概述
- 迁移学习可以改变你建立机器学习和深度学习模型的方式
- 了解如何使用PyTorch进行迁移学习,以及如何将其与使用预训练的模型联系起来
- 我们将使用真实世界的数据集,并比较使用卷积神经网络(CNNs)构建的模型和使用迁移学习构建的模型的性能
介绍
我去年在一个计算机视觉项目中工作,我们必须建立一个健壮的人脸检测模型。
考虑到我们拥有的数据集的大小,从头构建一个模型是一个挑战。从头构建将是一个耗时又消耗计算资源的方案。由于时间紧迫,我们必须尽快找出解决办法。

这就是迁移学习拯救我们的时候。这是一个非常有用的工具,可以放在你的数据科学家库中,特别是当你使用有限的时间和计算能力时。
因此,在本文中,我们将学习有关迁移学习的所有内容,以及如何在使用Python的实际项目中利用它。我们还将讨论预训练模型在这个领域的作用,以及它们将如何改变构建机器学习pipeline(管道)的方式。
本文是面向初学者的PyTorch系列文章的一部分。我坚信PyTorch是目前最好的深度学习框架之一,在不久的将来会越来越强大。这是一个很好的时间来学习它是如何工作的,并参与其中。
目录
- 迁移学习概论
- 什么是预训练模型?如何选择正确的预训练模型?
- 案例研究:紧急与非紧急车辆分类
- 使用卷积神经网络(CNNs)解决挑战
- 使用PyTorch的迁移学习解决挑战
- CNN的性能比较和迁移学习
迁移学习概论
让我用一个例子来说明迁移学习的概念。想象一下,你想从一个你完全陌生的领域学习一个主题。
你会采取什么不同的方法来理解这个主题?你可能会:
- 网上搜寻资源
- 阅读文章和博客
- 参考书籍
- 寻找视频教程,等等
所有这些都会帮助你熟悉这个主题。在这种情况下,你是唯一一个付出所有时间来熟悉主题的人。
但还有另一种方法,它可能在短时间内产生更好的结果。
你可以咨询对你想要学习的主题具有能力的领域/主题专家。这个人会把他/她的知识传授给你。从而加快你的学习过程。

第一种方法,即你独自投入所有的努力,是从头开始学习的一个例子。第二种方法被称为迁移学习。知识转移发生在一个领域的专家到一个面对新领域的新手。
是的,迁移学习背后的思想就是这么简单!
神经网络和卷积神经网络就是从零开始学习的例子。这两个网络都从给定的一组图像中提取特征(对于与图像相关的任务),然后根据这些提取的特征将图像分类到各自的类中。
这就是迁移学习和预训练的模型非常有用的地方。让我们在下一节中了解一下后一个概念。
什么是预训练模型?如何选择正确的预训练模型?
在你将要从事的任何深度学习项目中,预训练的模型都是非常有用的。并非所有人都拥有顶级科技巨头的无限计算能力,相反我们需要使用我们本地有限的机器,所以预训练模型是一个强大的工具。
正如你可能已经猜到的,预训练模型是由特定人员或团队为解决特定问题而设计和训练的模型。
回想一下,我们在训练神经网络和CNNs等模型时学习了权重和偏置。当这些权重和偏置与图像像素相乘时,有助于生成特征。
预训练的模型通过将它们的权重和偏置传递给一个新模型来共享它们的学习。因此,当我们进行迁移学习时,我们首先选择恰当的预训练模型,然后将其已学习的权值和偏置传递给新模型。
有n种预训练过的模型。我们需要决定哪种模式最适合我们的问题。现在,让我们考虑一下我们有三个预训练好的网络——BERT、ULMFiT和VGG16。

