深度学习与爬虫实例教学
声明:该教程不会直接贴代码,以免凌乱,你需要先下载项目代码(第一章)并结合来看,教程中会告诉你具体代码放在什么位置,以及作用,用法
深度学习实现验证码自动识别,爬虫自动认证防ban
我们将学习如何构建一个用于验证码识别的深度学习模型和结合爬虫进行构建一个项目
教学大纲
项目基本介绍和体验
深度学习模型构建和训练
自动识别知乎认证码并实现抓取
扩展之结合scrapy,Django构建完整项目
构建网络
网络模型如下图
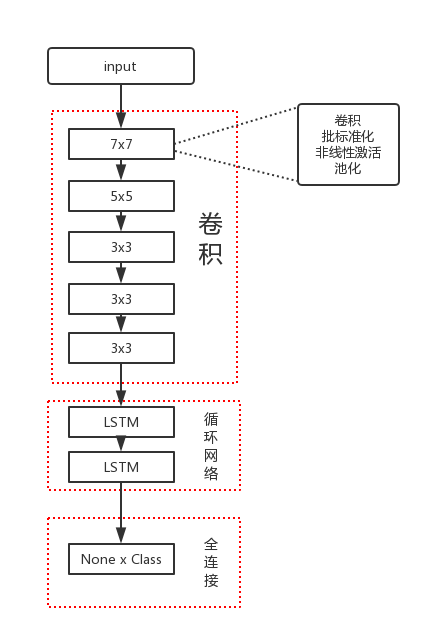
具体代码请见项目目录Unofficial-Zhihu-API/ufzh下的orcmodel.py模块,该模块只有一个类LSTMOCR,该类维护了整个网络的模型构建、可视化tensorboard的记录、loss、优化器等等。
模仿验证码数据
为什么要模仿验证码数据呢,我们回想一下上一章节说到的我们准备用迁移学习方案来实现知乎验证码的识别,而迁移学习的前提是我们有一个别的类似的场景的模型,我们现在就是要模仿验证码数据,并拿这些数据训练得到的模型就是我们所说的“别的类似的场景训练好的模型”,得到这个模型我们才可以进行迁移学习。
我们可以看出知乎验证码(忽略倾斜等效果,因为我们也可以做倾斜等处理)的字体跟euphemia.ttf字体很类似,注意了是类似,你也可以觉得它跟其他字体类似并拿那个字体为模版,随意点即可,

敲黑板,敲黑板,知乎验证码除了上面的实体,还有艺术字体的空心字体 ,空心字体要不要也模仿呢,不用,为啥啊,因为我们只是需要一个“别的类似的场景训练好的模型”,不需要包括那么全,只需要在迁移学习的时候少量包含空心字体的训练样本进行迁移学习就可以了,这也是迁移学习的强大体现
,空心字体要不要也模仿呢,不用,为啥啊,因为我们只是需要一个“别的类似的场景训练好的模型”,不需要包括那么全,只需要在迁移学习的时候少量包含空心字体的训练样本进行迁移学习就可以了,这也是迁移学习的强大体现
具体代码请见项目目录Unofficial-Zhihu-API/train_workspace下的pai_image.py模块,该模块包含ImageCaptcha类,该类create_captcha_image方法就是模仿了知乎验证码的生成,注意,只是模仿,相似度还是有差距的,人眼看起来可能没那么大差别,但是对于像素上的差别,毛刺,平滑等等,实际上算是差别很大的
训练入口
具体代码请见项目目录Unofficial-Zhihu-API/train_workspace下的main.py模块,该模块包含一个方法train,train方法会负责加载模型,加载图数据以及label(由名称分离出来)到内存中,然后进行训练
用到的命令行参数包含在utils.py模块中,主要的参数有:
restore 是否加载之前训练过的参数,可以实现断点续接,随时随地断了再继续训练
initial_learning_rate 初始化学习率
train_dir 训练图片的目录
val_dir 验证图片的目录
代码用法
本章节介绍了orcmodel.py模块,该模块包含了网络模型,pai_image.py模块,该模块包含了模仿验证码的生成代码,代码用法如目录Unofficial-Zhihu-API/train_workspace下的helper.py模块
打开终端,cd到目录Unofficial-Zhihu-API/train_workspace,打开ipython,并输入下列代码
# 删除./data/train目录
# 准备一下200000张图片,你可以调整,如果你内存很大
# 你可以生成40万,内存不大可以生成5万
# 以免图数据太多,内存不够导致运行训练的时候会报错
import helper
# 生成训练数据
helper.gen_simulated_img('./data/train', 200000) # 地二个参数是生成200000张
# 生成验证数据
helper.gen_simulated_img('./data/val', 2000)
生成过程中就可以在根目录的data/train目录下看到如下图,每张图的名称格式为: id_正确验证码.png
数据生成完毕之后,打开终端,cd到根目录Unofficial-Zhihu-API/train_workspace
运行一下命令
python main.py --restore False --initial_learning_rate 1e-5 --train_dir data/train --val_dir data/val
训练会产生summary日志,可以用tensorboard可视化查看训练过程中cost的变化,打开终端,cd到目录Unofficial-Zhihu-API/train_workspace,输入下列命令,然后打开http://localhost:6006/#scalars查看cost变化,打开http://pai-pc:6006/#graphs查看图模型
tensorboard --logdir ./log
如果你电脑的GPU不错,你就用tensorflow-gpu版本训练,我是用的GTX1060 6
G的GPU训练的,如果你没有GPU或者GPU很烂,你可以去用百度GPU训练,我曾经用过,2块多一个小时吧,还可以接受
训练到正确率有90%以上之后就可以停止了,这个时候我们就得到一个“别的类似的场景训练好的模型”,然后可以进入迁移学习部分了
进行迁移学习
上面已经获得一个“别的类似的场景训练好的模型”,但是对于真实的知乎验证码,识别率低到你怀疑人生,所以,咱们开始进行迁移学习知乎真实验证码吧
在项目根目录的data目录下,有一份打包文件迁移学习样本.zip,这个是我自己抓取下载并自己手工标记的2000张真实的知乎验证码,心累啊,2000张都标记到我手断了,然后解压放在./data/zhihu_train和./data/zhihu_val,因为真实的知乎验证码数据太珍贵了,我们就直接让训练和测试数据都一样了,然后运行下列命令进行迁移学习
python main.py --restore True --initial_learning_rate 1e-5 --train_dir data/zhihu_train --val_dir data/zhihu_val --log_dir zhihu_log
还是一样的用tensorboard实现可视化,不过这回我们生成summary日志的地址变成zhihu_log了
tensorboard --logdir ./zhihu_log
训练到90%以上正确率就可以了
获得自己训练的结果之后找到python的类似site-packages/ufzh-1.0.0-py3.6.egg/ufzh/checkpoint这样的目录,替换里面的checkpoint即可用自己训练的参数进行测试,替换四个文件