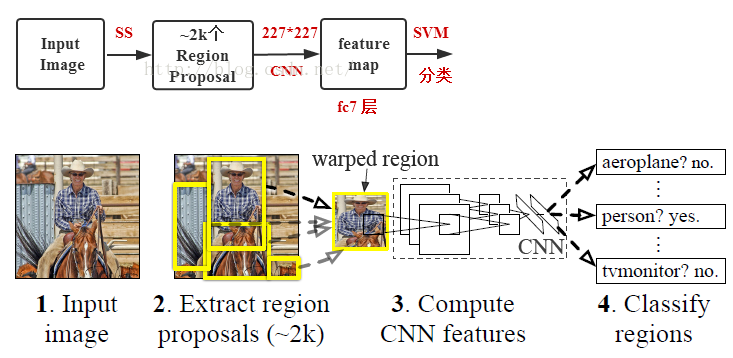
测试过程:
- 输入图像,采用Selective Search 从原始图片中提取2000个左右区域候选框;
- 将所有候选框变为固定大小的(227*227)区域;(归一化)
- 使用CNN网络提取每个建议框的特征(pool5层);
- 用SVM作分类,作非极大值抑制;
- bounding-box回归得到物体的种类以及位置信息。
训练过程(不连续):
- ILSVRC 2012上预训练CNN
- PASCAL VOC 2007上微调CNN
- 做20类SVM分类器的训练
- 20类bounding-box回归器的训练
1、测试
1、建议框归一化方法

经过作者一系列实验表明采用padding=16的各向异性变形即下图第二行第三列效果最好,能使mAP提升3-5%。
2、CNN(alexnet)提取特征
AlexNet不用最后的全连接层,提取出1*1*4096维的特征向量。
3、训练分类器SVM
每一类对应一个分类器。训练SVM的正负样本:采用IOU阈值样本,计算每一个region proposal与标准框的IOU,当大于阈值0.3时则为正样本,小于阈值0.3时为负样本。
CNN提取的区域特征2000*4096 X SVM权值矩阵 4096*20 == 最后得到2000个边界框对应20个类的概率值(得分)。
由于负样本太多了,所以采用hard negative mining,将特别容易分错的负样本(类似于错题集)放入负样本集中再训练,对网络的分类性能有很大帮助。
4、bounding box回归:
对分类好的区域做边框回归。CNN生成每个region proposal 固定长度的特征向量,svm计算每个region特征向量的score,并进行排序。然后利用NMS得到最终的概率最大的一些区域。
知乎上有人说R-CNN需要两次前向计算,第一次得到建议框特征给svm分类识别,第二次对非极大抑制后的建议框再次进行CNN前向计算获得Pool5特征,以便对建议框进行回归得到更精确的bounding-box,这里文中并没有说是怎么做的,博主认为也可能在计算2k个建议框的CNN特征时,在硬盘上保留了2k个建议框的Pool5特征,虽然这样做只需要一次CNN前向网络运算,但是耗费大量磁盘空间。
2、训练
1、预训练CNN
大样本进行预训练网络,得到最后一层的1000x4096特征;
2、微调网络
小样本进行fine tune。
| 样本 | 来源 |
|---|---|
| 正样本 | Ground Truth+与Ground Truth相交IoU>0.5的建议框【由于Ground Truth太少了】 |
| 负样本 | 与Ground Truth相交IoU≤0.5的建议框 |
PASCAL VOC 2007样本集上既有图像中物体类别标签,也有图像中物体位置标签;
采用训练好的AlexNet CNN网络进行PASCAL VOC 2007样本集下的微调,学习率=0.001【0.01/10为了在学习新东西时不至于忘记之前的记忆】;
该网络输入为建议框【由selective search而来】变形后的227×227的图像,修改了原来的1000为类别输出,改为21维【20类+背景】输出,训练的是网络参数。
3、svm训练
| 样本 | 来源 |
|---|---|
| 正样本 | Ground Truth |
| 负样本 | 与Ground Truth相交IoU<0.3的建议框 |
SVM训练时输入正负样本在AlexNet CNN网络计算下的4096维特征,输出为该类的得分,训练的是SVM权重向量。由于负样本太多,采用hard negative mining的方法在负样本中选取有代表性的负样本。
4、bounding box回归训练
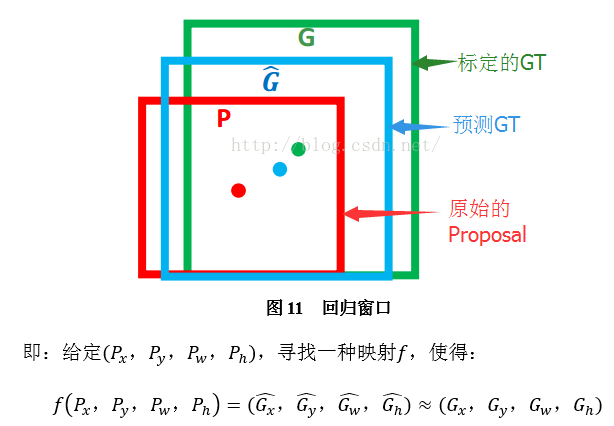


输入:
其实真正的输入是这个窗口对应的CNN特征,也就是R-CNN中的AlexNet Pool5 feature(特征向量)。(注:训练阶段输入还包括 Ground Truth,也就是下边提到的
)
输出:
需要进行的平移变换和尺度缩放
,或者说是
。
我们的最终输出不应该是Ground Truth吗?是的,但是有了这四个变换我们就可以直接得到Ground Truth。
这四个值应该是经过 Ground Truth 和Proposal计算得到的真正需要的平移量
和尺度缩放
。
这也就是R-CNN中的:
目标函数
我们要让预测值跟真实值
差距最小,得到损失函数为:
是输入Proposal的特征向量
是要学习的参数 (*表示
,也就是每一个变换对应一个目标函数,就是所需要学习的回归参数)
是得到的预测值。
函数优化目标
损失函数中加入正则项是为了避免归回参数过大。
利用梯度下降法或者最小二乘法就可以得到
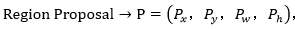
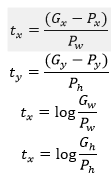
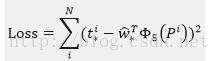
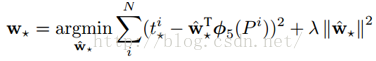
注意:只有当Proposal和Ground Truth比较接近时(线性问题),我们才能将其作为训练样本训练我们的线性回归模型,否则会导致训练的回归模型不work(当Proposal跟GT离得较远,就是复杂的非线性问题了,此时用线性回归建模显然不合理)。
例如:
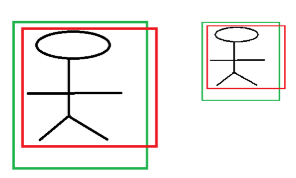
上图是同一目标,只是尺度不同,由于CCN具有尺度不变性,所以实际上这两个偏移程度是相同,但是偏移量是不同的,所以要做尺度归一化,这样得到的便宜量以相同了。
Log函数明显不满足线性函数,但是为什么当Proposal 和Ground Truth相差较小的时候,就可以认为是一种线性变换呢?高数知识:
当且仅当Gw−Pw=0的时候,才会是线性函数,也就是宽度和高度必须近似相等。
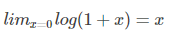
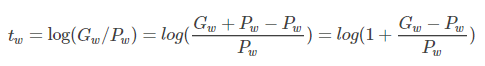
3、缺点
- 速度慢;
- 复杂
- 费空间、时间