Image Super-Resolution Using Dense Skip Connections【ICCV2017】
采用更深层的神经网络能够提取更丰富的纹理细节,同时也会带来训练上的困难。残差连接(skip connection)有3方面的优势:可以为低高阶信息的传递提供捷径,使得网络结构的训练更加容易;低阶网络能够为高阶提供补充高频的信息;重复利用低阶的特征映射可以降低特征的冗余,训练到的CNN更加稳定。受到残差连接的启发,作者提出了SRDenseNet。网络结构如下图所示:
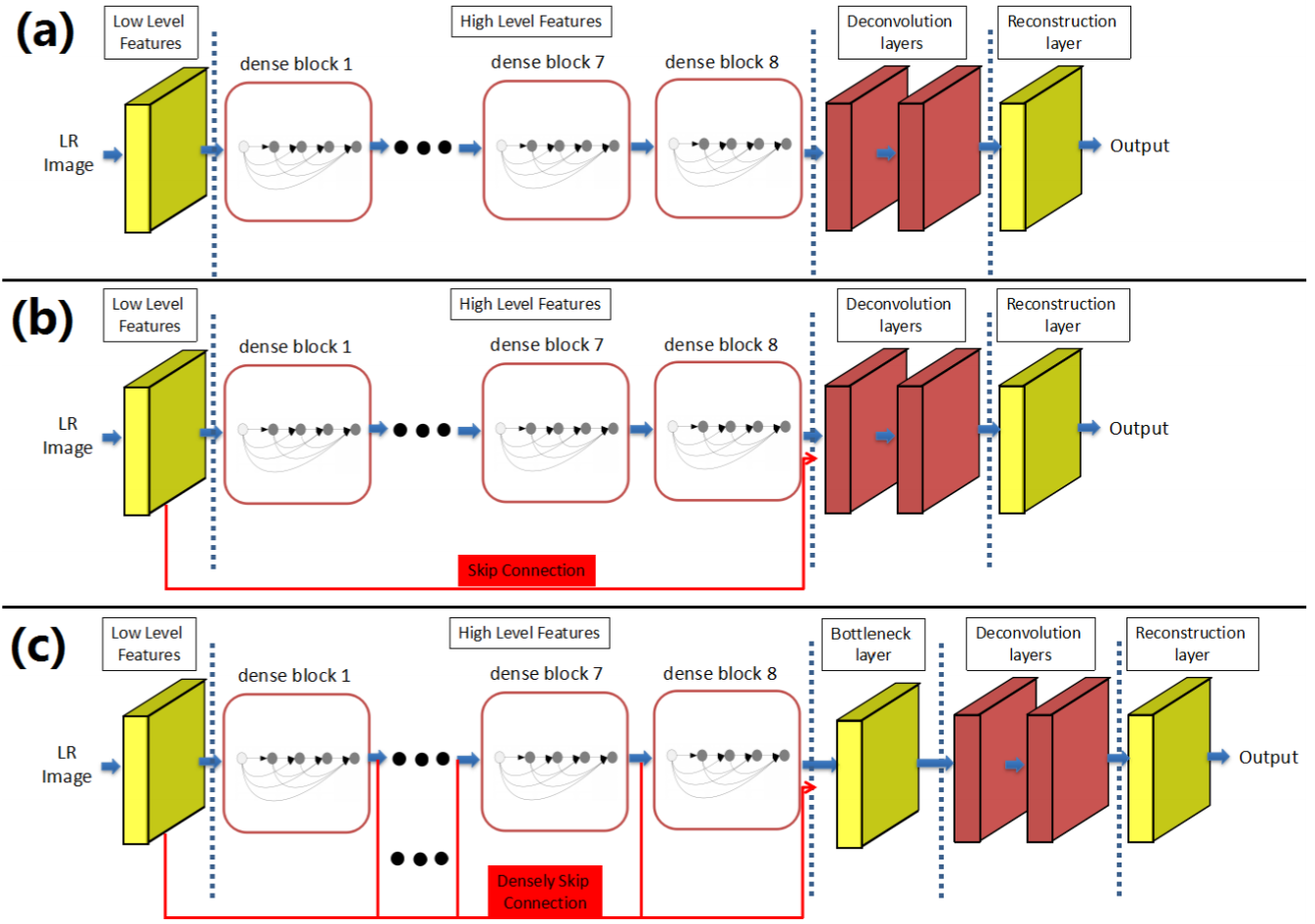
SRDenseNet包含以下模块:卷积模块(学习低阶特征)、DenseNet块(学习高阶特征)、反卷积模块(上采样)、重构模块(生成HR图)
每个卷积/反卷积层都紧接着ReLU激活函数,上一层的特征映射为![]() ,则卷积/反卷积可以表示为:
,则卷积/反卷积可以表示为:
![]()
定义网络的参数为![]()
![]() 。定义输入的LR图像为
。定义输入的LR图像为![]() ,HR图像为
,HR图像为![]() ,训练的图像对为
,训练的图像对为![]() 。
。
需要训练的MSE损失为:
![]()
DenseNet的细节:结构如下图所示,DenseNet有残差的思想,但并不是直接把低高阶特征相加,第 i 层的特征映射接收所有之前层的级联特征,即:
![]()
每个DenseNet块包含了8个卷积层,如果每个卷积层输出的是k层特征映射,那么DenseNet块生成的为8k层特征映射,其中k为生长率(growth rate),本文中定义k=16。
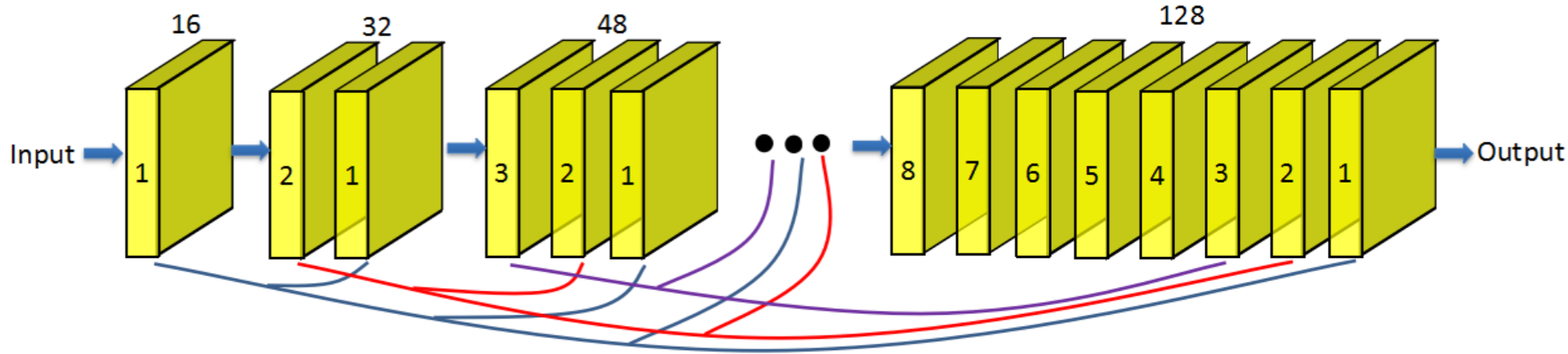
