作者|PURVA HUILGOL
编译|VK
来源|Analytics Vidhya
机器理解文本的挑战
“语言是一种极好的交流媒介”
你和我很快就会明白那句话。但机器根本无法处理原始形式的文本数据。他们需要我们将文本分解成一种易于机器阅读的数字格式(自然语言处理背后的理念!)。
这就引入“词袋”(BoW)和TF-IDF。BoW和TF-IDF都是帮助我们将文本句子转换为向量的技术。
在这篇文章中,我将讨论“词袋”和TF-IDF。我们将使用一个直观和一般的例子来详细理解每个概念。
示例
我将用一个流行的例子来解释本文中的Bag of Words(BoW)和TF-IDF。
我们都喜欢看电影(不同程度)。在我决定看一部电影之前,我总是先看它的影评。我知道你们很多人也这么做!所以,我在这里用这个例子。
以下是关于某部恐怖电影的评论示例:
-
点评一:This movie is very scary and long
-
点评二:This movie is not scary and is slow
-
点评三:This movie is spooky and good
你可以看到关于这部电影的一些对比评论,以及电影的长度和节奏。想象一下看一千篇这样的评论是多么枯燥。显然,我们可以从中汲取很多有趣的东西,并以此为基础来衡量电影的表现。
然而,正如我们在上面看到的,我们不能简单地把这些句子交给机器学习模型,让它告诉我们一篇评论是正面的还是负面的。我们需要执行某些文本预处理步骤。
“词袋”和TF-IDF就是两个这样做的例子。让我们详细了解一下。
从文本创建向量
你能想出一些我们可以在一开始就把一个句子向量化的技巧吗?基本要求是:
-
它不应该导致稀疏矩阵,因为稀疏矩阵会导致高计算成本
-
我们应该能够保留句子中的大部分语言信息
词嵌入是一种利用向量表示文本的技术。还有2种单词嵌入形式是:
-
Bow,代表词袋
-
TF-IDF,代表词频-逆文本频率
现在,让我们看看如何将上述电影评论表示为嵌入,并为机器学习模型做好准备。
词袋(BoW)模型
词袋(BoW)模型是数字文本表示的最简单形式。像单词本身一样,我们可以将一个句子表示为一个词向量包(一个数字串)。
让我们回顾一下我们之前看到的三种类型的电影评论:
- 点评一:This movie is very scary and long
- 点评二:This movie is not scary and is slow
- 点评三:This movie is spooky and good
我们将首先从以上三篇评论中所有的独特词汇中构建一个词汇表。词汇表由这11个单词组成:“This”、“movie”、“is”、“very”、“stear”、“and”、“long”、“not”、“slow”、“spooky”、“good”。
现在,我们可以将这些单词中的每一个用1和0标记在上面的三个电影评论中。这将为我们提供三个用于三个评论的向量:
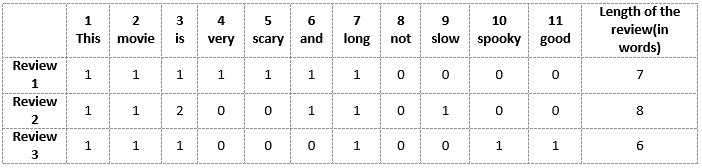
点评向量1:[1 1 1 1 1 1 0 0 0 0]
点评向量2:[1 1 2 0 0 1 0 1 0 0 0]
点评向量3:[1 1 1 0 0 0 1 0 1 1 1 1]
这就是“词袋”(BoW)模型背后的核心思想。
使用单词包(BoW)模型的缺点
在上面的例子中,我们可以得到长度为11的向量。然而,当我们遇到新的句子时,我们开始面临一些问题:
-
如果新句子包含新词,那么我们的词汇量就会增加,因此向量的长度也会增加。
-
此外,向量还包含许多0,从而产生稀疏矩阵(这是我们希望避免的)
-
我们没有保留任何关于句子语法和文本中单词顺序的信息。
词频-逆文本频率(TF-IDF)
我们先对TF-IDF下一个正式定义。百科是这样说的:
“TF-IDF(term frequency–inverse document frequency)是一种用于信息检索与数据挖掘的常用加权技术。TF是词频(Term Frequency),IDF是逆文本频率指数(Inverse Document Frequency)”
术语频率(TF)
首先让我们理解术语频繁(TF)。它是衡量一个术语t在文档d中出现的频率:
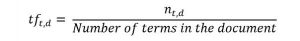
这里,在分子中,n是术语“t”出现在文档“d”中的次数。因此,每个文档和术语都有自己的TF值。
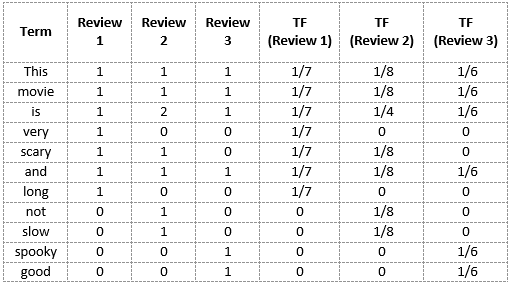
我们再次使用我们在词袋模型中构建的相同词汇表来演示如何计算电影点评2:
