Introduction
作者认为目前广泛应用在text-image匹配中的ranking loss存在一个问题,即忽视了模态内的特征分布,可能造成图像域中两个相似图像难以得到区分。
本文的贡献包括以下三个方面:
1) 提出了一个名为instance loss的分类损失,挖掘同模态内的细微差异;
2) 设计了一个双分支CNN网络来提取文本-图像特征;
3) 在Flickr30k、MSCOCO、CUHK-PEDES上取得了SOTA。
Proposed CNN Structure
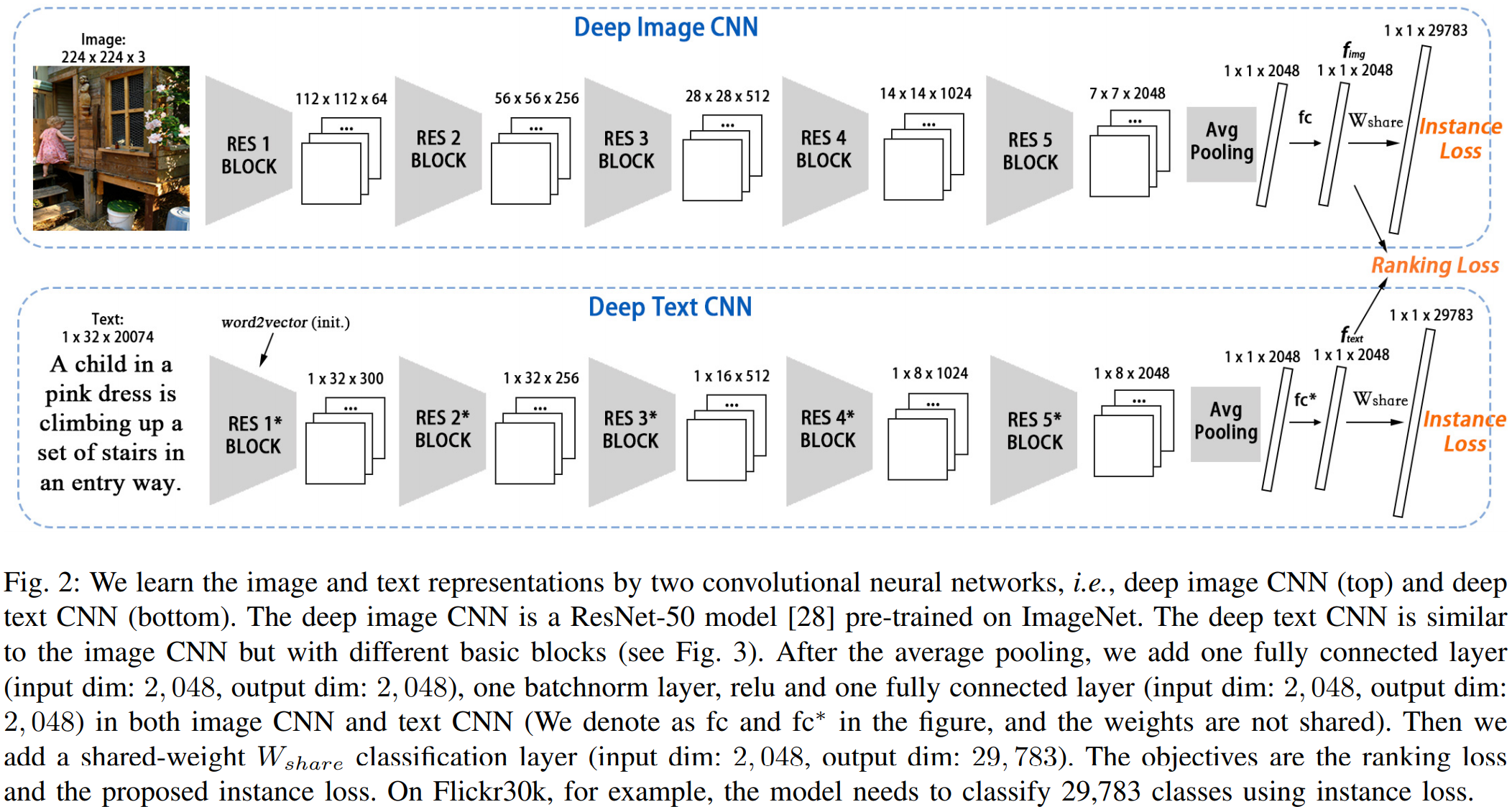
图像CNN分支采用了ResNet-50作为骨干网络,在提取出特征图后采用了Avg Pooling、FC、BN、ReLU、FC,得到2048维的特征向量,即:![]() 。
。
文本CNN分支先将文本序列转为![]() 的字典,n为文本长度,d为词库大小(此时默认为3000000单词),使用word2vec进行过滤,只保留出现的单词。如Flickr30k数据集,过滤后的d为20074。每个出现的单词在词典对应位置设为1,否则为0。作者设置文本长度为32,长度超过32的样本,截取最后的32个单词。通过reshape,转为1x32xd,对应CNN中的height、width、channel。若样本长度小于32,则作者提出了一个position shift的数据增强操作,在开始和结尾随机补零。其CNN结构与图像CNN类似,即:
的字典,n为文本长度,d为词库大小(此时默认为3000000单词),使用word2vec进行过滤,只保留出现的单词。如Flickr30k数据集,过滤后的d为20074。每个出现的单词在词典对应位置设为1,否则为0。作者设置文本长度为32,长度超过32的样本,截取最后的32个单词。通过reshape,转为1x32xd,对应CNN中的height、width、channel。若样本长度小于32,则作者提出了一个position shift的数据增强操作,在开始和结尾随机补零。其CNN结构与图像CNN类似,即:![]() 。
。