反卷积层的细节:之前的SR方法很多用了bicubic interpolation(双三次插值)来upscale,存在计算复杂的问题。因此本文采用反卷积层来实现upscale,有如下优点:降低计算量;感受野更大。本文采用的反卷积层kernel为3x3,特征映射为256层。
作者提出了3个变体,(a)只采用了最后DenseNet块输出的特征映射,(b)采用了前后两端输出的特征映射,(c)采用了所有DenseNet块输出的特征映射,并用Bottleneck(1x1卷积核)降低特征映射的维度。最终重构模块采用了3x3卷积核,转为单通道的HR图像(疑问:为什么不是3通道?)。
Residual Attribute Attention Network for Face Image Super-Resolution【AAAI2019】
针对人脸低分辨率问题,提出了一个端到端的Residual Attribute Attention Network (RAAN),结合了人脸的纹理特征、形状特征、语义特征(前两个为基础特征,语义特征用于引导前两种特征的整合)。网络包含三部分:Shape Generation Network (SGN)、Texture Prediction Network (TPN)、Attribute Analysis Network (AAN)。结构如下图所示:
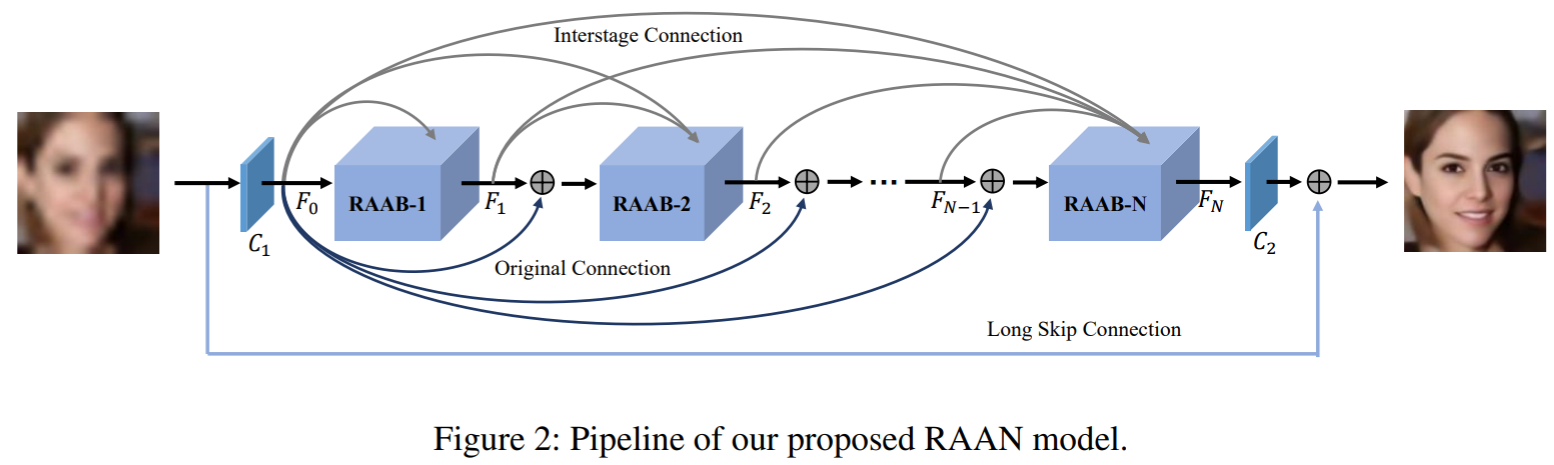
首先提取LR图像的特征映射,即:![]() ,其中 C1 为投影函数,由若干卷积层组成。随后将特征映射输入到若干个Residual Attribute Attention Block (RAAB) 中,每一个block计算为:
,其中 C1 为投影函数,由若干卷积层组成。随后将特征映射输入到若干个Residual Attribute Attention Block (RAAB) 中,每一个block计算为:![]() ,其输入有两部分:① 上一个block的输出(根据图上含义,这里的输出应用了残差的思想,还要另外结合F0),② 前面所有block输出的级联。最终的输出也采用残差的形式:
,其输入有两部分:① 上一个block的输出(根据图上含义,这里的输出应用了残差的思想,还要另外结合F0),② 前面所有block输出的级联。最终的输出也采用残差的形式:![]() 。损失函数如下:
。损失函数如下:
![]()
其中 M 是图片数量,![]() 为真实的HR图像,
为真实的HR图像,![]() 为真实HR图像生成的属性编码。
为真实HR图像生成的属性编码。
RAAB的详细结构如下图:

SGN模块中:相比于HR图像,LR图像更方便提取形状特征(我就这么理解了:HR图像中纹理太多,LR降低了纹理的影响)。作者采用了encoder、decoder,先将图像下采样再编码,然后用decoder恢复成原始尺寸,中间采用了跳层连接。
TPN模块中:针对纹理的特征,需要更大的感受野,因此作者结合了残差思想和空洞卷积。结构为:3x3卷积 --- 空洞卷积 --- 3x3卷积 --- 空洞卷积 --- 3x3卷积。
AAN模块中:先对特征映射进行属性编码,再通过全连接模块提取到纹理和形状特征的注意力。(这里不怎么明白,这里编码能提取出什么属性呢?)
最终采用生成判别网络的思想,引入一个判别器来判断生成的HR图像是true还是fake。
Exploring Factors for Improving Low Resolution Face Recognition【CVPR2019】
本文主要研究了能够改善低分辨率人脸识别的因素。
人脸方面看的少,原文读的一知半解。直接贴论文得出的结论:
(1)采用额外数据集VGGFace2微调能一定程度上提高准确率,原因是VGGFace2包含了20%低于50像素的图像;
(2)人脸图像如果能够框的更完整,即包含更多信息量,则也能很大程度上提高准确率;
(3)下采样HR的Gallery图像,让图像的分辨率尽量匹配,也能提高准确率。