AP衡量的是训练出来的模型在每个类别上的好坏。
mAP衡量的是训练出来的模型在所有类别上的好坏,mAP就是AP的均值,反映的是全局性能。
PR曲线
训练好的模型对所有的测试样本计算出confidence score,每一类confidence score排序(比如一共有20个样本):

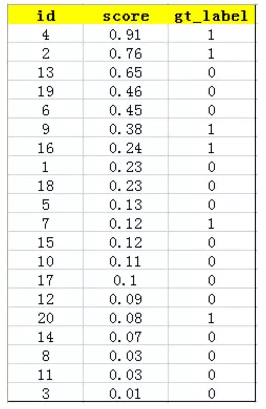
然后计算precision和recall,得到PR曲线:
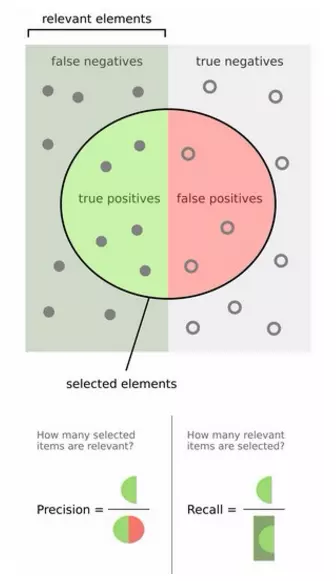

很显然选的样本增多,recall肯定会越来越多,而precision整体会下降趋势。
准确率和召回率是互相影响的,理想情况下肯定是做到两者都高,但是一般情况下准确率高、召回率就低,召回率低、准确率高,当然如果两者都低,那是什么地方出问题了。
如果是做搜索,那就是保证召回的情况下提升准确率;如果做疾病监测、反垃圾,则是保准确率的条件下,提升召回。
AP
PASCAL VOC CHALLENGE计算方法:
- 旧版(point interpolated average precision11点插值平均精度):先设定一组阈值,recall每大于一个阈值,就得到对应的最大的一个precision,得到11个precision,AP就是平均值;
- 新版: 假设一共有m个正例,会有m个recall值,即为m个阈值,同上得到m个precision,平均值就是AP;
mAP
AP取平均值。
ROC
ROC和AUC是评价分类器的指标。
ROC关注两个指标,正例分对的概率和负例分错的概率。
True Positive Rate ( TPR ) = TP / [ TP + FN] ,TPR代表能将正例分对的概率
False Positive Rate( FPR ) = FP / [ FP + TN] ,FPR代表将负例错分为正例的概率
横坐标是FPR,纵坐标是TPR,描绘了分类器在TP(真正的正例)和FP(错误的正例)间的trade-off。
对于二值分类问题,实例的值往往是连续纸,我们通过设定一个阈值,将实例分类到正类或者负类(比如大于阈值划分为正类)。因此我们可以变化阈值,根据不同的阈值进行分类,根据分类结果计算得到ROC空间中相应的点,连接这些点就形成ROC curve。

ROC curve经过(0,0)(1,1),实际上(0,0)和(1, 1)连线形成的ROC curve实际上代表的是一个随机分类器。
一般情况下,这个曲线都应该处于(0, 0)和(1, 1)连线的上方。
AUC(Area Under roc Curve)
用ROC curve来表示分类器的performance很直观好用。可是,人们总是希望能有一个数值来标志分类器的好坏。
于是AUC。顾名思义,AUC的值就是处于ROC curve下方的那部分面积的大小。
通常,AUC的值介于0.5到1.0之间,较大的AUC代表了较好的Performance。