(一)集合框架:
Java语言的设计者对常用的数据结构和算法做了一些规范(接口)和实现(实现接口的类)。所有抽象出来的数据结构和操作(算法)统称为集合框架。
程序员在具体应用的时候,不必考虑数据结构和算法实现细节,只需要用这些类创建一些对象,然后直接应用就可以了,这样就大大提高了编程效率。
(二)集合框架包含的内容: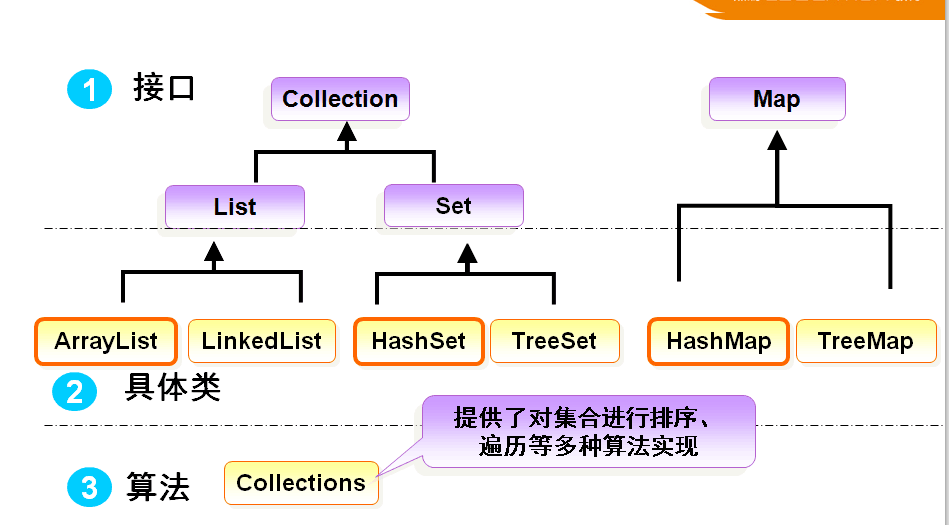
(三)集合框架的接口(规范)
Collection接口:存储一组不唯一,无序的对象
List接口:存储一组不唯一,有序的对象
Set接口:存储一组唯一,无序的对象
Map接口:存储一组键值对象,提高键(key)到值(value)的映射
(四)各种接口的实现类:
List接口的2个常用实现类:ArrayList和LinkedList
ArrayList类:在它的底层代码中,实际是有一个Object型数组,通过一些方法实现数组的扩容,数组本身长度是在定义的时候就不能改变,JDK的源码底层就是通过新创建一个数组,长度比原来的长,把之前原数组的每个元素复制过来,然后把新数组的首地址赋值给了原数组的引用,就这样实现了可变长度数组;所以ArrayList的特点就是:遍历和随机访问的速度快,插入对象和删除对象的效率就低,因为底层的实现是通过数组来实现
LinkedList类:底层通过结点来实现的,它有2个Node结点属性,一个根结点first,一个尾结点last。添加的元素是保存在Node结点属性中item,看下面JDK源码,然后通过Node还有2个属性next和prev分别指向后一个保存元素的结点和指向前一个保存元素的结点;就这样形成一条逻辑上的一条链,它们在堆内存中内存是不连续的;所以LinkedList类的特点:访问元素的效率不高,但是插入和删除元素的效率高,因为通过结点改变指向就可以实现了。
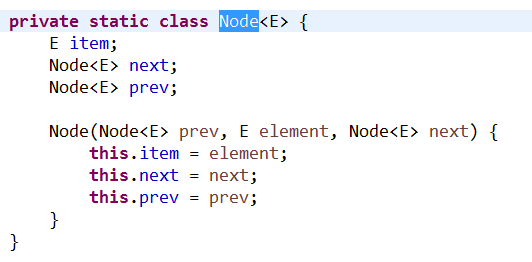
Map的实现类我就只讲一个HashMap,TreeMap就不讲了,就是添加进去的时候,有一定的顺序,不过根本不重要,可以借助工具类Collections类方法来实现对集合元素的排序。
HashMap底层就是通过结点数组(数组+结点)来实现的,为什么put()方法存key和value的时候,key不能重复,重复的话value会覆盖原先的value,key值在底层是通过它的hashCode来保证唯一性
同样的来讲解一下HashSet,给大家看看一个它的JDK源码,map是HashMap类型,把数据存储到map的key中,所以说HashSet存储的元素是不能重复的

 PRESENT是个常量
PRESENT是个常量