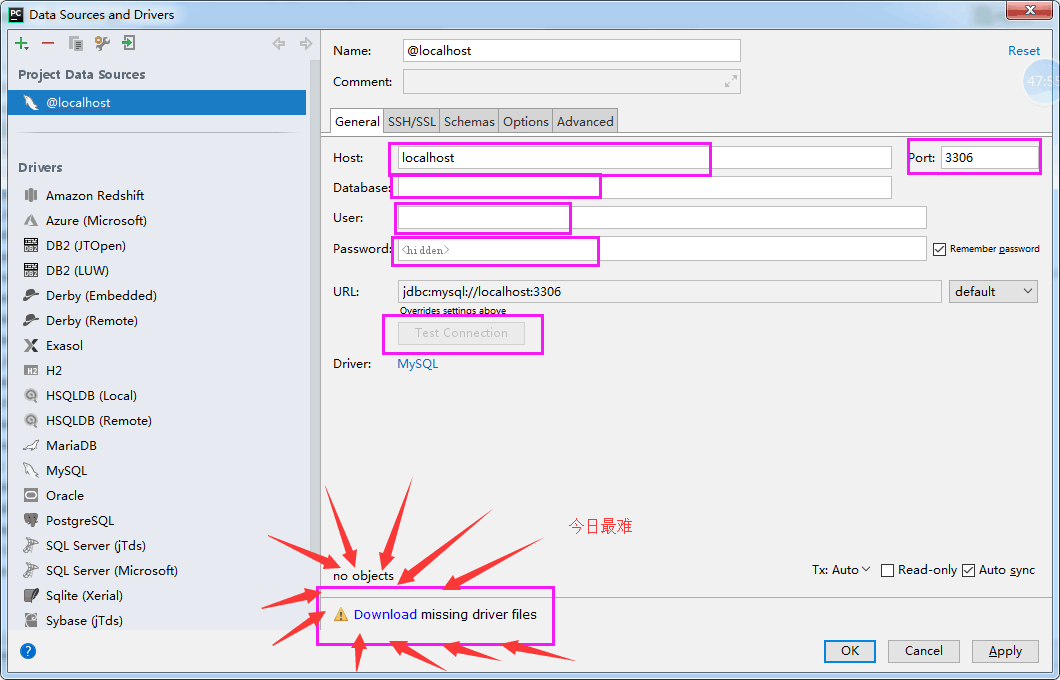
点击database 创建数据库,连接数据库:

ORM查询
User.objects.filter(email='', pwd='')