Proposed Instance Loss
作者采用了cosine距离来评估两个样本之间的相似度,即:
![]()
![]()
则ranking loss为:
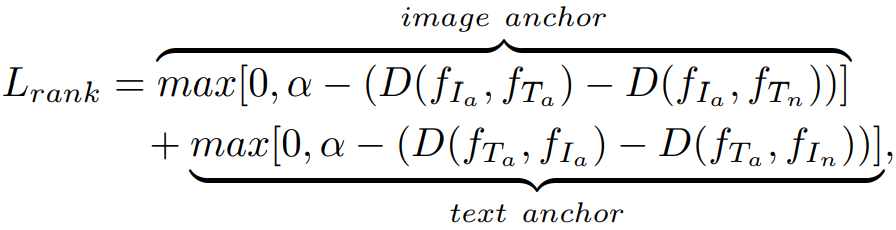
提出的instance loss如下:

个人的理解是:让分类差异更加显著,比如原本的分类概率分布是0.3,0.4,0.3,差异比较小,通过这个损失,概率分布可能会变成0.1,0.8,0.1。作者的可视化也能体现出这个作用:同类相似度更高,不同类相似度更低(下图体现为100对样本之间的相似度度量)。

作者的训练策略是:先用instance loss训练,再采用instance loss和ranking loss联合训练。
Experiment
(1)数据集:
Filickr30k:31783个图像,每个图像对应5段文本,平均10.5个单词长度。其中,1000个图像为测试集,1000个图像为验证集,29783个图像为训练集。
MSCOCO:123287个图像及616767段文本,每个图像对应大约5段文本,平均8.7个单词长度。其中,5000个图像为测试集(分为5组,每组1000个图像),5000个图像为验证集,113287个图像为训练集。
CUHK-PEDES:40206个图像,13003个行人,80440段文本,每个行人对应3.1张图像,每张图像对应2段文本,平均19.6个单词长度。其中,测试集包含3074张图像及6156段文本,验证集包含3078张图像,6158段文本,训练集包含34054张图像及68126段文本。