点评 2: This movie is not scary and is slow
这里
-
词汇:“This”,“movie”,“is”,“very”,“stear”,“and”,“long”,“not”,“slow”,“spooky”,“good”
-
点评2的单词数=8
-
单词“this”的TF=(点评2中出现“this”的次数)/(点评2中的单词数)=1/8
同样地
- TF(‘movie’) = 1/8
- TF(‘is’) = 2/8 = 1/4
- TF(‘very’) = 0/8 = 0
- TF(‘scary’) = 1/8
- TF(‘and’) = 1/8
- TF(‘long’) = 0/8 = 0
- TF(‘not’) = 1/8
- TF(‘slow’) = 1/8
- TF( ‘spooky’) = 0/8 = 0
- TF(‘good’) = 0/8 = 0
我们可以这样计算所有点评的词频:
逆文本频率(IDF)
IDF是衡量一个术语有多重要的指标。我们需要IDF值,因为仅计算TF不足以理解单词的重要性:
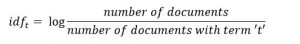
我们可以计算点评2中所有单词的IDF值:
IDF('this')=log(文档数/包含“this”一词的文档数)=log(3/3)=log(1)=0
同样地,
- IDF(‘movie’, ) = log(3/3) = 0
- IDF(‘is’) = log(3/3) = 0
- IDF(‘not’) = log(3/1) = log(3) = 0.48
- IDF(‘scary’) = log(3/2) = 0.18
- IDF(‘and’) = log(3/3) = 0
- IDF(‘slow’) = log(3/1) = 0.48
我们可以计算每个单词的IDF值。因此,整个词汇表的IDF值为:
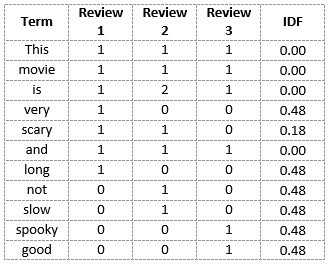
因此,我们看到“is”、“this”、“and”等词被降为0,代表重要性很小;而“scary”、“long”、“good”等词则更为重要,因而具有更高的权值。
我们现在可以计算语料库中每个单词的TF-IDF分数。分数越高的单词越重要,分数越低的单词越不重要:
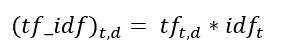
现在,我们可以计算点评2中每个单词的TF-IDF分数:
TF-IDF(‘this’, Review 2) = TF(‘this’, Review 2) * IDF(‘this’) = 1/8 * 0 = 0
同样地
- TF-IDF(‘movie’, Review 2) = 1/8 * 0 = 0
- TF-IDF(‘is’, Review 2) = 1/4 * 0 = 0
- TF-IDF(‘not’, Review 2) = 1/8 * 0.48 = 0.06
- TF-IDF(‘scary’, Review 2) = 1/8 * 0.18 = 0.023
- TF-IDF(‘and’, Review 2) = 1/8 * 0 = 0
- TF-IDF(‘slow’, Review 2) = 1/8 * 0.48 = 0.06
同样地,我们可以计算出对于所有评论的所有单词的TF-IDF分数:
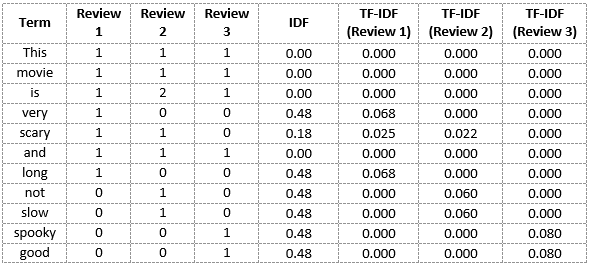
我们现在已经获得了我们词汇的TF-IDF分数。TF-IDF还为频率较低的单词提供较大的值,并且当IDF和TF值都较高时,该值较高。TF-IDF分值高代表该单词在所有文档中都很少见,但在单个文档中很常见。
结尾
让我总结一下我们在文章中所讨论的内容:
-
词袋只创建一组向量,其中包含文档中的单词出现次数,而TF-IDF模型还包含关于更重要的单词和不重要的单词的信息。
-
词袋向量很容易解释。然而,在机器学习模型中,TF-IDF通常表现得更好。
虽然“词袋”和“TF-IDF”在各自方面都很受欢迎,但在理解文字背景方面仍然存在空白。检测单词“spooky”和“scary之间的相似性,或者将给定的文档翻译成另一种语言,需要更多关于文档的信息。
这就有关于Word2Vec、CBOW、Skip-gram等词嵌入技术的由来。
原文链接:https://www.analyticsvidhya.com/blog/2020/02/quick-introduction-bag-of-words-bow-tf-idf/
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/