作者|Ankit Goel
编译|VK
来源|Towards Data Science
Pandas是一个强大的开源数据分析和操作库。它可以帮助你对数据进行各种操作,并生成有关它的不同报告。我将把这篇文章分成两篇
-
基本知识-我将在这个故事中介绍。我将介绍Pandas的基本功能,这些功能将使你大致了解如何开始使用Pandas,以及它如何帮助你节省大量时间。
-
高级-将通过高级的功能,使它更容易解决复杂的分析问题。它将涵盖的主题,如风格,绘图,读取多个文件等。第二部分仍在进行中,敬请期待。

在开始之前,确保你已经安装了Pandas。如果没有,你可以使用以下命令下载它。
# 如果你使用的是Anaconda
conda install -c conda-forge pandas
# 使用pip安装Pandas
pip install pandas
# 导入pandas
import pandas as pd
在这个练习中,我将使用著名的泰坦尼克号数据集。我建议你从Github下载数据和notebook,将其复制到你的环境中:https://github.com/ankitgoel1602/data-science/tree/master/data-analysis/pandas
有关数据的更多详细信息,请参阅Kaggle:https://www.kaggle.com/c/titanic/data?select=train.csv。
让我们开始,我试图保持数据分析的一般流程,比如从读取数据开始,然后在数据分析过程中经历不同的步骤。
1.使用read_csv或read_excel读取数据
任何数据分析的起点都是获取数据集。pandas提供不同的函数来读取不同格式的数据。最常用的是
read_csv( )
这允许你读取CSV文件。
pd.read_csv('path_to_your_csv_file.csv')
panda提供了不同的选项来配置列名、数据类型或要读取的行数。查看Pandas read_csv API了解更多详细信息:https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.read_csv.html。

read_excel( )
这允许你读取Excel文件。
pd.read_excel('path_to_your_excel_file.xlsx')
与CSV一样,Pandas为read_excel提供了一组丰富的选项,允许你在excel中读取特定的工作表名称、数据类型或要读取的行数。查看Pandas read_excel API了解更多详细信息:https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.read_excel.html
Pandas支持很多其他数据类型。如果你正在使用其他数据类型,请查看Pandas文档:https://pandas.pydata.org/pandas-docs/stable/reference/io.html
读取泰坦尼克号数据集,我们将在这里使用read_csv命令
# 你可以从提供的Github链接获取它。
# 将Titanic数据集加载到titanic_data中
titanic_data = pd.read_csv('titanic_train.csv')
这将创建一个Pandas数据帧(如表),并将其存储到titanic_data中。
接下来,我们将了解如何获取有关加载的数据的更多详细信息。
2.使用head、tail或sample来探索数据。
一旦我们加载了数据,我们想回顾一下。panda提供了不同的api,我们可以使用它们来探索数据。
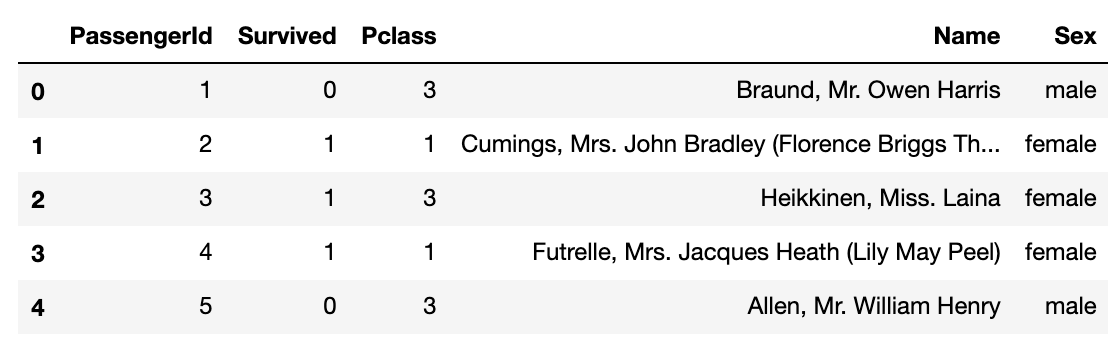
head( )
这类似于SQL中的TOP命令,从数据帧的开始给我们提供前'n'条记录。
# 从数据帧中选择前5(n=5)条记录
titanic_data.head(5)
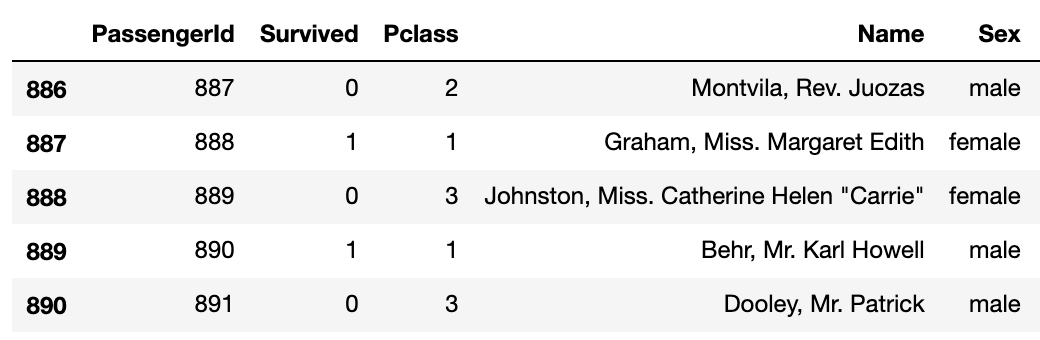
tail( )
这给了我们数据帧末尾的“n”条记录。
# 从数据帧中选择最后5条(n=5)条记录
titanitc_data.tail(5)
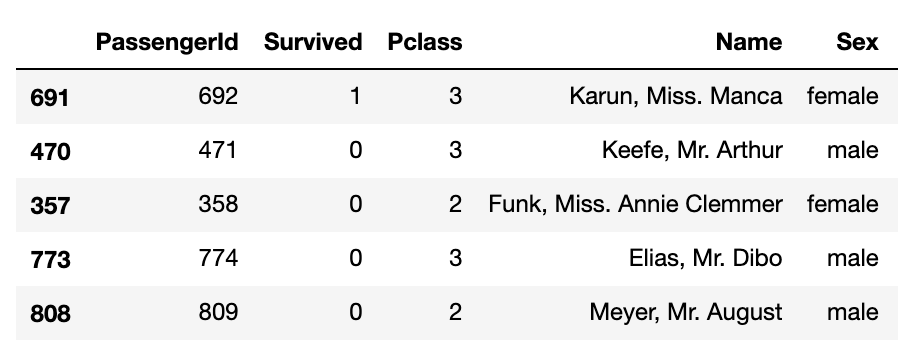
sample( )
这将从数据中随机获取“n”个记录。注意-此命令在不同运行时的输出可能不同。
titanic_data.sample(5)
3.使用shape获取数据维度
一旦我们有了数据,我们就需要知道我们要处理的行或列的数量,而Pandas的shape API提供的正是这些。让我们看看
# dataframe的形状,注意结尾没有括号,因为它是dataframe的属性
titanic_data.shape
(891, 12)
4.使用info( )查看数据摘要
让我们先看看这个的输出
titanic_data.info()

正如你所看到的,“info”提供了一个很好的数据摘要,让我们一个一个地了解它。
-
索引详细信息-Pandas中的每个数据帧都有一个索引,如果你熟悉SQL,它就像是我们创建用来访问数据的索引。这里意味着我们有一个从0到890的范围索引,即总共891行。
-
“info”生成的表中的每一行都向我们提供了有关列的详细信息、列中的值的数量以及pandas分配给它的数据类型。这对于了解缺失数据非常有用。例如我们可以说我们只有714行的“Age”数据。
-
内存使用-Pandas将数据帧加载到内存中,这将告诉我们数据集使用了多少内存。当我们有大的数据集时,这就很方便了。pandas有一个特定的API“memory_usage”来获得更多关于内存的信息。
5.使用describe()的数据统计
这给了我们关于数据集的统计数据。如你所见,我们的数据帧如下所示
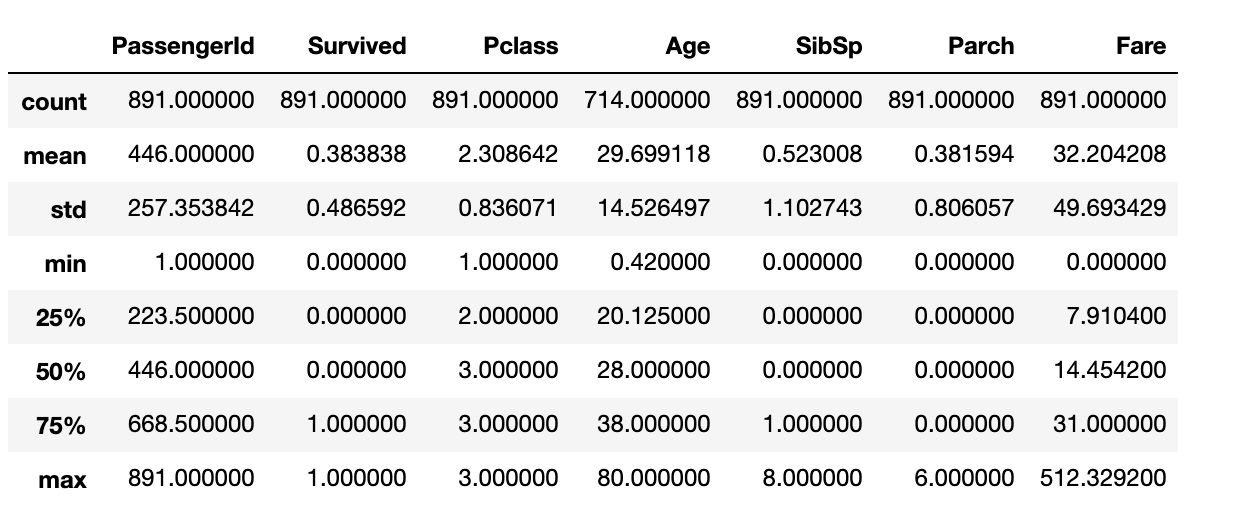
如你所见,它为每一列提供了许多信息,如记录计数(不计算丢失的记录,如年龄)、平均值、标准差、最小值和不同分位数百分比。默认情况下,此命令提供有关数值数据类型(如int或float)的信息。要获取“object”列的统计信息,我们可以运行
# 显示有关对象列的统计信息
titanic_data.describe(include=['O'])

如果你注意到,我们在describe API中添加了'include'参数,它是一个列表,我们可以传递多个值,比如-
-
include=[‘O’, ’int64']-将提供关于DataFrame中Object和int64类型列的统计信息。
-
include=[‘O’, ‘float64’]-将提供关于DataFrame中Object和float64类型列的统计信息。
与“include”类似,我们也可以使用“exclude”,它将在计算统计时排除列类型。如果你对更多细节感兴趣,请参阅Pandas文档:https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.describe.html。
6.使用loc和iloc进行数据选择
这些都是非常有用的函数,可以帮助我们选择数据。使用这些我们可以选择数据的任何部分。为了更好地理解它,让我们更改数据的索引(如果你不理解,请不要担心,我将在第2部分中讨论)。
# 将数据帧的索引从RangeIndex更改为“Ticket”值
titanic_ticket_index = titanic_data.set_index('Ticket')

loc( )
这将根据标签(即列和行的名称)选择数据。例如,在上面的数据中,行标签类似于A/5 21171, PC17599, 113803,列标签类似于PassengerId, Survived, Sex。loc的一般语法是-
dataframe_name.loc[row_labels, column_labels(optional)]
行标签和列标签可以采用不同的值。让我们看一些例子来更好地理解它。
选择单行
输入你想要的行的标签,即,如果我们想选择'Ticket',其中的值是'A/5 21171'。
# 注意我们需要使用[]方括号
# 这将返回与名称匹配的行的数据。
titanic_ticket_index.loc['A/5 21171']

选择多行
很多时候,我们需要选择多行,以便进一步分析。.loc API可以获取要选择的行标签列表,即。
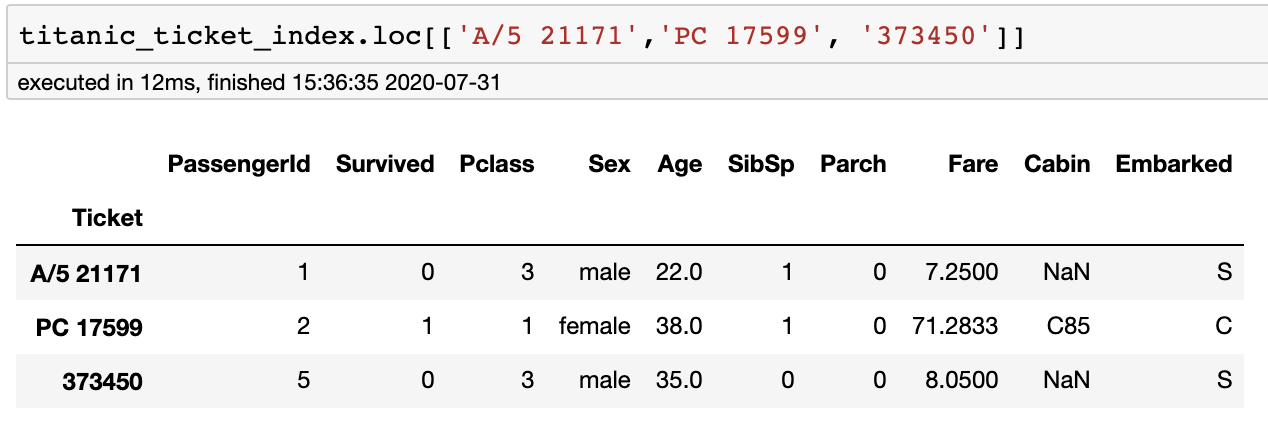
或者类似的
# 我们可以提供 start_label:end_label
# 这里我们选择标签为“PC 17599”到“373450”的行
titanic_ticket_index.loc['PC 17599':'373450']

注意-如果多行具有相同的标签,这将不起作用。
选择单列
这与我们选择行的方式类似,但是在选择列时,我们需要告诉Pandas我们要选择的行。我们可以用“:”代替行标签,这意味着我们要选择所有行。
# 为所有行选择列。
titanic_ticket_index.loc[:,'Embarked']

选择多个列
与我们对多行所做的类似,只需要告诉Pandas我们正在选择哪些行。
# 为所有行选择Sex, Age, Fare, Embarked列 .
titanic_ticket_index.loc[:,['Sex','Age','Fare','Embarked']]

或者类似的
# 我们可以提供start_label:end_label
# 在这里,我们选择的列为 label 'Sex' 到 'Embarked'
titanic_ticket_index.loc[:, 'Sex':'Embarked']
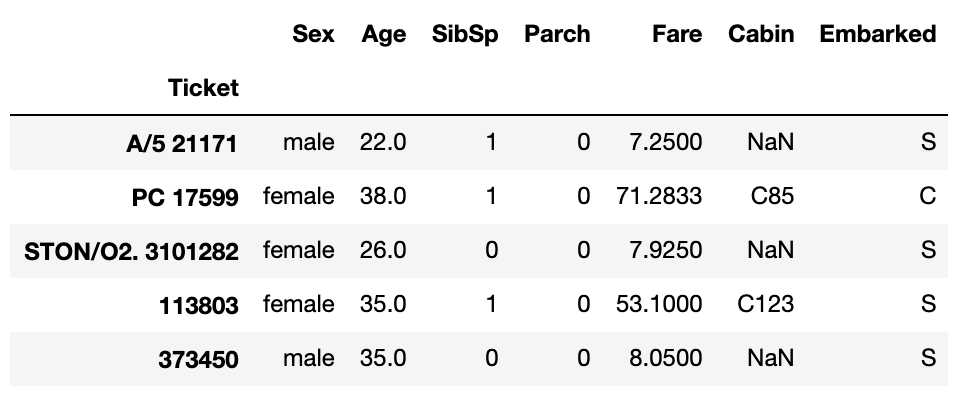
选择特定的行和列

iloc()
这与loc类似,但基于索引而不是标签选择行和列。与标签不同的是,索引总是从0开始,到第7行的数目是1,列的索引总是从0到第1列。
让我们看一个例子
# 选择特定的行和列:示例2
# 对于列和行我们都可以用start_label:end_label
# 选择第3至第6行和第1至第4列
# 结束索引应比所需的行或列大1
titanic_ticket_index.iloc[3:7, 1:5]

在这里,我们没有像对“loc”那样查看示例。如果你想知道我们是如何使用iloc实现同样的结果的,你可以参考Github:https://github.com/ankitgoel1602/data-science/blob/master/data-analysis/pandas/pandas_basic_functions_overview.ipynb
7.在列中使用value_counts()获取唯一值
Value_counts为我们提供列中唯一值的计数,这对于了解以下信息非常有用
-
列中有不同的值。
-
最常见值。
-
最频繁值的比例。
# Sex列的值计数。
titanic_data['Sex'].value_counts()
# 输出
male 577
female 314
Name: Sex, dtype: int64
如你所见,我们的数据集包含了更多的男性。我们甚至可以将其标准化以查看值之间的分布。
# 为性别列计数并标准化
titanic_data['Sex'].value_counts(normalize=True)
#输出
male 0.647587
female 0.352413
Name: Sex, dtype: float64
这意味着,在我们的数据集中,男性与女性的比例约为65:35。
8.使用query( )筛选数据
通常,我们使用难以分析的大型数据集。在这种情况下,策略是过滤不同条件下的数据并对其进行分析。我们只需使用Pandas查询API的一行代码就可以做到这一点。
让我们举几个例子来更好地理解它。
选择年龄>15的行。
# 前5个年龄大于15岁的记录
titanic_data.query('Age > 15').head(5)

选择幸存的男性。
# 前5名幸存的男性
titanic_data.query('Sex=="male" and Survived==1').head(5)
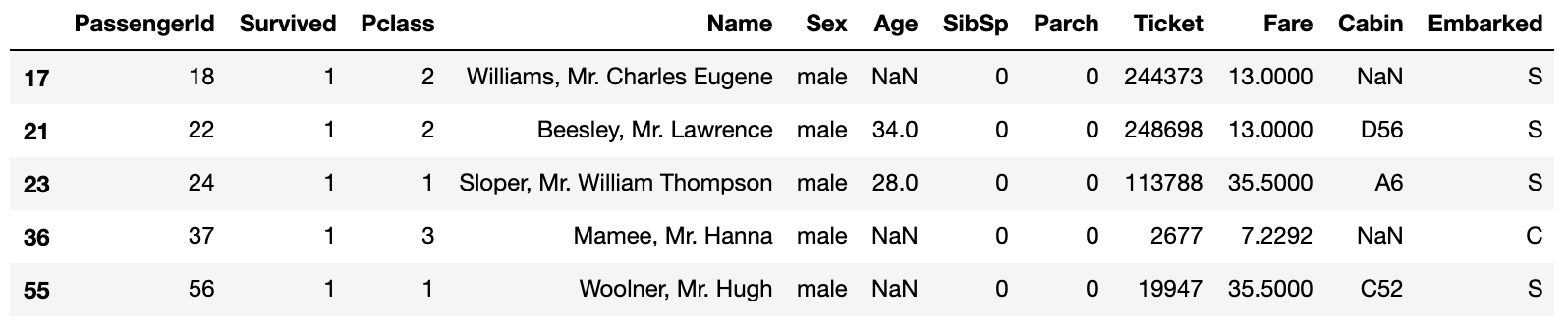
我们可以定义变量并使用它们来编写过滤器查询。当我们需要编写脚本时,它会很方便。
# gender_to_select和min_fare,这些都可以作为参数的一部分传递给脚本
gender_to_select = "female"
min_fare = 50
# 使用传递的属性查询
titanic_data.query('(Sex==@gender_to_select) and (Fare > @min_fare)')

结论
我希望这篇文章能帮助你开始使用Pandas并简化数据分析过程。如前所述,在本文中,我试图涵盖涉及数据分析过程不同领域的基本函数。我将继续补充更多。
Pandas提供了许多不同的api,可以帮助对数据执行高级操作,如绘图、风格等。我将在本系列的第2部分中介绍这些api。
原文链接:https://towardsdatascience.com/pandas-put-away-novice-data-analyst-status-part-1-7e1f0107dae0
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/