Andrew Ng 机器学习笔记 ---By Orangestar
Week_11(the Last Week!!!!)
Congratulations on making it to the eleventh and final week! This week, we will walk you through a complex, end-to-end application of machine learning, to the application of Photo OCR. Identifying and recognizing objects, words, and digits in an image is a challenging task. We discuss how a pipeline can be built to tackle this problem and how to analyze and improve the performance of such a system.
1. Problem Description and Pipeline
这周要学习的是机器学习应用实例---照片OCR技术的应用实例
- 展示一个复杂的机器学习系统是如何被建立起来的
- 介绍机器学习流水线(machine learning pipeline)
- 决定下一步做什么的时候,如何分配资源
- 告诉你机器学习的诸多有意思的想法和理念
- 如何将机器学习应用到计算机视觉问题当中
- 人工数据合成(artificial data synthesis)
首先我们先了解 the photo OCR problem
就是把图像中的文字识别出来
有3步:

流水线表示:
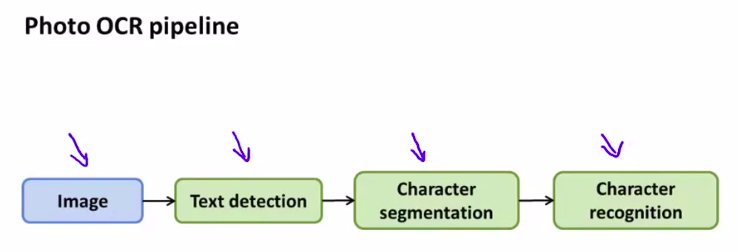
这就是 流水线的一个应用
2. Sliding Windows(滑动窗)
这节我们将关注一种叫做滑动窗的分类器
比如:识别行人:

用小窗来移动。每次都移动一个step。
每次都返回分类器去收集并处理。
然后,处理完后,用更大的小窗去执行同样步骤
最后,用滑动窗分类器去处理
当然,文字识别也差不多。

这意思就是白色的区域会有更大的概率有文字。但是还没完。我们实际上想做的是:在图像中有文字的各个区域都画上矩形窗。
所以,进一步,我们取出分类器的输出,然后输入到一个叫展开器(expansion operator)的东西里
展开器的作用就是:它会取过这张图片,对每一个白色的小点,都扩展为一块白色的区域。

这样,我们就可以直观的判断哪里可能有文字。
当然,即使是这样,也可能会漏掉一些文字。
流水线的第二步是字符分割:
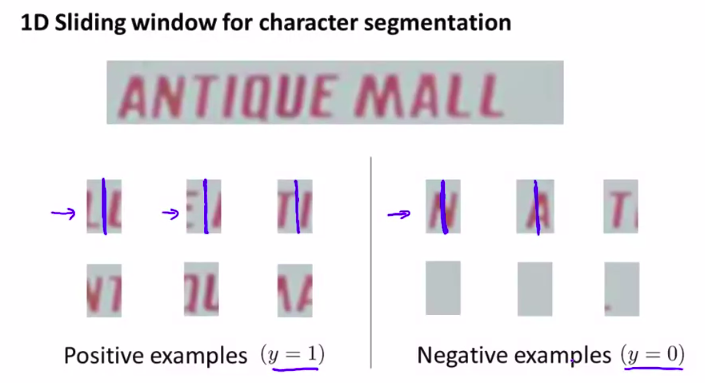
分割!!!!
移动窗好像一个算法,貌似也叫移动窗
如图:这样操作,看到可以分割就分割

最后,是字符分类。可以用一种标准的监督学习来识别字母。

3. Getting Lots of Data and Artificial Data
我们知道,要想得到一个比较高效的机器学习系统,其中一个最可靠的方法是,选择一个低偏差的学习算法,然后用一个巨大的训练集来训练
但是,如何得到巨大的训练集呢?
------ 人工数据合成!(artificial data synthesis)
如何得到一个更大的数据集?

例如上图,我们可以将这些样本加上不同的背景图片!
或者将样本做一些处理,模糊或者旋转什么的。
这样你会发现,这和真实的数据集十分相近。
这表示人工合成数据的一个实例
如图:
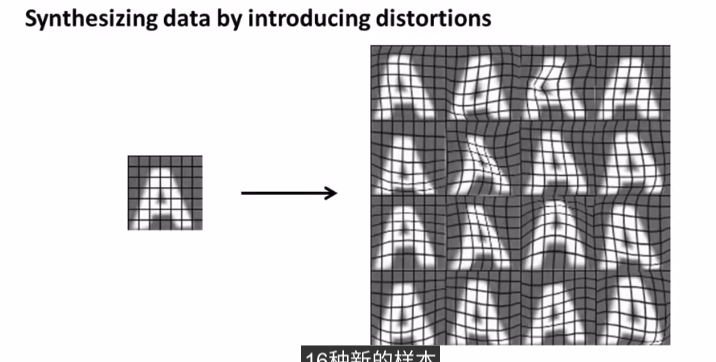
由一个样本可以合成出另外16个样本
但是,扩大的方法要慎重选择!
还有一种就是声音样本!

将一个样本加上背景噪音可能是一个很好的扩大训练样本的方法。或者将声音延长?
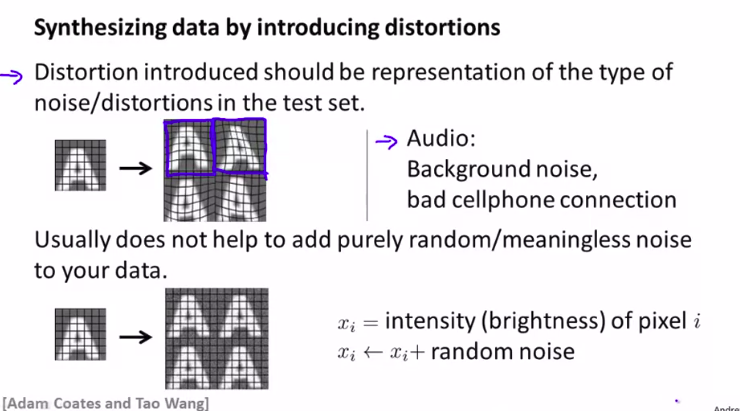
所以,选择扩大的方法的时候,我们要根据实际要求来选择。但是,在你的数据中添加一些纯随机的噪声,通常来讲是没有什么用的。所以,人工数据合成的过程并没有什么技巧可言。有候你只能一遍遍地尝试 然后观察效果但你在确定需要添加 什么样的变形时 你一定要考虑好 你添加的那些额外的变形量 是有意义的 能让你产生的训练样本 至少在某种程度上 是具有一定的代表性 能代表你可能会在测试集中看到的某种图像
所以,原则和前提如图:

笔记说的是,我们也要想想或者计算一下,我们如果是手动扩充数据集的话会花多长时间!有时候会比你猜的远远要小!****不要太过依赖人工合成数据!

4. Ceiling Analysis: What Part of the Pipeline to Work on Next
时间是最宝贵的!
所以,我们要用 上限分析ceiling canalysis
来避免无畏的劳动!要将团队的时间最大效率化
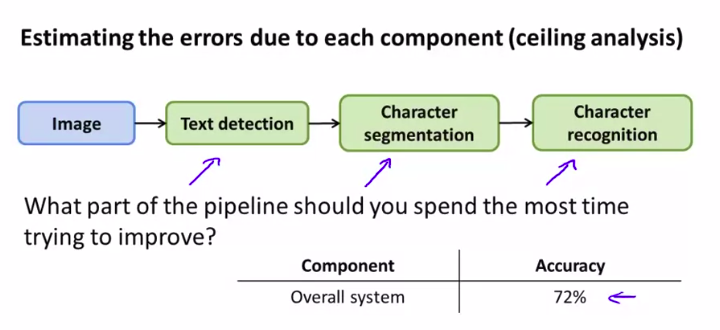
好,这是一个字符识别的流水线
然后:




懒癌。。。。。但是老师讲的应该比我总结的清楚得 多。而且这节也比较简单。
简而言之,就是不断去看,如果前面的是完美运行,看看总的会不会提高很多的准确度。如果是,就有值得改进的价值。反之,就不太值得被改进。


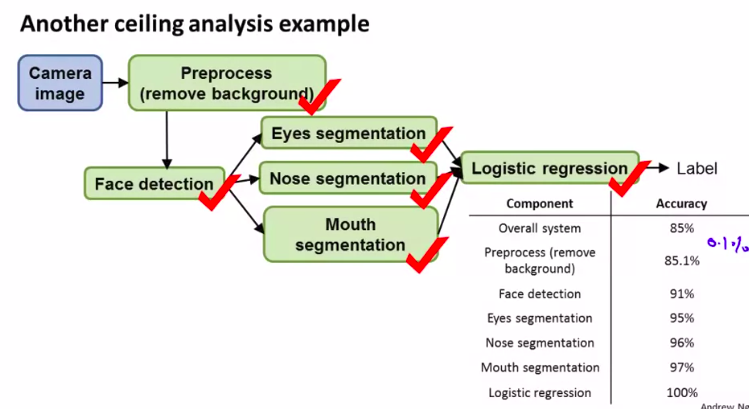
另一个例子::
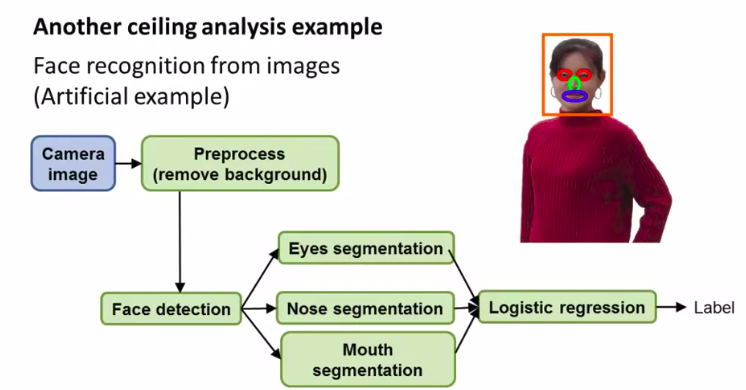
人脸识别
一样,我们用上限分析: