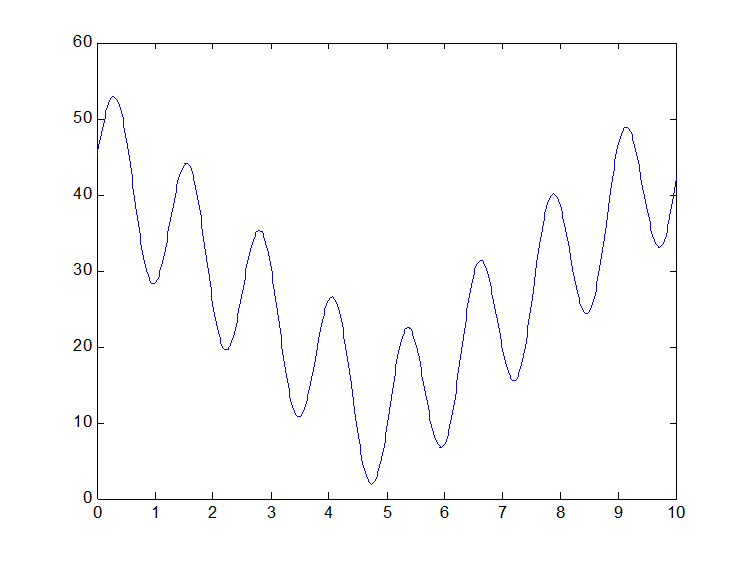
遗传算法优化函数y=10*sin(5*x)+7*abs(x-5)+10,这个函数图像为:
下面看代码:
(1)首先看主函数
function main()
clear;
clc;
%种群大小
popsize=100;
%二进制编码长度
chromlength=10;
%交叉概率
pc = 0.6;
%变异概率
pm = 0.001;
%初始种群
pop = initpop(popsize,chromlength);
for i = 1:100
%计算适应度值(函数值)
objvalue = cal_objvalue(pop);
fitvalue = objvalue;
%选择操作
newpop = selection(pop,fitvalue);
%交叉操作
newpop = crossover(newpop,pc);
%变异操作
newpop = mutation(newpop,pm);
%更新种群
pop = newpop;
%寻找最优解
[bestindividual,bestfit] = best(pop,fitvalue);
x2 = binary2decimal(bestindividual);
x1 = binary2decimal(newpop);
y1 = cal_objvalue(newpop);
if mod(i,10) == 0
figure;
fplot('10*sin(5*x)+7*abs(x-5)+10',[0 10]);
hold on;
plot(x1,y1,'*');
title(['迭代次数为n=' num2str(i)]);
%plot(x1,y1,'*');
end
end
fprintf('The best X is --->>%5.2f
',x2);
fprintf('The best Y is --->>%5.2f
',bestfit);
(2)下面看二进制种群生成的方法
%初始化种群大小 %输入变量: %popsize:种群大小 %chromlength:染色体长度-->>转化的二进制长度 %输出变量: %pop:种群 function pop=initpop(popsize,chromlength) pop = round(rand(popsize,chromlength)); %rand(3,4)生成3行4列的0-1之间的随机数 % rand(3,4) % % ans = % % 0.8147 0.9134 0.2785 0.9649 % 0.9058 0.6324 0.5469 0.1576 % 0.1270 0.0975 0.9575 0.9706 %round就是四舍五入 % round(rand(3,4))= % 1 1 0 1 % 1 1 1 0 % 0 0 1 1 %所以返回的种群就是每行是一个个体,列数是染色体长度
(3)下面看如何把二进制返回对应的十进制
%二进制转化成十进制函数
%输入变量:
%二进制种群
%输出变量
%十进制数值
function pop2 = binary2decimal(pop)
[px,py]=size(pop);
for i = 1:py
pop1(:,i) = 2.^(py-i).*pop(:,i);
end
%sum(.,2)对行求和,得到列向量
temp = sum(pop1,2);
pop2 = temp*10/1023;
(4)下面看计算适应度函数:
%计算函数目标值 %输入变量:二进制数值 %输出变量:目标函数值 function [objvalue] = cal_objvalue(pop) x = binary2decimal(pop); %转化二进制数为x变量的变化域范围的数值 objvalue=10*sin(5*x)+7*abs(x-5)+10;
(5)如何选择新的个体
上面所有个体的函数值都计算出来了,存在objvalue中,此时它是不是也是100组y值啊,恩,那么对于现有的随机生成的100组x,怎么来再选择100组新的更好的x呢?这里我们把选择放在了交叉与变异之间了,都可以,如何选择,就要构造概率的那个轮盘了,谁的概率大,是不是选择的个体就会多一些?也就是现在的选择就是100中100个,最后出现的就够就是以前的100个中最优的x有一个的话,选择完后,可能就变成5个这个x了,多余的4个是不是相当于顶替了以前的不好的4个x值,这样才能达到x总数100不变啊。