我们的任务是对图像进行分类(正如我们在本系列的前几篇文章中所做的那样)。那么,你会选择哪些预训练好的模型呢?让我先给你一个快速的概述这些预训练的网络,这将帮助我们决定正确的预训练的模型。
语言建模使用BERT和ULMFiT,图像分类任务使用VGG16。如果你看一下手头的问题,这是一个图像分类问题。所以我们选择VGG16是理所当然的。
现在,VGG16可以有不同的重量,即VGG16训练在ImageNet或VGG16训练在MNIST:
ImageNet与MNIST
现在,为我们的问题确定正确的预训练模型,我们应该研究这些ImageNet和MNIST数据集。ImageNet数据集由1000个类和总共120万张图像组成。这些数据中的一些类别是动物、汽车、商店、狗、食物、仪器等:

另一方面,MNIST是训练手写数字的。它包括10类从0到9:

我们将在一个项目中工作,我们需要将图像分为紧急和非紧急车辆(我们将在下一节详细讨论)。这个数据集包括车辆的图像,因此在ImageNet数据集上训练的VGG16模型将更有用,因为它有车辆的图像。
简而言之,这就是我们应该如何根据我们的问题来决定正确的预训练模型。
案例研究:紧急与非紧急车辆分类
我们将进行一个新的目标!这里,我们的目标是将车辆分为紧急和非紧急。
现在让我们开始理解这个问题并可视化一些示例。你可以通过这个链接下载图片:https://drive.google.com/file/d/1EbVifjP0FQkyB1axb7KQ26yPtWmneApJ/view
首先,导入所需的库:
接下来,我们将读取包含图像名称和相应标签的.csv文件:
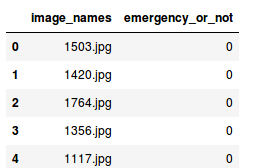
csv文件有两列:
- image_names:它表示数据集中所有图像的名称
- emergency_or_no:它指定特定的图像属于紧急类还是非紧急类。0表示图像是非紧急车辆,1表示紧急车辆
接下来,我们将加载所有的图像,并将它们存储为数组格式:

加载这些图像大约需要12秒。在我们的数据集中有1646张图像,由于VGG16需要所有这种特殊形状的图像,所以我们将它们的形状全部重设为(224,224,3)。现在让我们从数据集中可视化一些图像:

这是一辆警车,因此有紧急车辆的标签。现在我们将目标存储在一个单独的变量:
让我们创建一个验证集来评估我们的模型:
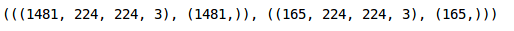
我们在训练集中有1,481张图像,在验证集中有165张图像。现在我们必须将数据集转换为torch格式:
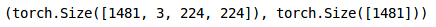
类似地,我们将转换验证集:
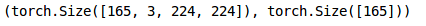
我们的数据准备好了!在下一节中,我们将构建一个卷积神经网络(CNN),然后使用预训练模型来解决这个问题。
使用卷积神经网络(CNNs)解决挑战
我们终于到了模型制作部分!在使用迁移学习来解决这个问题之前,我们先用一个CNN模型为自己设定一个benchmark。
我们将构建一个非常简单的CNN架构,它有两个卷积层来提取图像的特征,最后是一个全连接层来对这些特征进行分类:
现在让我们定义优化器,学习率和损失函数为我们的模型,并使用GPU训练模型:

这就是模型架构的样子。最后,我们将对模型进行15个epoch的训练。我将模型的batch_size设置为128(你可以尝试一下):

这也会打印一份训练总结。训练损失在每个时期之后都在减少,这是一个好迹象。我们来检查一下训练和验证的准确性:

我们的训练正确率在82%左右,这是一个不错的分数。下面检查验证的准确性:
# 验证集预测
prediction_val = []
target_val = []
permutation = torch.randperm(val_x.size()[0])
for i in tqdm(range(0,val_x.size()[0], batch_size)):
indices = permutation[i:i batch_size]
batch_x, batch_y = val_x[indices], val_y[indices]
if torch.cuda.is_available():
batch_x, batch_y = batch_x.cuda(), batch_y.cuda()
with torch.no_grad():
output = model(batch_x.cuda())
softmax = torch.exp(output).cpu()
prob = list(softmax.numpy())
predictions = np.argmax(prob, axis=1)
prediction_val.append(predictions)
target_val.append(batch_y)
# 验证集精确度
accuracy_val = []
for i in range(len(prediction_val)):
accuracy_val.append(accuracy_score(target_val[i],prediction_val[i]))
print('validation accuracy: ', np.average(accuracy_val))

验证的准确性为76%。现在我们已经有了一个基准,是时候使用迁移学习来解决紧急和非紧急车辆分类问题了!
使用PyTorch的迁移学习解决挑战
我在上面已经提到了这一点,我在这里重申一下——我们将使用在ImageNet数据集上训练的VGG16预训练模型。让我们看看我们将遵循的步骤,以训练模型使用迁移学习:
- 首先,我们将加载预训练模型的权重——在我们的例子中是VGG16
- 然后我们将根据手头的问题对模型进行微调
- 接下来,我们将使用这些预训练的权重并提取图像的特征
- 最后,我们将使用提取的特征训练精细调整的模型
那么,让我们从加载模型的权重开始:
# 加载预训练模型
model = models.vgg16_bn(pretrained=True)
现在我们将对模型进行微调。我们不训练VGG16模型的层,因此让我们固定这些层的权重:
# 固定模型权重
for param in model.parameters():
param.requires_grad = False
由于我们只需要预测2个类,而VGG16是在ImageNet上训练的,ImageNet有1000个类,我们需要根据我们的问题更新最后一层:
# 最后加一个分类器
model.classifier[6] = Sequential(
Linear(4096, 2))
for param in model.classifier[6].parameters():
param.requires_grad = True
因为我们只训练最后一层,所以我将最后一层的requires_grad设置为True。我们将训练设置为GPU:
# 检查GPU是否可用
if torch.cuda.is_available():
model = model.cuda()
现在,我们将使用该模型并为训练和验证图像提取特性。我将batch_size设置为128(同样,你可以根据需要增加或减少batch_size):
# batch大小
batch_size = 128
# 从训练集提取特征
data_x = []
label_x = []
inputs,labels = train_x, train_y
for i in tqdm(range(int(train_x.shape[0]/batch_size) 1)):
input_data = inputs[i*batch_size:(i 1)*batch_size]
label_data = labels[i*batch_size:(i 1)*batch_size]
input_data , label_data = Variable(input_data.cuda()),Variable(label_data.cuda())
x = model.features(input_data)
data_x.extend(x.data.cpu().numpy())
label_x.extend(label_data.data.cpu().numpy())
类似地,让我们提取验证图像的特征:
# 从验证集提取特征
data_y = []
label_y = []
inputs,labels = val_x, val_y
for i in tqdm(range(int(val_x.shape[0]/batch_size) 1)):
input_data = inputs[i*batch_size:(i 1)*batch_size]
label_data = labels[i*batch_size:(i 1)*batch_size]
input_data , label_data = Variable(input_data.cuda()),Variable(label_data.cuda())
x = model.features(input_data)
data_y.extend(x.data.cpu().numpy())
label_y.extend(label_data.data.cpu().numpy())
接下来,我们将这些数据转换成torch格式:
# 转换这些数据到torch格式
x_train = torch.from_numpy(np.array(data_x))
x_train = x_train.view(x_train.size(0), -1)
y_train = torch.from_numpy(np.array(label_x))
x_val = torch.from_numpy(np.array(data_y))
x_val = x_val.view(x_val.size(0), -1)
y_val = torch.from_numpy(np.array(label_y))
我们还必须为我们的模型定义优化器和损失函数:
# batch大小
batch_size = 128
# 30个epochs
n_epochs = 30
for epoch in tqdm(range(1, n_epochs 1)):
# 跟踪训练与验证集损失
train_loss = 0.0
permutation = torch.randperm(x_train.size()[0])
training_loss = []
for i in range(0,x_train.size()[0], batch_size):
indices = permutation[i:i batch_size]
batch_x, batch_y = x_train[indices], y_train[indices]
if torch.cuda.is_available():
batch_x, batch_y = batch_x.cuda(), batch_y.cuda()
optimizer.zero_grad()
outputs = model.classifier(batch_x)
loss = criterion(outputs,batch_y)
training_loss.append(loss.item())
loss.backward()
optimizer.step()
training_loss = np.average(training_loss)
print('epoch: ', epoch, ' training loss: ', training_loss)

以下是该模型的摘要。你可以看到损失减少了,因此我们可以说模型在改进。让我们通过观察训练和验证的准确性来验证这一点:
# 预测训练集
prediction = []
target = []
permutation = torch.randperm(x_train.size()[0])
for i in tqdm(range(0,x_train.size()[0], batch_size)):
indices = permutation[i:i batch_size]
batch_x, batch_y = x_train[indices], y_train[indices]
if torch.cuda.is_available():
batch_x, batch_y = batch_x.cuda(), batch_y.cuda()
with torch.no_grad():
output = model.classifier(batch_x.cuda())
softmax = torch.exp(output).cpu()
prob = list(softmax.numpy())
predictions = np.argmax(prob, axis=1)
prediction.append(predictions)
target.append(batch_y)
# 训练精度
accuracy = []
for i in range(len(prediction)):
accuracy.append(accuracy_score(target[i],prediction[i]))
print('training accuracy: ', np.average(accuracy))

我们在训练集上获得了大约84%的准确性。现在让我们检查验证的准确性:
# 预测验证集
prediction = []
target = []
permutation = torch.randperm(x_train.size()[0])
for i in tqdm(range(0,x_train.size()[0], batch_size)):
indices = permutation[i:i batch_size]
batch_x, batch_y = x_train[indices], y_train[indices]
if torch.cuda.is_available():
batch_x, batch_y = batch_x.cuda(), batch_y.cuda()
with torch.no_grad():
output = model.classifier(batch_x.cuda())
softmax = torch.exp(output).cpu()
prob = list(softmax.numpy())
predictions = np.argmax(prob, axis=1)
prediction.append(predictions)
target.append(batch_y)
# 验证精度
accuracy = []
for i in range(len(prediction)):
accuracy.append(accuracy_score(target[i],prediction[i]))
print('training accuracy: ', np.average(accuracy))

模型的验证精度也相似, 83%。训练和验证的准确性几乎是同步的,因此我们可以说这个模型是广义的。以下是我们的研究结果摘要:
| Model | Training Accuracy | Validation Accuracy |
|---|---|---|
| CNN | 81.57% | 76.26% |
| VGG16 | 83.70% | 83.47% |
我们可以推断,与CNN模型相比,VGG16预训练模型的准确率有所提高!
结尾
在这篇文章中,我们学习了如何使用预训练的模型和迁移学习来解决一个图像分类问题。我们首先了解什么是预训练模型,以及如何根据手头的问题选择正确的预训练模型。然后,我们以汽车图像为例进行了紧急和非紧急图像的分类研究。我们首先使用CNN模型解决了这个案例研究,然后使用VGG16预训练模型解决了同样的问题。
我们发现使用VGG16预训练模型显著提高了模型性能,并且与CNN模型相比,我们得到了更好的结果。我希望你现在已经清楚地了解了如何在使用PyTorch使用迁移学习和正确的预训练模型来解决问题。
我鼓励你试着用迁移学习来解决其他的图像分类问题。这将帮助你更清楚地理解这个概念。
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/
欢迎关注PyTorch官方中文教程站:
http://pytorch.panchuang.net/