目录
简介
决策树简单用法
决策树检测P0P3爆破
决策树检测FTP爆破
随机森林检测FTP爆破
简介
决策树和随机森林算法是最常见的分类算法;
决策树,判断的逻辑很多时候和人的思维非常接近。
随机森林算法,利用多棵决策树对样本进行训练并预测的一种分类器,并且其输出的类别是由个别决策树输出的类别的众数决定。
决策树简单用法
使用sklearn自带的iris数据集
# -*- coding: utf-8 -*- from sklearn.datasets import load_iris from sklearn import tree import pydotplus
"""
如果报错GraphViz's executables not found,手动添加环境变量
"""
import os
os.environ["PATH"] += os.pathsep + 'D:/Program Files (x86)/Graphviz2.38/bin/' #注意修改你的路径
iris = load_iris() clf = tree.DecisionTreeClassifier() clf = clf.fit(iris.data, iris.target) #可视化训练得到的决策树 dot_data = tree.export_graphviz(clf, out_file=None) graph = pydotplus.graph_from_dot_data(dot_data) graph.write_pdf("../photo/6/iris.pdf")
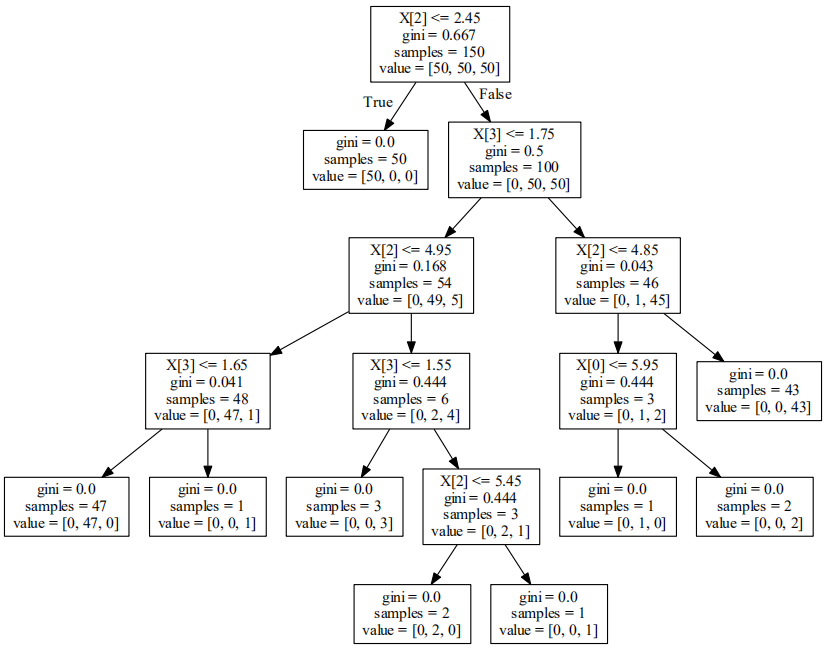
决策树算法检测P0P3爆破
# -*- coding:utf-8 -*- import re from sklearn import cross_validation from sklearn import tree import pydotplus import os os.environ["PATH"] += os.pathsep + 'D:/Program Files (x86)/Graphviz2.38/bin/' #注意修改你的路径 """ 收集并清洗数据 """ def load_kdd99(filename): x=[] with open(filename) as f: for line in f: line=line.strip(' ') line=line.split(',') x.append(line) return x def get_guess_passwdandNormal(x): v=[] w=[] y=[] """ 筛选标记为guess-passwd和normal且是P0P3协议的数据 """ for x1 in x: if ( x1[41] in ['guess_passwd.','normal.'] ) and ( x1[2] == 'pop_3' ): if x1[41] == 'guess_passwd.': y.append(1) else: y.append(0) """ 特征化 挑选与p0p3密码破解相关的网络特征以及TCP协议内容的特征作为样本特征 """ x1 = [x1[0]] + x1[4:8]+x1[22:30] v.append(x1) for x1 in v : v1=[] for x2 in x1: v1.append(float(x2)) w.append(v1) return w,y if __name__ == '__main__': v=load_kdd99("../data/kddcup99/corrected") x,y=get_guess_passwdandNormal(v) """ 训练样本 实例化决策树算法 """ clf = tree.DecisionTreeClassifier() #十折交叉验证 print(cross_validation.cross_val_score(clf, x, y, n_jobs=-1, cv=10)) clf = clf.fit(x, y) dot_data = tree.export_graphviz(clf, out_file=None) graph = pydotplus.graph_from_dot_data(dot_data) graph.write_pdf("../photo/6/iris-dt.pdf")
准确率达到99%
[ 0.98637602 1. 1. 1. 1. 1. 1. 1. 1. 1. ]
可视化结果
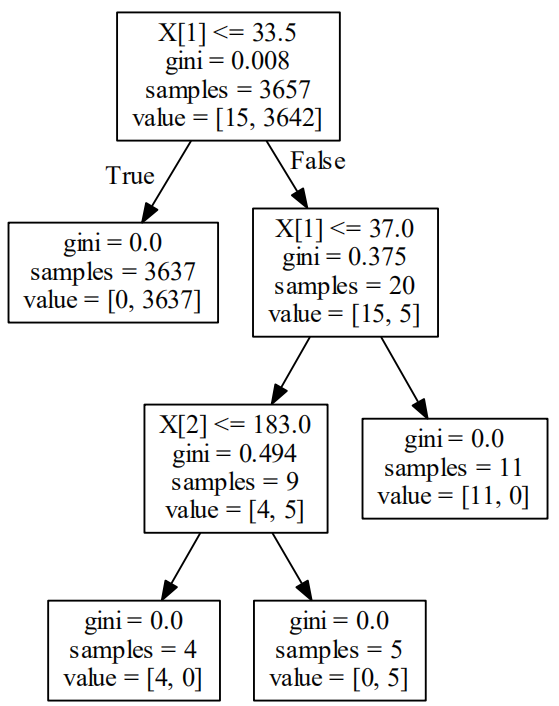
决策树算法检测FTP爆破
# -*- coding:utf-8 -*- import re import os from sklearn.feature_extraction.text import CountVectorizer from sklearn import cross_validation import os from sklearn import tree import pydotplus """ """ def load_one_flle(filename): x=[] with open(filename) as f: line=f.readline() line=line.strip(' ') return line """ 加载ADFA-LD中的正常样本数据 """ def load_adfa_training_files(rootdir): x=[] y=[] list = os.listdir(rootdir) for i in range(0, len(list)): path = os.path.join(rootdir, list[i]) if os.path.isfile(path): x.append(load_one_flle(path)) y.append(0) return x,y """ 定义遍历目录下文件的函数,作为load_adfa_hydra_ftp_files的子函数 """ def dirlist(path, allfile): filelist = os.listdir(path) for filename in filelist: filepath = os.path.join(path, filename) if os.path.isdir(filepath): dirlist(filepath, allfile) else: allfile.append(filepath) return allfile """ 从攻击数据集中筛选和FTP爆破相关的数据 """ def load_adfa_hydra_ftp_files(rootdir): x=[] y=[] allfile=dirlist(rootdir,[]) for file in allfile: """ rootdir下有多个文件,多个文件里又有多个文件 """ if re.match(r"../data/ADFA-LD/Attack_Data_Master/Hydra_FTP_d+\UAD-Hydra-FTP*",file): x.append(load_one_flle(file)) y.append(1) return x,y if __name__ == '__main__': """ 特征化 由于ADFA-LD数据集都记录了函数调用的序列,每个文件包含的函数调用序列的个数都不一致 """ x1,y1=load_adfa_training_files("../data/ADFA-LD/Training_Data_Master/") #x1{2184×833} y1{833} x2,y2=load_adfa_hydra_ftp_files("../data/ADFA-LD/Attack_Data_Master/") #x2{524×162} y2{162} x=x1+x2 y=y1+y2 #x{2184×995} y{955} vectorizer = CountVectorizer(min_df=1) #min_df如果某个词的document frequence小于min_df,则这个词不会被当作关键词 x=vectorizer.fit_transform(x) x=x.toarray() #x{142×955} #实例化决策树算法 clf = tree.DecisionTreeClassifier() #效果验证 print(cross_validation.cross_val_score(clf, x, y, n_jobs=-1, cv=10)) clf = clf.fit(x, y) dot_data = tree.export_graphviz(clf, out_file=None) graph = pydotplus.graph_from_dot_data(dot_data) graph.write_pdf("../photo/6/ftp.pdf")
[ 1. 0.98019802 0.95 0.97979798 0.96969697 0.88888889 0.98989899 0.95959596 0.92929293 0.95959596]
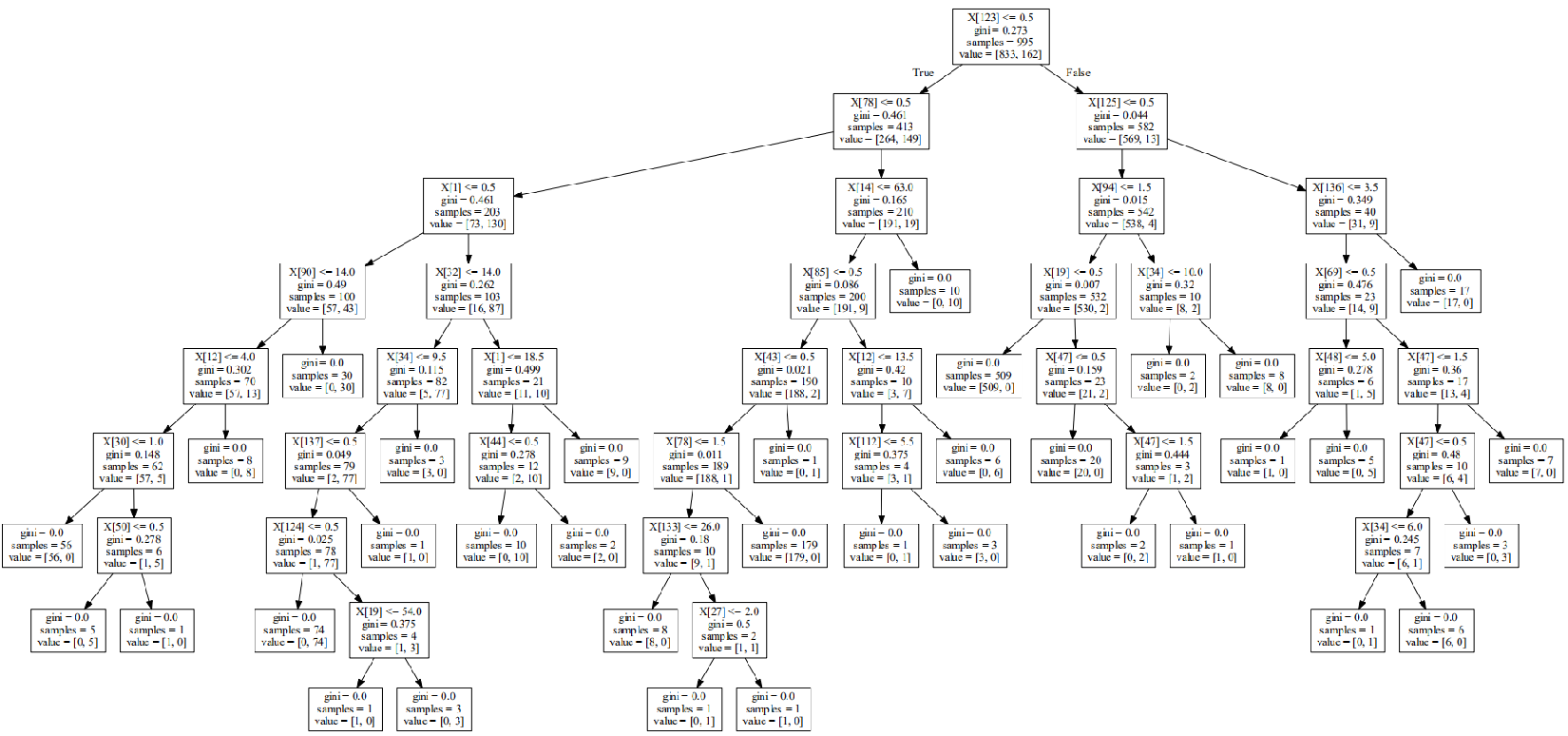
随机森林算法检测FTP爆破
# -*- coding:utf-8 -*-
#pydotplus只支持决策树 import re import os from sklearn.feature_extraction.text import CountVectorizer from sklearn import cross_validation import os from sklearn import tree from sklearn.ensemble import RandomForestClassifier import numpy as np def load_one_flle(filename): x=[] with open(filename) as f: line=f.readline() line=line.strip(' ') return line def load_adfa_training_files(rootdir): x=[] y=[] list = os.listdir(rootdir) for i in range(0, len(list)): path = os.path.join(rootdir, list[i]) if os.path.isfile(path): x.append(load_one_flle(path)) y.append(0) return x,y def dirlist(path, allfile): filelist = os.listdir(path) for filename in filelist: filepath = os.path.join(path, filename) if os.path.isdir(filepath): dirlist(filepath, allfile) else: allfile.append(filepath) return allfile def load_adfa_hydra_ftp_files(rootdir): x=[] y=[] allfile=dirlist(rootdir,[]) for file in allfile: if re.match(r"../data/ADFA-LD/Attack_Data_Master/Hydra_FTP_d+\UAD-Hydra-FTP*",file): x.append(load_one_flle(file)) y.append(1) return x,y if __name__ == '__main__': x1,y1=load_adfa_training_files("../data/ADFA-LD/Training_Data_Master/") x2,y2=load_adfa_hydra_ftp_files("../data/ADFA-LD/Attack_Data_Master/") x=x1+x2 y=y1+y2 #print(x) vectorizer = CountVectorizer(min_df=1) x=vectorizer.fit_transform(x) x=x.toarray() #print(y) #选用决策树分类器 clf1 = tree.DecisionTreeClassifier() score=cross_validation.cross_val_score(clf1, x, y, n_jobs=-1, cv=10) print('决策树',np.mean(score)) #选用随机森林分类器 clf2 = RandomForestClassifier(n_estimators=10, max_depth=None,min_samples_split=2, random_state=0) score=cross_validation.cross_val_score(clf2, x, y, n_jobs=-1, cv=10) print('随机森林',np.mean(score))
决策树 0.955736173617 随机森林 0.984888688869