之前我们都是识别一张图片中的单一物体,在实际应用过程中,会遇到问题,就是我们需要识别的物体,未必会给我们机会去“摆拍”。
我们想要的数据是这样的:

实际上我们从摄像头得到的是这样的:

不仅要识别目标,更需要对目标进行定位 ——没有人会帮我们用截图工具从第二张图中“抠图”,得到第一张图中的样式,再给我们去训练深度学习模型。
如何在上图中识别车辆和行人?(以SSD为例子)

一、物体识别与定位原理
1、思路一——基于网格搜索
首先是物体 识别问题 ,CIFAR-10 给出了物体的截图信息:

根据这些截图训练出一个分类器来:
model.fit_generator(datagen.flow(X_train, Y_train, batch_size=batch_size), nb_epoch=nb_epoch, validation_data=(X_test, Y_test), callbacks=[tb])
训练好分类器 model 之后,可以载入新的图片,用训练好的模型预测分类结果:
# 使用训练好的模型,预测输入图片属于 CIFAR-10 哪个类 import cv2 NEW_IMG_MATRIX = cv2.imread("test.png") NEW_IMG_MATRIX = cv2.resize(NEW_IMG_MATRIX, (32, 32)) predictions = model.predict(NEW_IMG_MATRIX)
有了分类器,接下来就是用分类器扫描整张图像,定位特征位置。关键就是用什么算法扫描?
方法一:将图片分成若干网格,用分类器一格一格的扫描
这种方法的问题:
1、目标正好处在两格的交界处,这样分类器的结果在两边都不显著,容易造成漏报(True Negative)
2、目标过大或过小,导致网格结果不显著,也容易遭成漏报。
解决这两个问题的方法:
1、可以采用互相重叠的网格,比如一个网格大小是 32x32 像素,那么就网格向下移动时,只动 8 个像素,走四步才完全移出以前的网格。
2、可以采用大小网格相互结合的方法,32x32 网格扫完,64x64 网格再扫描一次,16x16 网格也再扫一次。
带来的问题:我们为了保证准确率,对同一张照片扫描次数过多,严重影响了计算速度,造成这种策略无法做到实时标注。也就是说,如果应用在无人驾驶汽车时,如果前面突然出现一个行人,此时模型一遍一遍扫描整个图片、终于完成标注之后,可能已经是三四秒以后了,此时汽车已经开出去几十米,会造成很大的危险。
2、思路二——深度学习框架对网格搜索的改进
为了快速、实时标注图像特征,对于整个识别定位算法,就有了诸多改进方法。
一个最基本的思路是,合理使用卷积神经网络的内部结构,避免重复计算。
用卷积神经网络扫描某一图片时,实际上卷积得到的结果已经存储了不同大小的网格信息,这一过程实际上已经完成了我们上一部分提出的改进措施,如下图所示,我们发现前几层卷积核的结果更关注细节,后面的卷积层结果更加关注整体:

对于问题1,如果一个物体位于两个格子的中间,虽然两边都不一定足够显著,但是两边的基本特征如果可以合理组合的话,我们就不需要再扫描一次。而后几层则越来越关注整体
对问题2,目标可能会过大过小,但是特征同样也会留下。
也就是说,用卷积神经网络扫描图像过程中,由于深度神经网络本身就有好几层卷积、实际上已经反复多次扫描图像, 以上两个问题可以通过合理使用卷积神经网络的中间结果得到解决 。
在 SSD 算法之前,MultiBox,FastR-CNN 法都采用了两步的策略,即第一步通过深度神经网络,对潜在的目标物体进行定位,即先产生Box;至于Box 里面的物体如何分类,这里再进行第二步计算。此外第一代的 YOLO 算法可以做到一步完成计算加定位,但是结构中采用了全连接层,而全连接层有很多问题,并且正在逐步被深度神经网络架构“抛弃”。
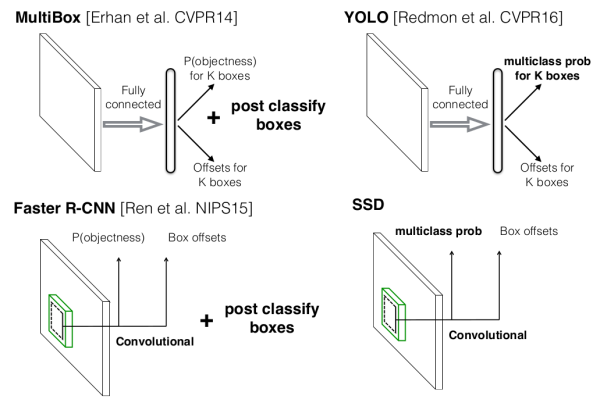
SSD 就是一种一步完成计算、不采用全连接层的计算架构。一步到位的计算框架可以使计算速度更快,并且由于完全抛弃全连接层,全连接层带来的过拟合问题也会得到改善。

