——以下内容如有各种问题,烦请指出,谢谢各位^_^——
最基本的Java程序员面试题都有这个题
——http get和post的区别?
不少人大学还没毕业就知道,就算不知道也会去搜,我记得我快毕业那会,简单搜出来,排在前面的大概就这么几个区别:
1、get用于获取数据,post用于提交数据
2、get提交参数追加在url后面,post参数可以通过http body提交
3、get的url会有长度上的限制,则post的数据则可以非常大
4、get提交信息明文显示在url上,不够安全,post提交的信息不会在url上显示
5、get提交可以被浏览器缓存,post不会被浏览器缓存
现在回头总结下,发现自己快毕业哪会自己真是什么都不知道啊,当时网上搜出来的这份东西就是有误的啊,国内也是各种传来传去,错误的到处看得到,都快成标准答案了。今年5月用netty http 些服务端程序时,调接口无意发现了原来get也可以使用http body提交数据,抽空弄了下tomcat,发现也可以啊。今天整理笔记看到了这里,觉得有必要在博客上记录一下,避免后来人继续犯错。
一点一点的说 第1点:rfc2616说get方法用于获取指定uri所代表的资源,应该设计成幂等的(其他情况不变时,多次请求返回同样的结果,差不多算是只读),不过在很长一段时间内,get方法都有“写”功能,最简单的例子就是/delete?id=1,然后很常见的就是jsonp形式的请求。 post方法该做什么rfc2616说是叫服务器自己决定,现实中用post进行只读操作的很多啊,一些提供http接口的数据库都有post json进行只读查询的功能,post提交表单数据进行写操作到处都是。 所以第一点这个,不怎么好评价,现在的多数用途下第一点就是废话,什么意思都没表达。不过现在RESTful炒得火热,在RESTful的理念下,第一点差不多算是对的,不过RESTful任重道远啊,比起现在只用get/post的http,毕竟实质性的功能没有多大变化。 应该是今后很长一段时间内,get和post在第一点上基本没区别,能用post实现的操作,基本上也能用get实现。
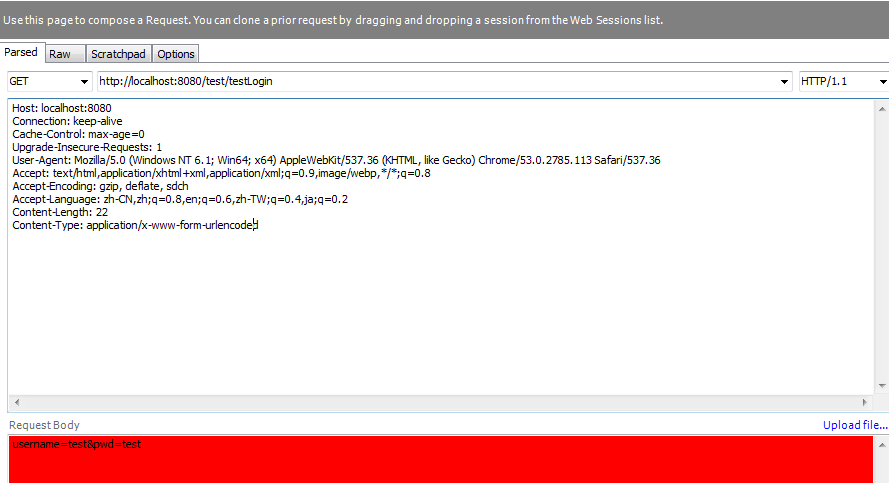
第2点:这一点是最坑的。 http没明确规定什么get/post方法要用什么样的方式传输数据,之所以出现第2点所说的情况,原因主要有两点:浏览器设计、服务器设计,浏览器不支持get+httpbody是比较常见的,fiddler模拟请求时,如果是get,你填下面的body部分会红色显示,告诉你这样不好,仅仅是不好,因为fiddler并没有禁止get+body这种请求,但看得出它不建议你用这种方式的请求。
常见的servlet服务器,比如tomcat,默认不解析get的body部分,造成了get不能用body传递参数的现象。我写了个简单的例子,对比看下就知道是tomcat没解析get的body,不是get本身不能使用body传参。
