
机器学习现在是一个热门话题,每个人都在尝试获取有关该主题的任何信息。有了关于机器学习的大量信息,人们可能会不知所措。在这篇文章中,我列出了你需要了解的一些机器学习中最重要的主题,以及一些可以帮助你进一步阅读你感兴趣的主题的资源。
人工智能(AI)
人工智能是计算机科学的一个分支,旨在创建模仿人类行为的智能机器,例如知识,推理,解决问题,感知,学习,计划,操纵和移动对象的能力。
人工智能是计算机科学领域,强调创造像人类一样工作和反应的智能机器。
详细信息查看:
- 人工智能[^1]
- 什么是人工智能?[^2]
机器学习(ML)
机器学习属于AI的范畴,它使系统能够自动学习并从经验中进行改进,而无需进行明确的编程。学习的过程始于观察或数据,例如样本,直接经验或指示,以便根据我们提供的样本寻找数据模式并在将来做出更好的决策。
主要目的是允许计算机在没有人工干预或帮助的情况下自动学习,并相应地调整操作。
详细信息查看:
- 机器学习[^3]
- 什么是机器学习?专家系统的定义[^4]
- AI / ML入门指南[^5]
监督学习
监督学习是一种机器学习任务,它学习基于样本输入输出对将输入映射到输出的函数。监督学习算法会分析训练数据并产生一个推断函数,可用于映射新样本。
在监督学习中,我们标记了训练数据。
详细信息查看:
- 监督学习[^6]
- 监督学习课程视频介绍[^7]
无监督学习
无监督学习是一种机器学习任务,可以从没有标签响应的输入数据组成的数据集中得出推论。无监督学习的目的是为数据中的基础结构或分布建模,以便更多地了解数据。
聚类和关联分析是一些无监督学习子类别。

详细信息查看:
- 无监督学习[^8]
- 什么是无监督机器学习?[^9]
- 监督学习和无监督学习的区别[^10]
神经网络或人工神经网络(ANN)
神经网络是一种受生物启发的编程范式,它使计算机能够从观测数据中学习。人工神经网络的设计受到人脑生物神经网络的启发,其学习过程比标准的机器学习模型要强大得多。
神经网络,也称为人工神经网络,由输入、隐含层和输出层组成,隐含层是由将输入转换为输出层可以使用的内容的单元组成。它们在需要查找模式的任务中表现出色。
详细信息查看:
- 理解神经网络[^11]
- 神经网络和深度学习[^12]
- 什么是神经网络?[^13]
反向传播
这是神经网络中的一个概念,它允许网络在结果与创建者期望的结果不匹配的情况下,调整隐含层神经元对应的权重。
详细信息查看:
- 反向传播[^14]
- 反向传播在人工神经网络是如何工作的?[^15]
深度神经网络(DNN)或深度学习
深度学习是机器学习的一个子集,其中多层神经网络被堆叠起来以创建一个庞大的网络,以将输入映射到输出。它允许网络提取不同的特征,直到可以识别出它正在寻找的内容。
详细信息查看:
- 什么是深度神经网络?[^16]
- 深度神经网络的基础[^17]
- 神经网络与深度学习[^18]
-
线性回归
线性回归是一种基于监督学习的机器学习算法,它用于回归任务。回归基于自变量对目标预测值建模。它主要用于找出自变量与预测之间的关系。使用线性回归的一项任务是可以根据过去的房价数据预测房价。
线性回归的成本函数是预测值y(pred)和真实值y(y)之间的均方根误差(RMSE)。

详细信息查看:
- 线性回归[^19]
- 线性回归-细节介绍[^20]
- 机器学习中的线性回归[^21]
逻辑回归
逻辑回归是一种有监督的机器学习算法,用于分类问题。它是一种分类算法,用于将观察值分配给一组离散的类。分类问题的一些例子包括电子邮件是垃圾邮件还是非垃圾邮件,在线交易欺诈或非欺诈。
Logistic回归使使用Sigmoid函数转换其输出以返回概率值。
逻辑回归有两种类型:
- 二分类
- 多分类

详细信息查看:
- 逻辑回归-细节介绍[^22]
- 逻辑回归[^23]
- 什么是逻辑回归?[^24]
K近邻(K-NN)
k近邻(KNN)算法是一种简单,易于实现的有监督的机器学习算法,可用于解决分类和回归问题。
KNN算法假定相似的事物的存在非常接近。换句话说,相似的事物彼此接近。
k近邻可以在推荐系统上使用。
KNN的工作方式是查找目标样本与数据中所有样本之间的距离,选择最接近目标样本的K个样本,然后投票给出现次数最多的标签(在分类的情况下)或平均标签(在回归的情况)。

详细信息查看:
- 机器学习的K近邻算法[^25]
- K近邻算法快速入门[^26]
- KNN分类?[^27]
随机森林
随机森林就像是一种通用的机器学习技术,可用于回归和分类目的。它由大量作为整体运作的独立决策树组成。随机森林中的每个决策树都会做出类别预测,而获得最多投票的类别将成为我们模型的预测类别。
通常,随机森林模型不会过度拟合,即使确实存在,也很容易阻止其过度拟合。
对于随机森林模型,不需要单独的验证集。
它仅作一些统计假设。不假定你的数据是正态分布的,也不假定是线性关系。
它只需要很少的特征工程。

详细信息查看:
- 我从随机森林机器学习算法中学到的东西[^28]
- 了解随机森林[^29]
集成学习
集成学习通过组合多个模型来帮助改善机器学习结果。与单个模型相比,这种方法可以产生更好的性能。
集成方法是将几种机器学习技术组合到一个预测模型中的元算法,目的是减少方差(bagging),偏差(boosting)或改善预测(stacking)。例如随机森林,梯度提升决策树,Adaboost。

详细信息查看:
- 集成学习方法的简单指南[^30]
- 集成方法:Ensemble methods: bagging, boosting and stacking[^31]
梯度提升决策树(GBDT)
Boosting是一种集成技术,其中的预测变量不是独立生成的,而是串行生成的。
这是一种将弱学习器转变为强学习器的方法。梯度增强是Boosting的一个示例,这是一种用于回归和分类问题的机器学习技术,可产生集成或弱预测模型形式的预测模型,像决策树。
详细信息查看:
- 梯度提升[^32]
- Kaggle Master解释了梯度提升[^33]
过拟合
当模型对训练数据的建模太好时,就会发生过度拟合。
当模型学习训练数据中的细节和噪声时,就会过度拟合,从而对模型在新数据上的性能产生负面影响。它对模型的泛化能力产生负面影响。
可以通过以下方式防止它:
- 交叉验证
- 正则化

详细信息查看:
- 机器学习中过拟合:什么是机过拟合以及如何预防[^34]
- 机器学习算法的过拟合和欠拟合[^35]
欠拟合
欠拟合是指既不能对训练数据建模也不能推广到新数据的模型,在训练数据上的表现会很差。

详细信息查看:
- 每日机器学习-过拟合和欠拟合[^36]
- 什么是机器学习中的过拟合和欠拟合以及如何应对[^37]
- 什么是欠拟合[^38]
正则化
正则化是一种修改机器学习模型以避免过度拟合问题的技术。你可以将正则化应用于任何机器学习模型。正则化简化了过于复杂的模型,通过向目标函数添加惩罚项,这些模型很容易过度拟合。如果模型过度拟合,将存在泛化问题,因此在将模型暴露给新数据集时将给出不准确的预测。
详细信息查看:
- 机器学习中的正则化[^39]
- 你需要了解的所有有关正则化的信息[^40]
L1和L2正则化
使用L1正则化技术的回归模型称为套索回归。使用L2正则化技术的模型称为岭回归。
两者之间的关键区别是添加到损失函数中的惩罚项。岭回归将系数的“平方大小”添加为损失函数的惩罚项。套索回归(最小绝对值收敛和选择算子)将系数的“大小绝对值”作为损失项的惩罚项。
详细信息查看:
- L1 L2正则化[^41]
- 简单化的正则化:L2正则化[^42]
- L1和L2之间的差异[^43]
交叉验证
交叉验证是一种通过在可用输入数据的子集上训练几个ML模型并在数据的另外子集上对其进行评估来评估机器学习模型的技术。它用于防止模型过度拟合。
不同类型的交叉验证技术有:
- 留出法
- k折交叉验证(最为流行)
- Leave-P-out
详细信息查看:
- 交叉验证[^44]
- 为什么以及如何交叉验证模型?[^45]
回归问题的性能评估
平均绝对误差(MAE): 测量实际值和预测值之间的差的绝对值的平均值。
均方根误差(RMSE): 测量实际值和预测值之间的平方差的平均值的平方根。详细信息查看:
- 了解回归评估指标[^46]
- 选择正确的度量标准来评估机器学习模型[^47]
- MAE和RMSE-哪个指标更好?[^48]
分类问题的性能评估
混淆矩阵: 它是用于查找模型的精确率和准确率的最直观,最简单的指标之一。它用于分类问题,其中输出可以是两种或更多种类型的类。

真正例(TP): 数据样本的实际类别为1(真),而预测值也是1(真)的情况。真负例(TN): 数据样本的实际类别为0(假),而预测的也是0(假)的情况。假正例(FP): 数据样本的实际类别为0(假),而预测的是1(真)的情况。假负例(FN): 数据样本的实际类别为1(真),而预测的是0(假)的情况。准确率: 分类问题的准确率是模型在所有预测中得出的正确预测数。

何时使用准确率: 当数据中的目标变量类别接近平衡时,准确率是一个很好的度量。
何时不使用准确性: 当数据中的目标变量类别占一类的多数时,绝对不应将准确率用作度量。
精确率(命中率): 精确率是一种度量,它告诉我们预测值中为正例的实际上真正是正例的比例。

召回率或是敏感度: 召回率是一种衡量方法,它告诉我们真正是正例被模型预测正确的比例。

F1f分数: 精确率和召回率的调和平均。
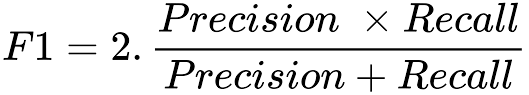
ROC曲线: ROC曲线是显示在所有分类阈值下分类模型的性能的图。
曲线绘制了两个参数:
- 真正率(召回率)
- 假正率(特异性)

ACC: AUC测量整个ROC曲线下方的整个区域面积。
它提供了跨所有可能的分类阈值的性能的总体度量。

详细信息查看:
- 机器学习中分类问题的性能指标[^49]
- 了解混淆矩阵[^50]
上面讨论的主题是机器学习的基础。我们讨论了基本术语,例如AI,机器学习和深度学习,不同类型的机器学习: 有监督和无监督学习,一些机器学习算法,例如线性回归,逻辑回归,k-nn和随机森林以及针对不同的算法性能评估指标。
你认为哪个主题最重要?在下面留下你的想法作为评论。
[^1]: https://en.wikipedia.org/wiki/Artificial_intelligence?source=post_page-----21ad02cc6be5----------------------[^2]: https://searchenterpriseai.techtarget.com/definition/AI-Artificial-Intelligence?source=post_page-----21ad02cc6be5----------------------[^3]: https://en.wikipedia.org/wiki/Machine_learning?source=post_page-----21ad02cc6be5----------------------[^4]: https://www.expertsystem.com/machine-learning-definition/?source=post_page-----21ad02cc6be5----------------------[^5]: https://medium.com/machine-learning-for-humans/why-machine-learning-matters-6164faf1df12?source=post_page-----21ad02cc6be5----------------------[^6]: https://en.wikipedia.org/wiki/Supervised_learning?source=post_page-----21ad02cc6be5----------------------[^7]: https://www.coursera.org/lecture/machine-learning/supervised-learning-1VkCb?source=post_page-----21ad02cc6be5----------------------[^8]: https://en.wikipedia.org/wiki/Unsupervised_learning?source=post_page-----21ad02cc6be5----------------------
[^9]: https://www.datarobot.com/wiki/unsupervised-machine-learning/?source=post_page-----21ad02cc6be5----------------------[^10]: https://dataconomy.com/2015/01/whats-the-difference-between-supervised-and-unsupervised-learning/?source=post_page-----21ad02cc6be5----------------------[^11]: https://towardsdatascience.com/understanding-neural-networks-19020b758230?source=post_page-----21ad02cc6be5----------------------[^12]: http://neuralnetworksanddeeplearning.com/chap1.html?source=post_page-----21ad02cc6be5----------------------[^13]: https://www.techradar.com/au/news/what-is-a-neural-network?source=post_page-----21ad02cc6be5----------------------[^14]: https://en.wikipedia.org/wiki/Backpropagation?source=post_page-----21ad02cc6be5----------------------[^15]: https://towardsdatascience.com/how-does-back-propagation-in-artificial-neural-networks-work-c7cad873ea7?source=post_page-----21ad02cc6be5----------------------[^16]: https://www.techopedia.com/definition/32902/deep-neural-network?source=post_page-----21ad02cc6be5----------------------[^17]: https://towardsdatascience.com/the-basics-of-deep-neural-networks-4dc39bff2c96?source=post_page-----21ad02cc6be5----------------------[^18]: https://en.wikipedia.org/wiki/Linear_regression?source=post_page-----21ad02cc6be5----------------------[^19]: https://towardsdatascience.com/linear-regression-detailed-view-ea73175f6e86?source=post_page-----21ad02cc6be5----------------------[^20]: https://machinelearningmastery.com/linear-regression-for-machine-learning/?source=post_page-----21ad02cc6be5----------------------[^21]: https://towardsdatascience.com/logistic-regression-detailed-overview-46c4da4303bc?source=post_page-----21ad02cc6be5----------------------[^22]: https://en.wikipedia.org/wiki/Logistic_regression?source=post_page-----21ad02cc6be5----------------------[^23]: https://www.statisticssolutions.com/what-is-logistic-regression/?source=post_page-----21ad02cc6be5----------------------[^24]: https://medium.com/capital-one-tech/k-nearest-neighbors-knn-algorithm-for-machine-learning-e883219c8f26?source=post_page-----21ad02cc6be5----------------------[^25]: https://blog.usejournal.com/a-quick-introduction-to-k-nearest-neighbors-algorithm-62214cea29c7?source=post_page-----21ad02cc6be5----------------------[^26]: https://www.saedsayad.com/k_nearest_neighbors.htm?source=post_page-----21ad02cc6be5----------------------[^27]: https://towardsdatascience.com/things-i-learned-about-random-forest-machine-learning-algorithm-40fde28fa89e?source=post_page-----21ad02cc6be5----------------------[^28]: https://towardsdatascience.com/understanding-random-forest-58381e0602d2?source=post_page-----21ad02cc6be5----------------------[^29]: https://towardsdatascience.com/simple-guide-for-ensemble-learning-methods-d87cc68705a2?source=post_page-----21ad02cc6be5----------------------[^30]: https://towardsdatascience.com/ensemble-methods-bagging-boosting-and-stacking-c9214a10a205?source=post_page-----21ad02cc6be5----------------------[^31]: https://medium.com/mlreview/gradient-boosting-from-scratch-1e317ae4587d?source=post_page-----21ad02cc6be5----------------------[^32]: http://blog.kaggle.com/2017/01/23/a-kaggle-master-explains-gradient-boosting/?source=post_page-----21ad02cc6be5----------------------[^33]: https://elitedatascience.com/overfitting-in-machine-learning?source=post_page-----21ad02cc6be5----------------------[^34]: https://elitedatascience.com/overfitting-in-machine-learning?source=post_page-----21ad02cc6be5----------------------[^35]: https://machinelearningmastery.com/overfitting-and-underfitting-with-machine-learning-algorithms/?source=post_page-----21ad02cc6be5----------------------[^36]: https://chemicalstatistician.wordpress.com/2014/03/19/machine-learning-lesson-of-the-day-overfitting-and-underfitting/?source=post_page-----21ad02cc6be5----------------------[^37]: https://medium.com/greyatom/what-is-underfitting-and-overfitting-in-machine-learning-and-how-to-deal-with-it-6803a989c76?source=post_page-----21ad02cc6be5----------------------[^38]: https://www.datarobot.com/wiki/underfitting/?source=post_page-----21ad02cc6be5----------------------[^39]: https://towardsdatascience.com/regularization-in-machine-learning-76441ddcf99a?source=post_page-----21ad02cc6be5----------------------[^40]: https://towardsdatascience.com/all-you-need-to-know-about-regularization-b04fc4300369?source=post_page-----21ad02cc6be5----------------------[^41]: https://medium.com/datadriveninvestor/l1-l2-regularization-7f1b4fe948f2?source=post_page-----21ad02cc6be5----------------------[^42]: https://developers.google.com/machine-learning/crash-course/regularization-for-simplicity/l2-regularization?source=post_page-----21ad02cc6be5----------------------[^43]: http://www.chioka.in/differences-between-l1-and-l2-as-loss-function-and-regularization/?source=post_page-----21ad02cc6be5----------------------[^44]: https://towardsdatascience.com/cross-validation-70289113a072?source=post_page-----21ad02cc6be5----------------------[^45]: https://towardsdatascience.com/why-and-how-to-cross-validate-a-model-d6424b45261f?source=post_page-----21ad02cc6be5----------------------[^46]: https://becominghuman.ai/understand-regression-performance-metrics-bdb0e7fcc1b3?source=post_page-----21ad02cc6be5----------------------[^47]: https://medium.com/usf-msds/choosing-the-right-metric-for-machine-learning-models-part-1-a99d7d7414e4?source=post_page-----21ad02cc6be5----------------------[^48]: https://medium.com/human-in-a-machine-world/mae-and-rmse-which-metric-is-better-e60ac3bde13d?source=post_page-----21ad02cc6be5----------------------[^49]: https://medium.com/thalus-ai/performance-metrics-for-classification-problems-in-machine-learning-part-i-b085d432082b?source=post_page-----21ad02cc6be5----------------------[^50]: https://towardsdatascience.com/understanding-confusion-matrix-a9ad42dcfd62?source=post_page-----21ad02cc6be5----------------------
欢迎关注磐创博客资源汇总站:http://docs.panchuang.net/
欢迎关注PyTorch官方中文教程站:http://pytorch.panchuang.net/