作者|Nathan Lambert
编译|VK
来源|Towards Data Science

关于马尔可夫决策过程的马尔可夫是什么?
马尔可夫是安德烈·马尔科夫(Andrey Markov),他是著名的俄罗斯数学家,以其在随机过程中的工作而闻名。

“马尔可夫”通常意味着在当前状态下,未来和过去是独立的。
建立Markovian系统的关键思想是无记忆。无记忆是系统历史不会影响当前状态的想法。用概率表示法,无记忆性转化为这种情况。考虑一系列动作产生的轨迹,我们正在寻找当前动作将带给我们的位置。长的条件概率可能看起来像:

现在如果系统是Markovian,则历史将全部包含在当前状态中。因此,我们的第一步分配要简单得多。

这一步是改变计算效率的规则。马尔可夫性质是所有现代强化学习算法的存在和成功的基础。
马尔可夫决策过程(MDP)
MDP由以下定义:
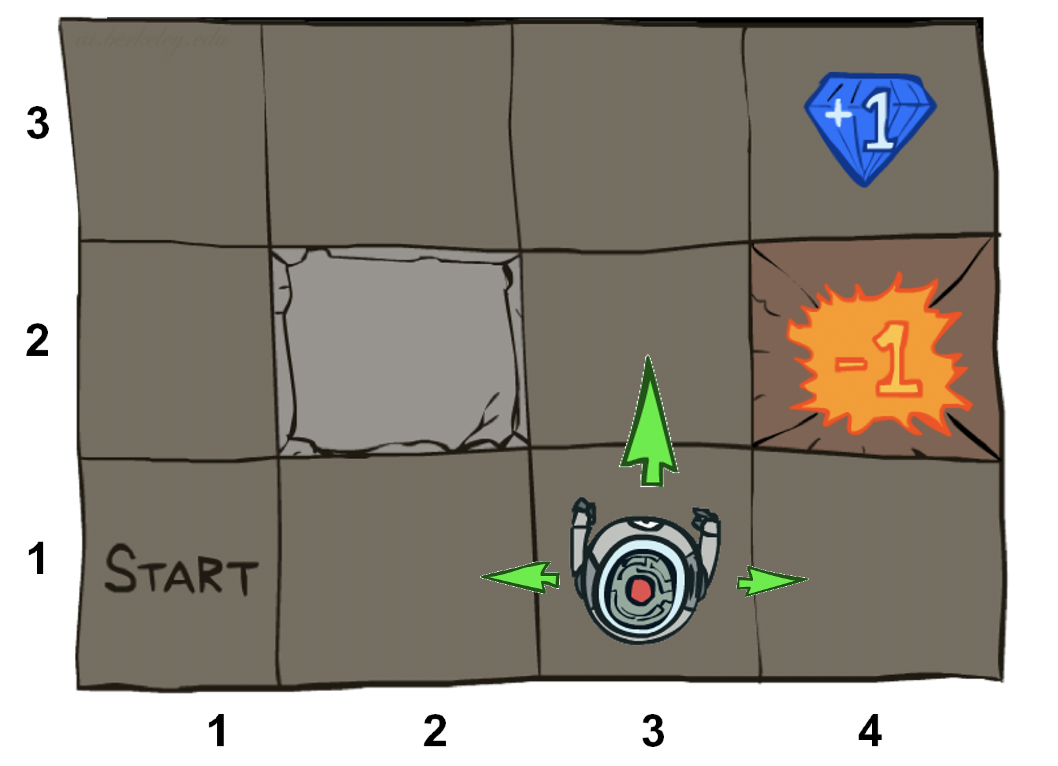
- 状态集$sin S。状态是代理程序所有可能的位置。在下面的示例中,它是机器人位置。
- 一组动作(ain A)。动作是代理可以采取的所有可能动作的集合。在下面的示例中,这些动作的下方是{北,东,南,西}。
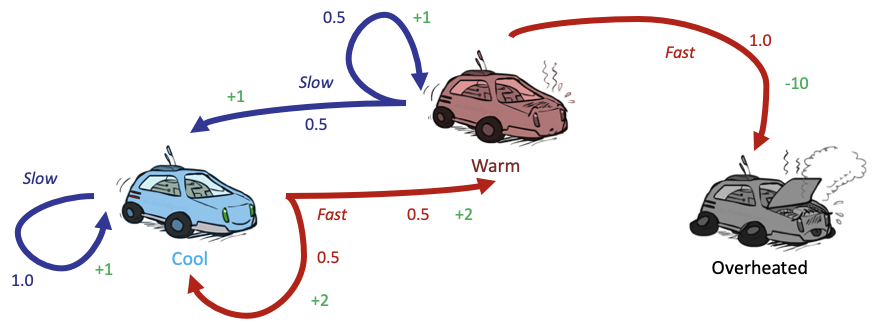
- 转换函数T(s,a,s')。T(s,a,s')保持MDP的不确定性。给定当前位置和给定动作,T决定下一个状态出现的频率。在下面的示例中,转换函数可能是下一个状态在80%的时间内处于目前动作方向,而在其他20%的情况下偏离了90度。在下面的示例中,机器人选择了北,但每个机器人有10%的机会向东或向西移动。
- 奖励函数R(s,a,s')。最大化报酬总额是任何代理的目标。此函数说明每个步骤可获得多少奖励。通常,为鼓励快速解决方案,每个步骤都会有少量的负奖励(成本),而在最终状态下会有较大的正面(成功的任务)或负面(失败的任务)奖励。例如下面的宝石和火坑。
- 开始状态s0,也许是结束状态。
这给了我们什么?
这个定义给我们提供了一个有限的世界,我们建立了前进的模型。我们知道每个转换的确切概率,以及每个动作的效果。最终,该模型是一种方案,我们将在知道自己的操作可能会出现错误的情况下计划如何采取行动。
如果机器人就在火坑旁边,机器人是否应该总是选择北方,但是北方有可能把它送到东边掉入火坑?
不,最佳策略是西方。因为最终进入墙壁将(有20%的机会)向北移动,并使机器人驶向目标。
策略规定
学习如何在未知环境中行动是了解环境的最终目标。在MDP中,这称为策略。
策略是一项函数,可让你根据状态执行操作。π*:S→A.
制定策略的方法很多,但是核心思想是值和策略迭代。这两种方法都可以迭代地为状态(可能是动作)的总效用建立估算。
状态的效用是(折后)奖励的总和。
一旦每个状态都具有效用,那么高层的规划和策略制定就会遵循最大效用的路线。
在MDP和其他学习方法中,模型会添加折扣因子γ来优先考虑短期和长期奖励。折扣因素在直觉上是有道理的。通过将奖励的总和转换成几何级数,折扣因子也带来了巨大的计算收敛性。
原文链接:https://towardsdatascience.com/what-is-a-markov-decision-process-anyways-bdab65fd310c
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/