1 import java.io.IOException; 2 3 import javax.servlet.http.HttpServletRequest; 4 5 import org.apache.commons.lang3.StringUtils; 6 import org.springframework.stereotype.Controller; 7 import org.springframework.web.bind.annotation.RequestMapping; 8 import org.springframework.web.bind.annotation.ResponseBody; 9 10 @Controller 11 public class TestController { 12 private static final String NEW_LINE = StringUtils.CR + StringUtils.LF; 13 14 @ResponseBody 15 @RequestMapping("/testLogin") 16 public String testLogin(HttpServletRequest req, String username, String pwd) throws IOException { 17 StringBuilder builder = new StringBuilder(); 18 builder.append("req.method: ").append(req.getMethod()).append(NEW_LINE); 19 builder.append("req.queryString: ").append(req.getQueryString()).append(NEW_LINE); 20 int contentLength = req.getContentLength(); 21 String body = null; 22 if (contentLength > 0) { 23 byte[] bytes = new byte[contentLength]; 24 req.getInputStream().read(bytes); 25 body = new String(bytes, "UTF-8"); 26 } 27 builder.append("req.body: ").append(body).append(NEW_LINE); 28 builder.append("req.params.username: ").append(req.getParameter("username")).append(NEW_LINE); 29 builder.append("req.params.pwd: ").append(req.getParameter("pwd")).append(NEW_LINE); 30 builder.append("username: ").append(username).append(NEW_LINE); 31 builder.append("pwd: ").append(pwd); 32 System.err.println(builder); 33 return builder.toString(); 34 } 35 }
上面这个controller功能很简单,就是打印请求参数,并且原样返回,结果如下
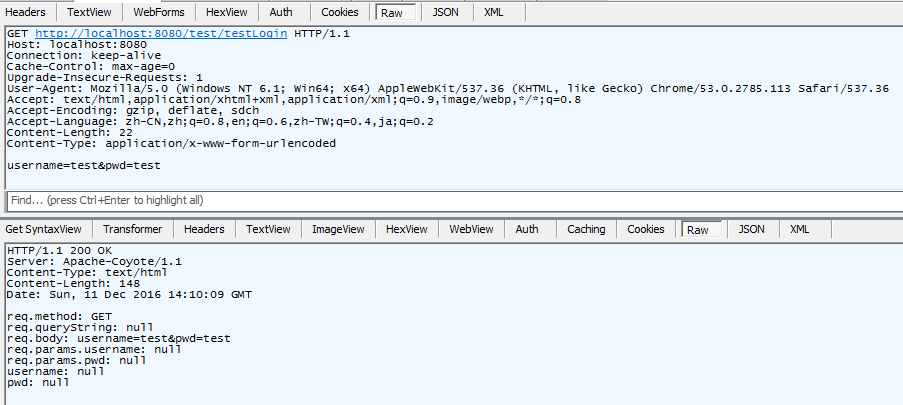
上面张图看出来,body部分可以获取得到,但是tomcat没有读取了ServletInputStream中的body并解析body,造成req.getParam获取不到对应的参数。
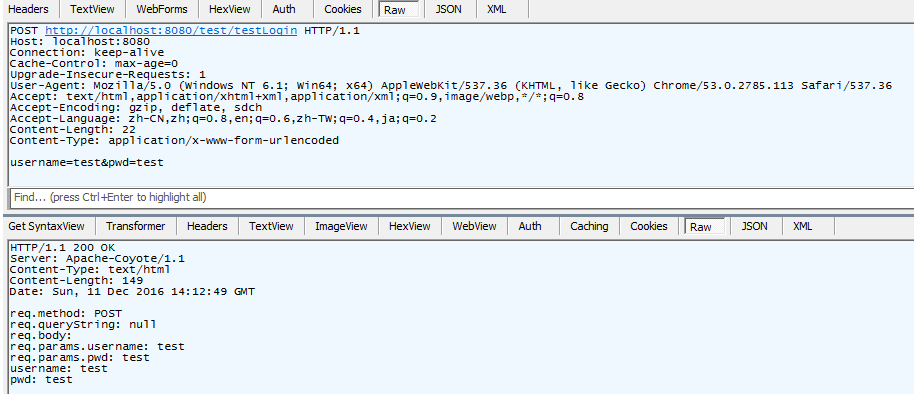
这张图就是把方法换成POST,Request的其余一个字符都没有变,可以看到tomcat读取了ServletInputStream中的body,并进行解析,造成了手动读取ServletInputStream时流中没有内容了,打印出来的req.body显示无内容,req.getParam能够获取到解析完成后对应的参数。
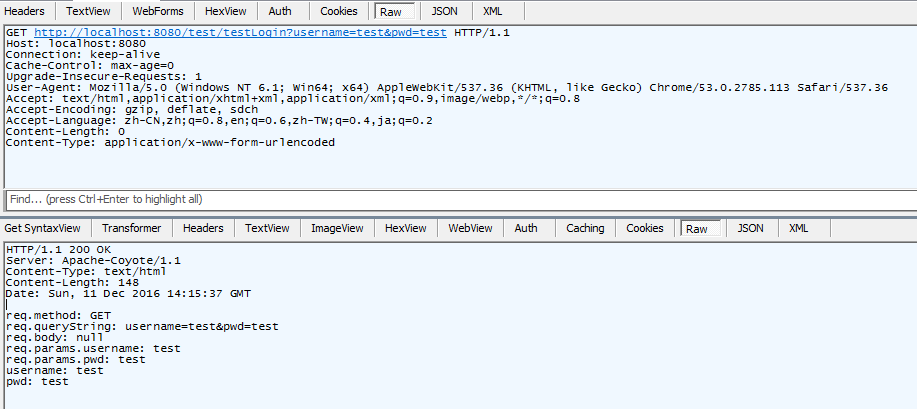
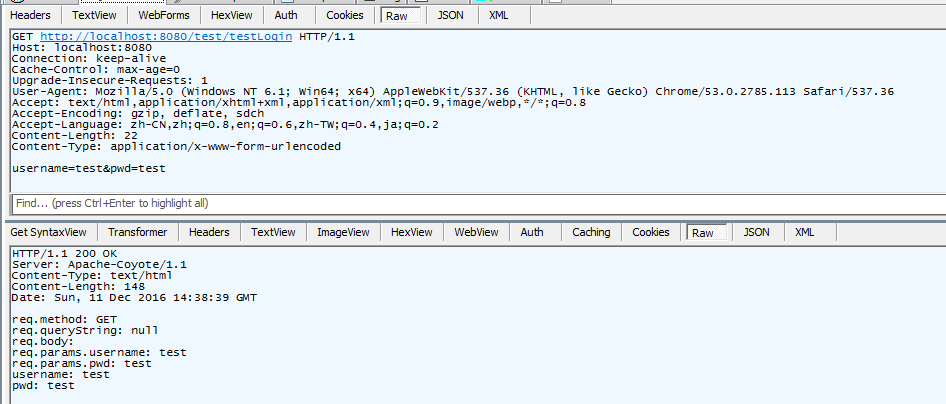
这张图是普通的get+queryString,效果和post+body一样。
对比上面三个结果就知道,get不是不能使用body传参,只是浏览器和服务器进行了限制。浏览器的限制我不知道,这个研究得不多,tomcat的限制倒是可以根据配置解除。
官方配置:http://tomcat.apache.org/tomcat-8.0-doc/config/http.html
具体就是这一项

默认是POST,也就是当Content-Type=application/x-www-form-urlencoded(提交Web表单时的标准数据传输格式,跟url传参格式一样,使用键值对,用&区分)时,只对post方法的body部分进行解析。把tomcat的server.xml中Http1.1的Connector配置上这项,就能够让tomcat能够解析get的body部分,也就能够在tomcat上使用get+body的方式了。

上面这图是修改配置后的结果,改完配置后get+body跟post+body功能一样了。
第3点:这个跟第2点一样,rfc2616中说了不对uri长度做限制,要求http能够实现无限长度的uri,无限长度的body。
原话是下面这个:
The HTTP protocol does not place any a priori limit on the length of a URI. Servers MUST be able to handle the URI of any resource they serve, and SHOULD be able to handle URIs of unbounded length if they provide GET-based forms that could generate such URIs. A server SHOULD return 414 (Request-URI Too Long) status if a URI is longer than the server can handle (see section 10.4.15).
Note: Servers ought to be cautious about depending on URI lengths above 255 bytes, because some older client or proxy implementations might not properly support these lengths.
rfc2616:http://www.ietf.org/rfc/rfc2616.txt
现实中就是太长的url没什么用,太长的body部分也不是很好,所以各种客户端服务端的实现默认都有限制的这http种各个部分的长度。浏览器的我不清楚,服务端的http实现一般这个长度都是可以配置的,netty http的HttpServerCodec默认是4K长度(整个请求行,uri是请求行里面大头),tomcat是用maxHttpHeaderSize来配置请求行和header部分的总长度;post长度,netty http默认是8K,tomcat默认是maxPostSize=2M,tomcat的配置设置成-1就是无限长度,但是这么做在实际中一点意义没有。
第4点:安全,这个扯得有点远,也随便扯扯。 不是别人一眼看不到的就是安全,不是别人一眼看得到就不安全。http抓包很容易的,对路由器做点手脚就能够抓一堆移动设备的http请求包,移动设备的http请求你自己都一眼看不到,更不用说别人了,想要安全,还是用https吧,大多数人看到了也没用。
另外扯一句,Base64不是加密,用这个加密就是掩耳盗铃啊。
第5点:关于http response的缓存
get被建议做成幂等的,缓存是很有必要的,一般静态资源的get请求都是会设置有效缓存时间的,这一点很容易想明白。很多时候缓存get在服务器和浏览器中是默认行为,这对大量使用get请求的ajax不利,所以ajax请求一般会在请求url后加上一个随机数,浏览器和服务器就认为它是不同的get请求,不会缓存这个get请求。
关于post的缓存,现在的实际情况是绝大多数浏览器都不支持post缓存。
看了下rfc2616中关于post的response缓存的说明,发觉说得很混乱,它主要有两个地方说了post的缓存。
第一个是关于post方法的说明中(9.5小节):
Responses to this method are not cacheable, unless the response includes appropriate Cache-Control or Expires header fields. However, the 303 (See Other) response can be used to direct the user agent to retrieve a cacheable resource.
这段话也就是说,是否缓存post的response,是根据http请求头中的Cache-Control、Expires决定的。
还有一个位置,13.10小节(13节是专门说缓存的):
In this section, the phrase “invalidate an entity” means that the cache will either remove all instances of that entity from its storage, or will mark these as “invalid” and in need of a mandatory revalidation before they can be returned in response to a subsequent request.
Some HTTP methods MUST cause a cache to invalidate an entity. This is either the entity referred to by the Request-URI, or by the Location or Content-Location headers (if present). These methods are:
- PUT
- DELETE
- POST
这段话是说 PUT DELETE POST 应该让缓存无效uri代表的实体——删除该实体的所有实例存储,或将这些标记为“无效”并需要强制性重新验证,然后才能返回以响应后续操作请求。
我觉得rfc2616中的两处规定有冲突啊,都说叫POST无效缓存,那还缓存毛线啊!
stackoverflow上有个问题讨论这个,感觉也没说明白:http://stackoverflow.com/questions/626057/is-it-possible-to-cache-post-methods-in-http
后来看了下rfc7231,它是对rfc2616的补充说明,其中关于POST的缓存说明如下:
Responses to POST requests are only cacheable when they include explicit freshness information (see Section 4.2.1 of [RFC7234]). However, POST caching is not widely implemented. For cases where an origin server wishes the client to be able to cache the result of a POST in a way that can be reused by a later GET, the origin server MAY send a 200 (OK) response containing the result and a Content-Location header field that has the same value as the POST’s effective request URI (Section 3.1.4.2).
这段话说POST的resp在某些条件下可以被缓存,但是客户端很少实现这个功能,具体是什么条件,在rfc7234这篇专门说http缓存中说了,不过我看得不是很明白。
总之根据上面几个rfc的意思,POST的resp实际上是允许被缓存的,但是一般都不实现这个。
浏览器不实现是有道理的,现实中POST大多执行的是写操作,缓存写操作结果无意义,还有POST可以说是登录/支付这类功能的标准方法了,双方交流的是敏感数据,缓存这类数据的安全隐患很大。
总结:工作也有些时间了,我也不是一个纯小白了,了解了一些方法和途径,该多靠自己的力量去弄懂些东西。还有,这个问题一路走来也是深有感触啊,网上搜到的东西不一定正确,排名靠前的也不一定是最真的,但确是那些初学者最能依赖的。像我这种工作的时候自己捣鼓无意间发现的还算幸运啊,毕竟这个问题,对于很多人,毕业的时候就定型了,可能会一辈子错下去。
——以上内容如有各种问题,烦请指出,谢谢各位^_^——