(2)实验细节:
优化器采用SGD,momentum为0.9,图像reshape为224x224,采用了随机翻转、随机裁剪的操作。CNN中dropout rate为0.75,Flickr30k和MSCOCO的最长文本设置为32,CUHK-PEDES的最长文本设置为56。学习率为0.001。测试阶段采用翻转和非翻转图像的平均特征作为评估依据。
(3)实验结果:
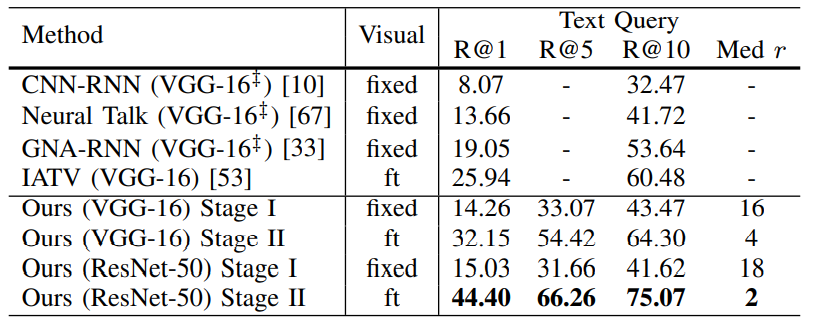
Filickr30k结果:
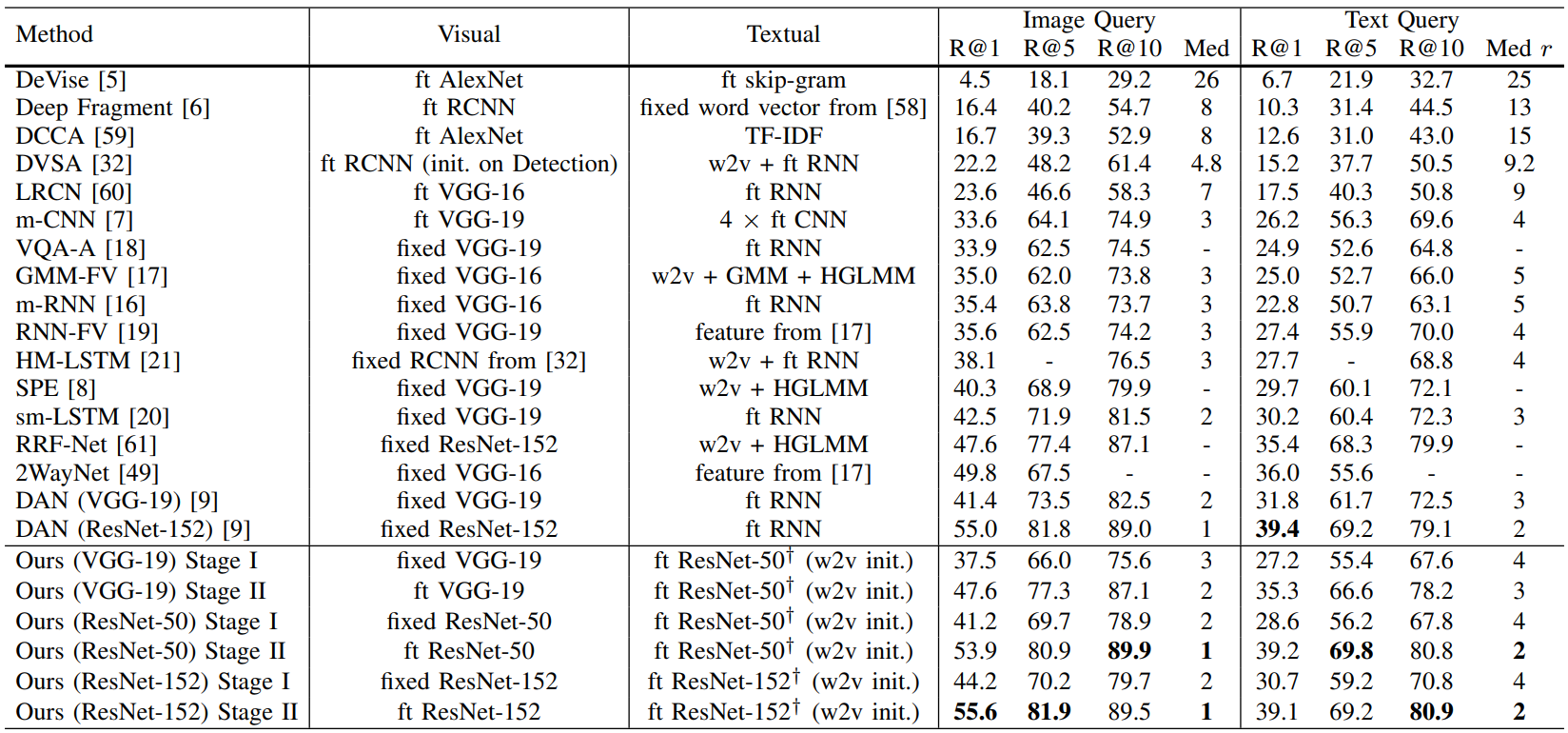
MSCOCO结果:

CUHK-PEDES结果: