HDFS JournalNode数据不同步告警 恢复指导
- 1 停止有问题的 JN 实例
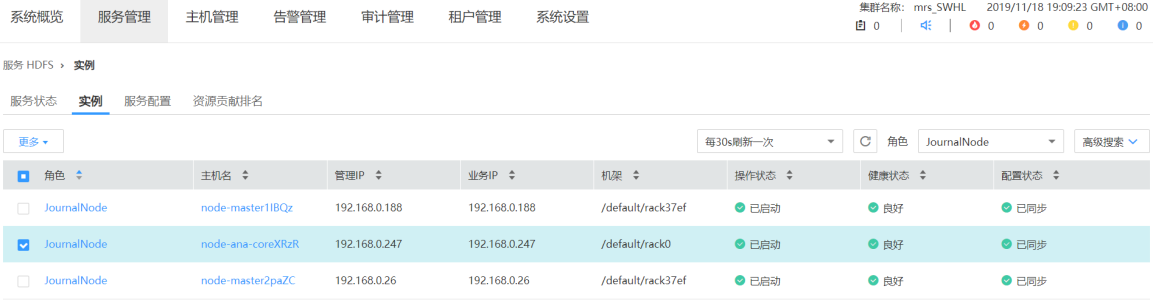
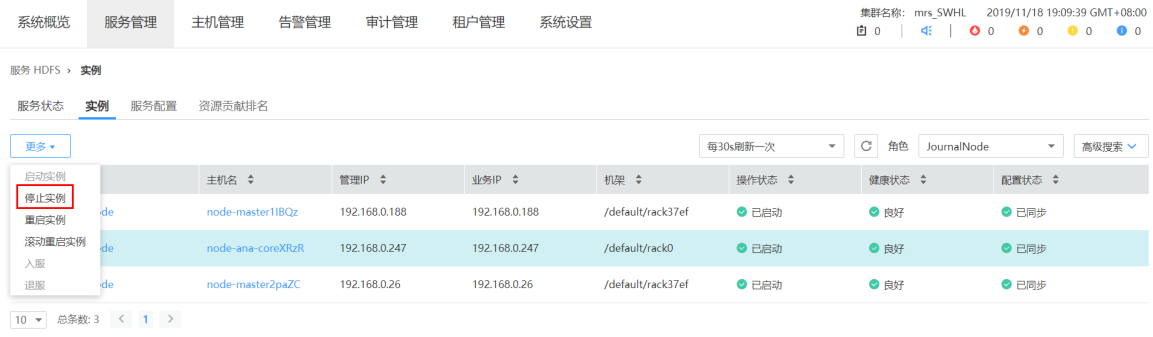
- 2 清楚无效数据
登录有问题JN的后台,使用omm用户操作以下命令:
1 cd /srv/BigData/journalnode/hacluster/current 2 rm -rf edits_* 3 rm committed-txid
操作完成之后确认是否只剩以下文件:

- 3 启动停止的 JN 实例
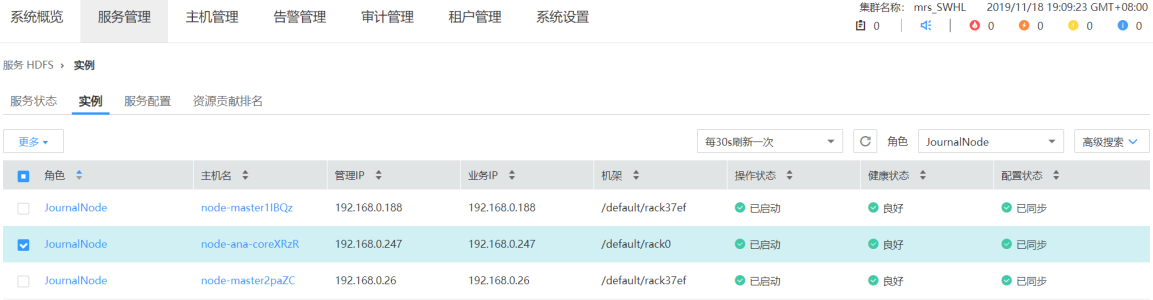
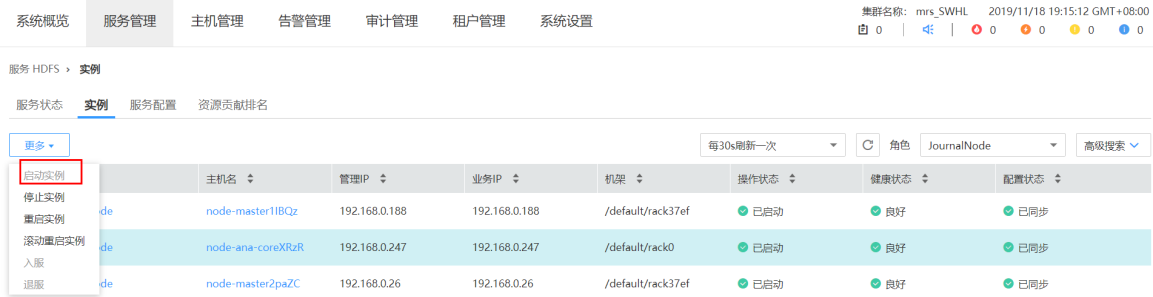
- 4 复制有效数据
本次提供命令中认为master节点的edits log是全的,您需要根据实际正常的节点来获取日
志;
用omm用户再异常的JN节点执行以下命令:
scp node-master1IBQz:/srv/BigData/journalnode/hacluster/current/edits_000*
/srv/BigData/journalnode/hacluster/current/
- 5 检查数据一致性
检查master节点与故障节点在/srv/BigData/journalnode/hacluster/current/下的edits_inprogress
文件的序号是否一致;一致则已经恢复;