二、SSD
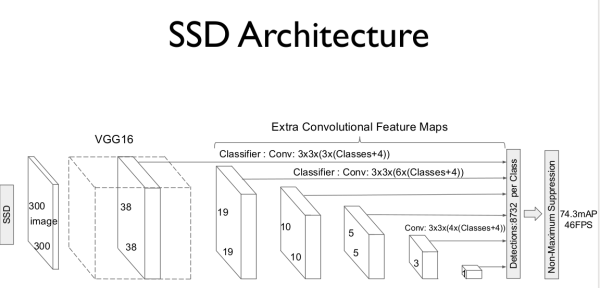
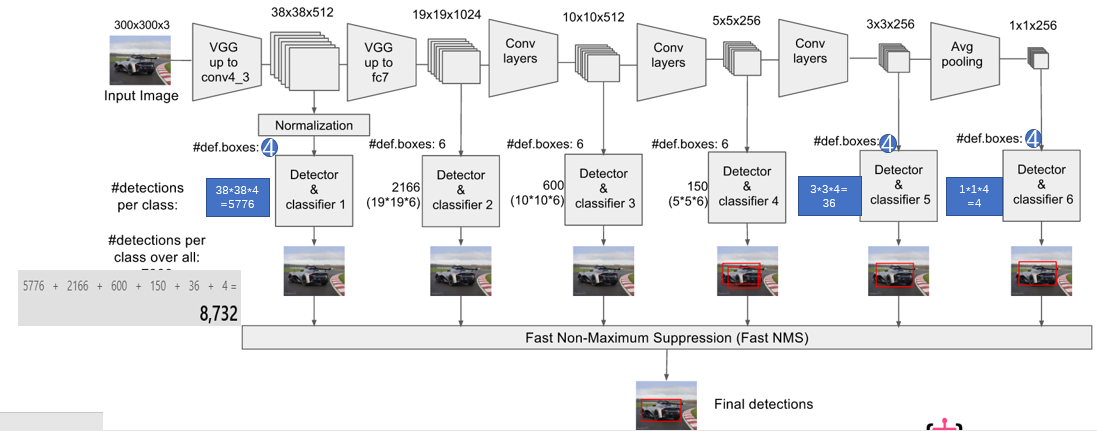
大体思路,使用VGG深度神经网络的前五层,再额外加6层,然后提取其中几层(4,7,8,9,10,11)经过卷积后的结果,进行网格搜索,找到目标特征。
在卷积的结果中搜索网格的位置:
这里的关键是生成网格。
首先,由于 3x3 大小的卷积核,在卷积神经网络部分已经扫描了整个输入图像,并且还反复扫了很多层,所以这里不再需要考虑手动分网格是否会遗漏信息,因为各种卷积核已经将整张图像完全扫描一遍了。
同时,我们注意到 VGG16卷积层的像素大小在逐步降低,而各层表示的都是同样的输入图像,也就是说,单个像素所能表征的物体大小,是在逐步增加的,所以也不需要考虑物体大小的影响。
根据刚才的网络定义,SSD 会在 4、7、8、9、10、11 这六层生成搜索网格(Anchor Boxes),并且其位置也是固定的。这几层搜索网格特征如下:
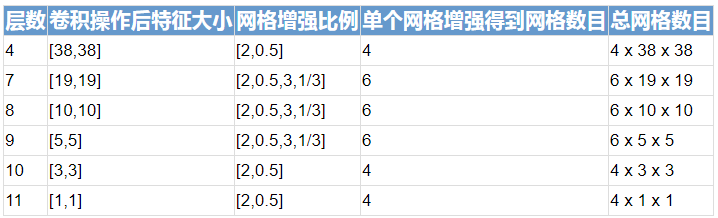
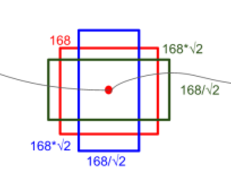
单个网格增强得到网格数目 = 1(原有) + 1(同时缩小) + 网格增强数目/2(长缩小宽放大、长扩大宽缩小)
网格增强比例,指的是在同一位置,原有宽度乘以一个系数、长度除以一个系数,得到新的长宽。当这个系数是 2 时,增强结果如下图:
整个过程如图所示: