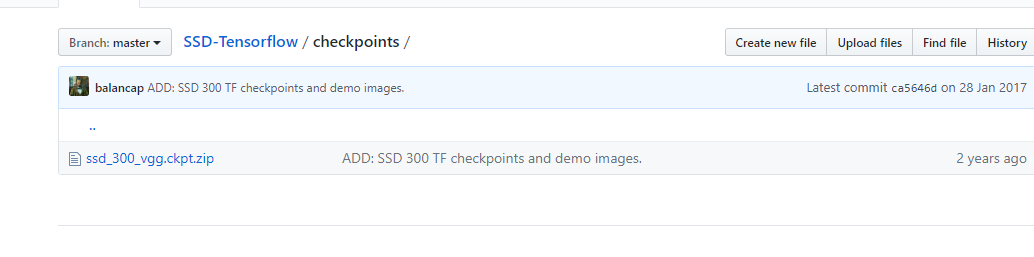
测试就是用voc2007的test set来测试已经训练好的checkpoint的mAP,github上提供了三个已经训练好的model的checkpoint
checkpoint 里面已有的300_vgg_ckpt这个文件很有可能就是下图圈住的模型,因为这两个文件的大小是一模一样的
需要做的准备有:
1. 下载voc2007的数据集,然后将test set转化成tfrecord(在转化时,源码只使用了annotations和jpegimages两个文件夹的内容来制作tfrecords)
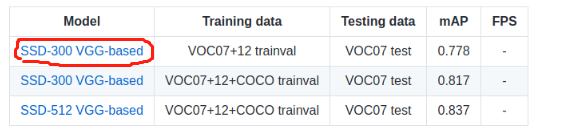
2. 下载checkpoint,如voc2007和voc2012训练集训练的checkpoint(这个要到github上SSD的主页去下载,但是好像被墙了,不下载其实也没关系,因为前面自带的有一个checkpoint是可以用的)
下载好的voc2007文件test set 结构是这样的:
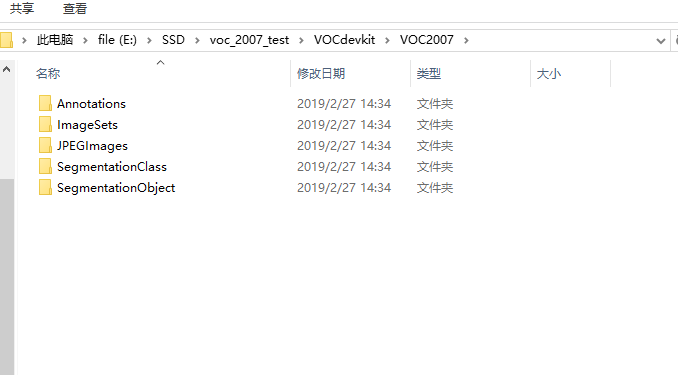
调用tf_convert_data.py将test set转化成tfrecoeds,(注意:这里直接运行会碰到无法读取图片,UTF-8无法decode的Erro,解决办法是打开SSD工程—>datasets—>pascalvoc_to_tfrecords.py 。。。然后更改文件的83行读取方式为’rb’)

DATASET_DIR=./VOC2007/ #下载的voc数据集总文件夹 OUTPUT_DIR=./tfrecords #用来放生成的tfrecord文件的文件夹 python tf_convert_data.py --dataset_name=pascalvoc #必须是pascalvoc,代码里面默认的 --dataset_dir=${DATASET_DIR} --output_name=voc_2007_train #必须是这个格式的,例如:voc_2012_test --output_dir=${OUTPUT_DIR}
生成测试集tfrecord后,调用eval_ssd_network.py使用刚刚生成好的tfrecords来测试checkpoint的准确率:
DATASET_DIR=/home/wu/voc2007_test_tfrecords/ #保存tfrecords的路径 EVAL_DIR=/home/wu/ssd_eval_log/ #是自己设置用来保存测试结果的路径(生成结果后,在该路径下运行tensorboard可以查看可视化的结果) CHECKPOINT_PATH=/home/wu/Downloads/SSD-Tensorflow-master/checkpoints/VGG_VOC0712_SSD_300x300_iter_120000.ckpt 是下载的checkpoint的路径(如果未下载可以使用SSD工程本来自带的checkpoint) python3 ./eval_ssd_network.py --eval_dir=${EVAL_DIR} --dataset_dir=${DATASET_DIR} --dataset_name=pascalvoc_2007 #或者pascalvoc_2012,代码里面有默认的几个选项 --dataset_split_name=test #必须是test --model_name=ssd_300_vgg --checkpoint_path=${CHECKPOINT_PATH} --batch_size=1 #可根据自己电脑设置
补充:
SSD输出mAP时出现TypeError: Can not convert a tuple into a Tensor or Operation???
解决方法为在eval_ssd_network.py文件中添加下面一个函数:
1 def flatten(x): 2 result = [] 3 for el in x: 4 if isinstance(el, tuple): 5 result.extend(flatten(el)) 6 else: 7 result.append(el) 8 return result
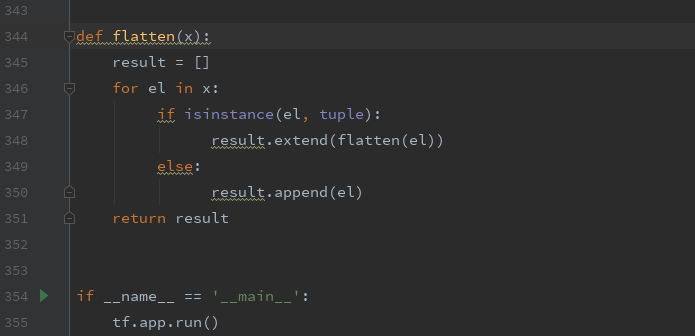
然后修改两行代码:
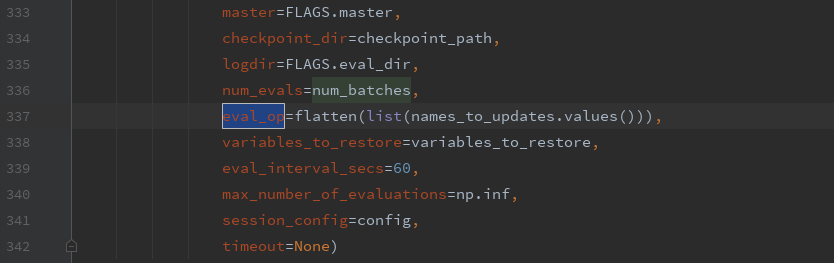
1 将 eval_op=list(names_to_updates.values()) 2 3 改为 eval_op=flatten(list(names_to_updates.values())) 4 5 注意:共有两行!