物理备份:备份原理 通过复制物理文件对数据库备份 复制时只需要读取表空间高水位以下的数据
恢复原理 将备份文件拷贝回数据库文件中 并将数据文件补充到备份大小
优点:物理文件读写 备份和恢复速度快 ,物理备份会备份redo文件 能够恢复到备份结束的所有数据 恢复完整度高
缺点: 不够灵活 不能针对表和用户恢复 适用于完全备份
逻辑备份:逻辑备份原理: 通过查询系统表 将对象创建语句拼接为sql 并存放到导出文件中
逻辑恢复: 按照用户指定的过滤规则导出文件中过滤执行需要恢复的对象
优点: 可以只恢复某个表或者某个用户的数据
回收站原理: 数据库回收站功能类似于windos回收站 将删除的表信息 保存到回收站中
删除的表状态设置为删除 数据仍然存储在数据文件中,可以通过purge命令彻底删除回收站中的数据
闪回原理: 利用回收站的闪回恢复删除的表---> 利用undo 日志闪回恢复到指定时间点的SCN点
SCN是一个全局增加得事务序号,每次事务提交SCN就会增加
undo日志记录的是修改前的数据 ,闪回恢复是在undo日志中满足需求指定时间的SCN或undo日志 利用undo日志恢复数据

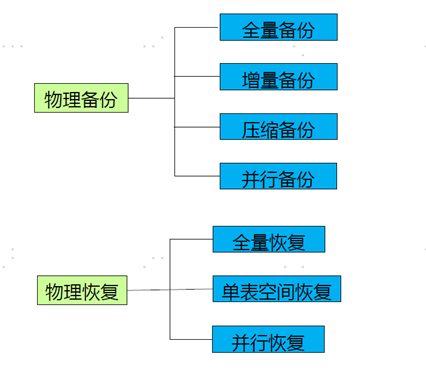
物理备份
全量备份: 对某一时间点 进行数据的完全复制,恢复不依赖之前备份
增量备份: 只备份上一次备份后变化的数据
增量备份的第一次必须是level0的基准备份
每次增量备份的数据量少 恢复时依赖之前的备份
备份压缩: 备份时候根据算法进行压缩 压缩后可以一定程度的减小备份集的大小 但是时间会变长
支持压缩算法 zstd lz4 zlib
压缩级别支持1-9 级别越高占用空间越小 时间花费越长
并行备份:单进程备份 速率慢 且未充分利用资源因此可以并行 加速备份速率
并行备份支持2-8线层并行
为了实现并行写 需要对备份文件按照并行度切分成多个文件 避免争用 提升备份速度
切分文件支持配置,配置范围128M-32T
备份前提:需要在归档模式下运行
备份文件保存的目录磁盘空间足够
主备环境 主机和备机都可以进行备份 ,但是备份备机时要保证和主机连接正常
只能在数据库处于open状态下执行备份
命令:backup database full format '/opt/backup/fullbackup.bak'; # 全量
bakcup database increamental level 0 format '/opt/backup/incrbase.bak' tag 'incrbase'; # 增量
backup database increamental level 1 format '/opt/backup/incr0001.bak' tag 'incr0001_bak' # 增量
压缩示例:
backup database full format '/opt/backup/fullzstd.bak' as zstd | lz4 | zlib compressed backupset ;
自动计算切分阈值 并发数为6
backup database full format '/opt/backup/fullzstd.bak' parallelism 6;
指定切分为1G 并发数量为2
backup database full format '/opt/backup/full012.bak' tag 'full1012_bak' parallelism 2 section threshold 1G ;
备份排除表空间 例如日志数据 历史数据
backup database full format ‘/opt/backup/exclude_bak1’ exclude for tablespace spc1,spc2 ;
恢复流程:
第一步: 恢复物理文件 将备份集中的数据写入数据文件中
第二步:重演redo日志 将redo日志中的数据恢复到备份时间点
第三步:修改数据库角色 只有恢复备机 或者级联备机需要
第四步:修改数据库状态 修改数据库状态到open
数据恢复模式 同步恢复 异步恢复
恢复前提条件:
要恢复的备份文件正确
服务器有足够的磁盘空间用来恢复数据库
清空数据路径下的data 目录中数据文件
恢复数据库必须在nomount模式下执行
命令
同步: restore database from '/opt/backup/fullbackup.bak' ;
异步: restore database from '/opt/backup/fullbackup.bak' disconnect from session ;
并发: restore database from '/opt/backup/fullbackup.bak' parallelism 2;
恢复指定表: restore database from '/opt/backup/fullbackup.bak' tablespace tsp ;
通过redo恢复数据
redo日志全部恢复: recover database ;
redo日志恢复指定时间点: recover database until time "2019-07-29 15:23:13";
修改数据库角色:
修改角色为备机:alter database convert to physical standby mount ;
修改角色为级联备机: alter database convert to cascaded physical standby mount ;
修改数据库状态:alter database open;
修改数据库到指定时间后,修改状态 : alter database open resetlogs;

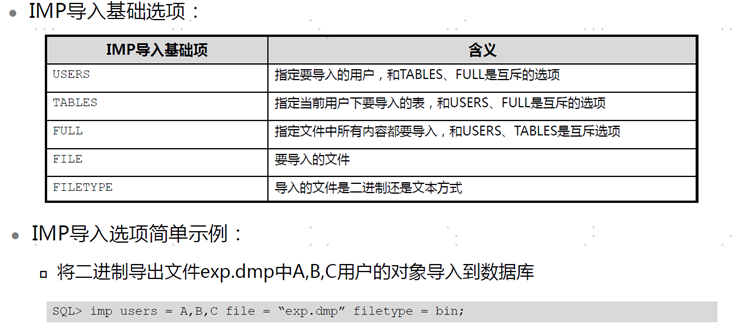
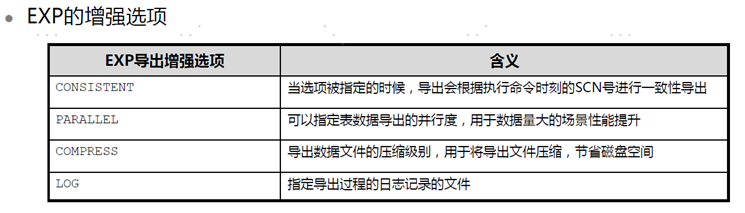
EXP数据库 逻辑导出工具
导出的粒度 用户导出 表导出
导出的文件格式 文件方式 二进制方式
EXP导出基本选项
users 和tables互斥
tables 和users互斥
files 导出的文件
filetype 文件类型二进制或者文本
简单示例:
exp users = A,B,C file = "exp.dmp" filetype =bin ; # abc 用户的对象导出到文件exp,dmp中
exp tables = T1,T2,T3,T4 file = "exp.dmp" filetype = bin; 导出当前登录用户的表T1 T2 T3
导出粒度:
用户 -->序列 表 表数据 索引 约束 外键 触发器 视图 函数 存储过程
表 --> 表 表数据 表上索引 约束 触发器
exp uses = A,B,C file = "exp.dmp" filetype = bin parallel = 16 compress = 1 log = "exp.log" consistent =Y ;


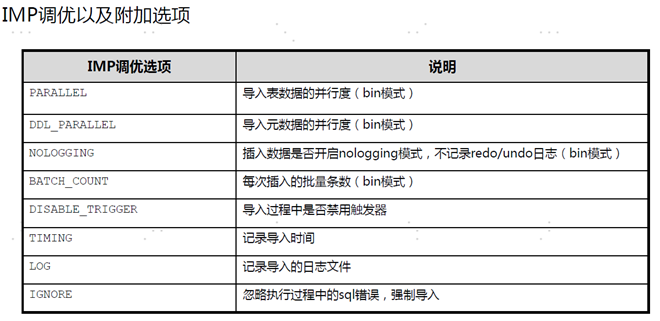
IPM数据库导入数据
如果exp 指定了filetype = bin ,IPM也需要指定filetype = bin
IPM导入粒度 按照用户导入 ,按照表导入
按照用户导入 会按照顺序过滤文件中用户的内容,将要导入的用户导入数据库
alter session set current_schema 切换用户标识语句
按照表导入 会按照顺序过滤文件中登录的用户下的表,然后将导入的表导入数据库
full是特殊情况 不过滤 直接将文件中的用户 所有对象导入到数据库中