作者|Dimas Adnan
编译|VK
来源|Towards Data Science
在本文中,我想写一篇关于如何使用Python和Jupyter Notebook构建预测模型的文章。我在这个实验中使用的数据是来自Kaggle的酒店预订需求数据集:https://www.kaggle.com/jessemostipak/hotel-booking-demand
在本文中,我将只向你展示建模阶段,仅使用Logistic回归模型,但是你可以访问完整的文档,包括在Github上进行的数据清理、预处理和探索性数据分析。
导入库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_report
import warnings
warnings.filterwarnings("ignore")
加载数据集
df = pd.read_csv('hotel_bookings.csv')
df = df.iloc[0:2999]
df.head()
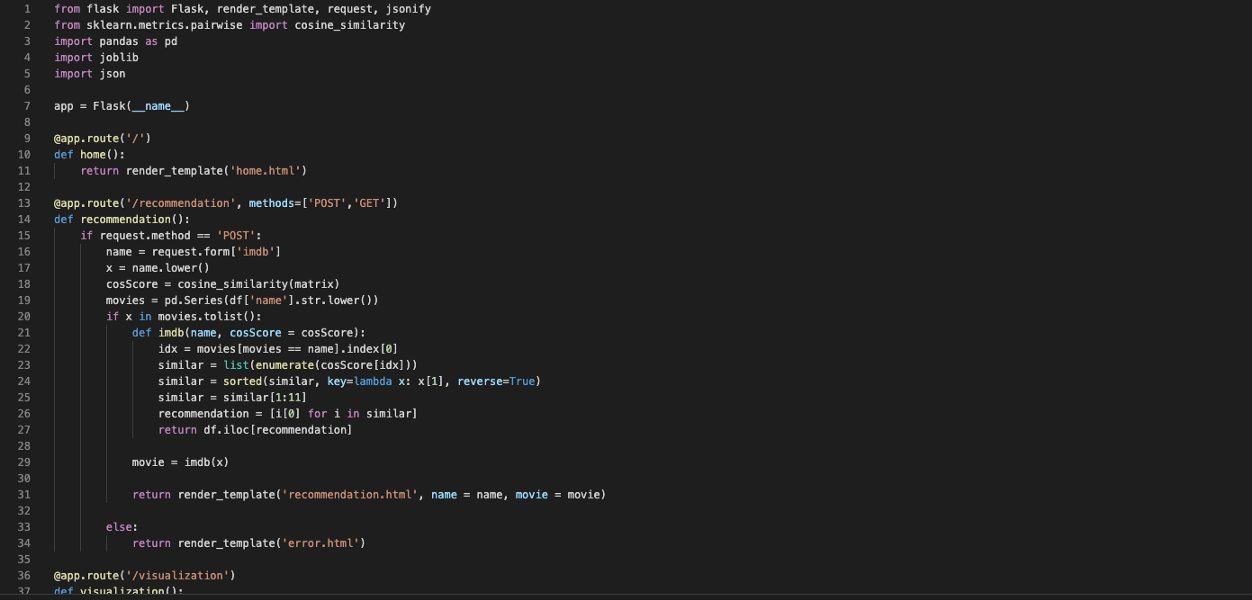
下面是数据集的外观。
它有32列,它的完整版本是:
['hotel', 'is_canceled', 'lead_time', 'arrival_date_year',
'arrival_date_month', 'arrival_date_week_number',
'arrival_date_day_of_month', 'stays_in_weekend_nights',
'stays_in_week_nights', 'adults', 'children', 'babies', 'meal',
'country', 'market_segment', 'distribution_channel',
'is_repeated_guest', 'previous_cancellations',
'previous_bookings_not_canceled', 'reserved_room_type',
'assigned_room_type', 'booking_changes', 'deposit_type', 'agent',
'company', 'days_in_waiting_list', 'customer_type', 'adr',
'required_car_parking_spaces', 'total_of_special_requests',
'reservation_status', 'reservation_status_date']
根据我在Notebook上运行的信息,数据集中的NaN值可以在“country”、“agent”和“company”三列中找到
基于“lead_time”特征,我将“country”中的NaN值替换为PRT(葡萄牙),因为PRT是最常见的
我试图根据lead_time, arrival_date_month, 和arrival_date_week_number替换“agent”特征上的NaN值,但大多数都是“240”作为最常见的代理。
在我阅读了在互联网上可以找到的数据集的描述和解释后,作者将“agent”特征描述为“预订的旅行社ID”。因此,那些在数据集中拥有“agent”的人是唯一通过旅行社订购的人,而那些没有“agent”或是Nan的人,是那些没有通过旅行社订购的人。因此,我认为最好是用0来填充NaN值,而不是用常见的代理来填充它们,这样会使数据集与原始数据集有所不同。
最后但并非最不重要的是,我选择放弃整个“company”特征,因为该特性中的NaN约占数据的96%。如果我决定修改数据,它可能会对数据产生巨大的影响,并可能会影响整个数据
拆分数据集
df_new = df.copy()[['required_car_parking_spaces','lead_time','booking_changes','adr','adults', 'is_canceled']]
df_new.head()
x = df_new.drop(['is_canceled'], axis=1)
y = df_new['is_canceled']
我试着根据与目标(is_Cancelled)最显著相关的前5个特征对数据集进行拆分,它们是required_car_parking_spaces’, ’lead_time’, ’booking_changes’, ’adr’, ’adults,’ 和‘is_canceled.’
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.20, shuffle=False)
训练和测试分成80%和20%。
拟合模型

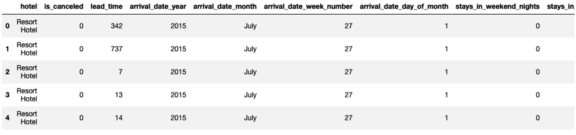
model_LogReg_Asli是在使用超参数调优之前使用Logistic回归的原始模型,下面是模型预测。
模型性能
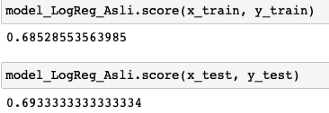
如上所述,Logistic回归模型的准确率约为69.3%。
模型参数
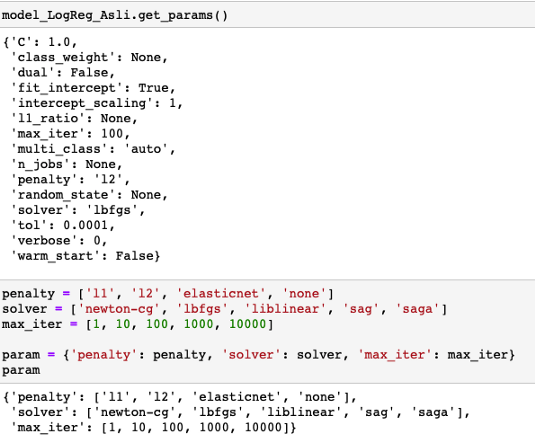
Randomized Search CV的Logistic回归分析
model_LR_RS是采用Logistic回归和超参数调整(随机)的模型。
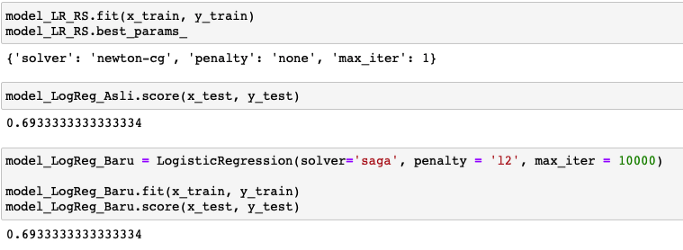
如上图所示,带有Randomized Search CV的Logistic回归模型的结果与没有随机搜索的结果完全相同,为69.3%。
基于网格搜索CV的Logistic回归
model_LR2_GS是采用Logistic回归和超参数调整(网格搜索)的模型。
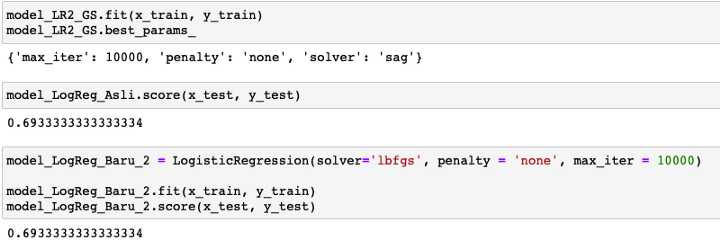
上图显示,使用网格搜索CV的Logistic回归模型具有相同的准确率,为69.3%。
模型评估
混淆矩阵
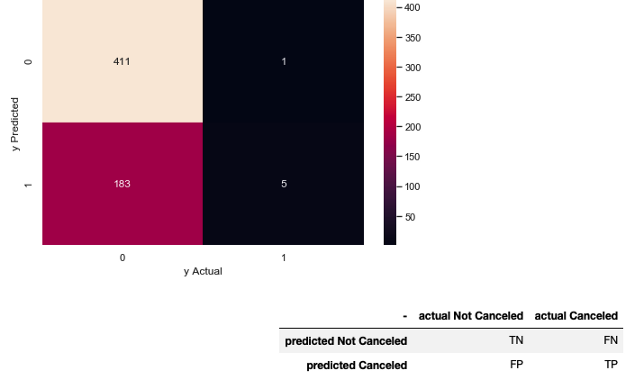
TN为真反例,FN为假反例,FP为假正例,TP为真正例,0不被取消,1被取消。下面是模型的分类报告。
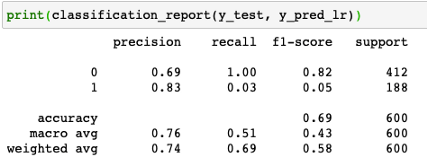
在本文中,我再次使用Logistic回归进行测试,但是你可以使用其他类型的模型,如随机森林、决策树等。在我的Github上,我也尝试过随机森林分类器,但结果非常相似。
本文到此为止。谢谢你,祝你今天愉快。
原文链接:https://towardsdatascience.com/predicting-a-hotel-booking-demand-7608a7dbf5a4
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/