%如何选择新的个体
%输入变量:pop二进制种群,fitvalue:适应度值
%输出变量:newpop选择以后的二进制种群
function [newpop] = selection(pop,fitvalue)
%构造轮盘
[px,py] = size(pop);
totalfit = sum(fitvalue);
p_fitvalue = fitvalue/totalfit;
p_fitvalue = cumsum(p_fitvalue);%概率求和排序
ms = sort(rand(px,1));%从小到大排列
fitin = 1;
newin = 1;
while newin<=px
if(ms(newin))<p_fitvalue(fitin)
newpop(newin,:)=pop(fitin,:);
newin = newin+1;
else
fitin=fitin+1;
end
end
(6)怎么交叉
%交叉变换
%输入变量:pop:二进制的父代种群数,pc:交叉的概率
%输出变量:newpop:交叉后的种群数
function [newpop] = crossover(pop,pc)
[px,py] = size(pop);
newpop = ones(size(pop));
for i = 1:2:px-1
if(rand<pc)
cpoint = round(rand*py);
newpop(i,:) = [pop(i,1:cpoint),pop(i+1,cpoint+1:py)];
newpop(i+1,:) = [pop(i+1,1:cpoint),pop(i,cpoint+1:py)];
else
newpop(i,:) = pop(i,:);
newpop(i+1,:) = pop(i+1,:);
end
end
(7)怎么变异
%关于编译
%函数说明
%输入变量:pop:二进制种群,pm:变异概率
%输出变量:newpop变异以后的种群
function [newpop] = mutation(pop,pm)
[px,py] = size(pop);
newpop = ones(size(pop));
for i = 1:px
if(rand<pm)
mpoint = round(rand*py);
if mpoint <= 0;
mpoint = 1;
end
newpop(i,:) = pop(i,:);
if newpop(i,mpoint) == 0
newpop(i,mpoint) = 1;
else newpop(i,mpoint) == 1
newpop(i,mpoint) = 0;
end
else newpop(i,:) = pop(i,:);
end
end
(8)选择最优个体
%求最优适应度函数
%输入变量:pop:种群,fitvalue:种群适应度
%输出变量:bestindividual:最佳个体,bestfit:最佳适应度值
function [bestindividual bestfit] = best(pop,fitvalue)
[px,py] = size(pop);
bestindividual = pop(1,:);
bestfit = fitvalue(1);
for i = 2:px
if fitvalue(i)>bestfit
bestindividual = pop(i,:);
bestfit = fitvalue(i);
end
end
到这里遗传算法程序就算是结束了。
看部分图片结果:
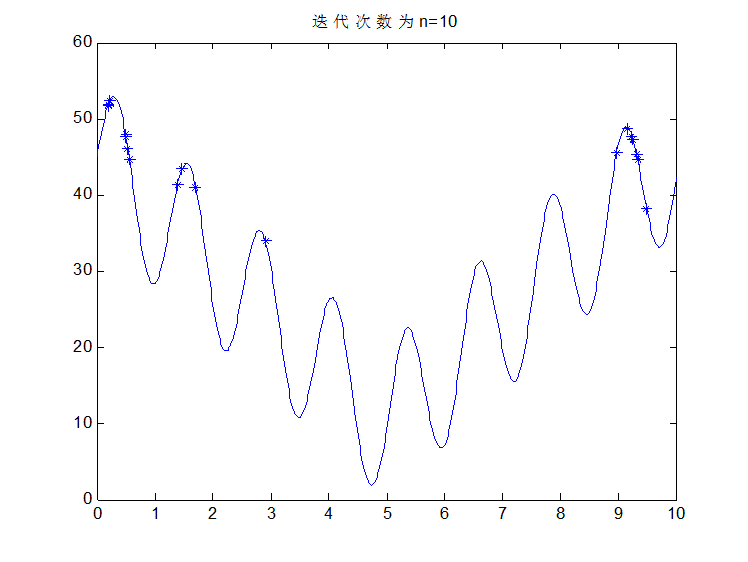
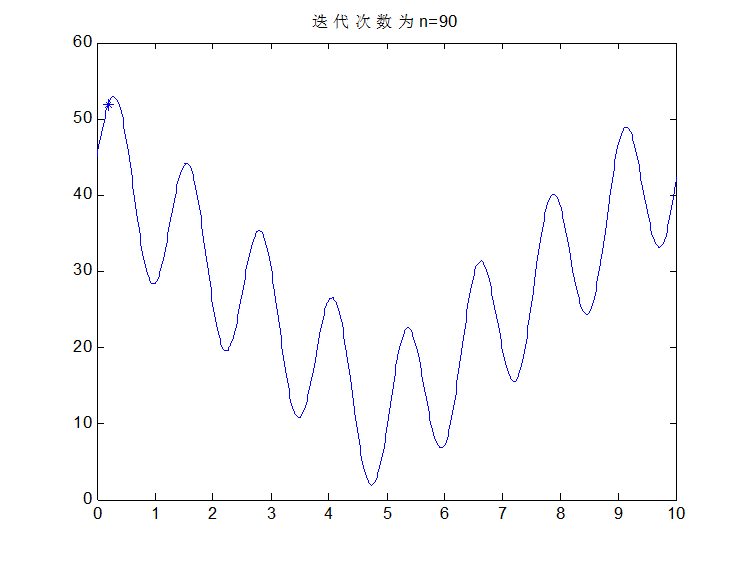
交叉
基本遗传算法(SGA)中交叉算子采用单点交叉算子。
单点交叉运算

变异

转:https://www.cnblogs.com/LoganChen/p/7509702.html