Introduction
(1)Motivation:
在匹配过程中,存在行人的不同图片语义信息不对齐、局部遮挡等现象,如下图:

(2)Contribution:
① 提出了Spindle Net,包含了多阶段ROI池化框架用于提取不同部位的特征,再通过特征融合网络对不同部位的特征进行融合;
② 设计了SenseReID数据集。
Body Region Proposal Network(RPN)
RPN用于提取行人的区域,分为七个部分:肩膀上、上半身、下半身、左右手、左右脚,如下图所示:
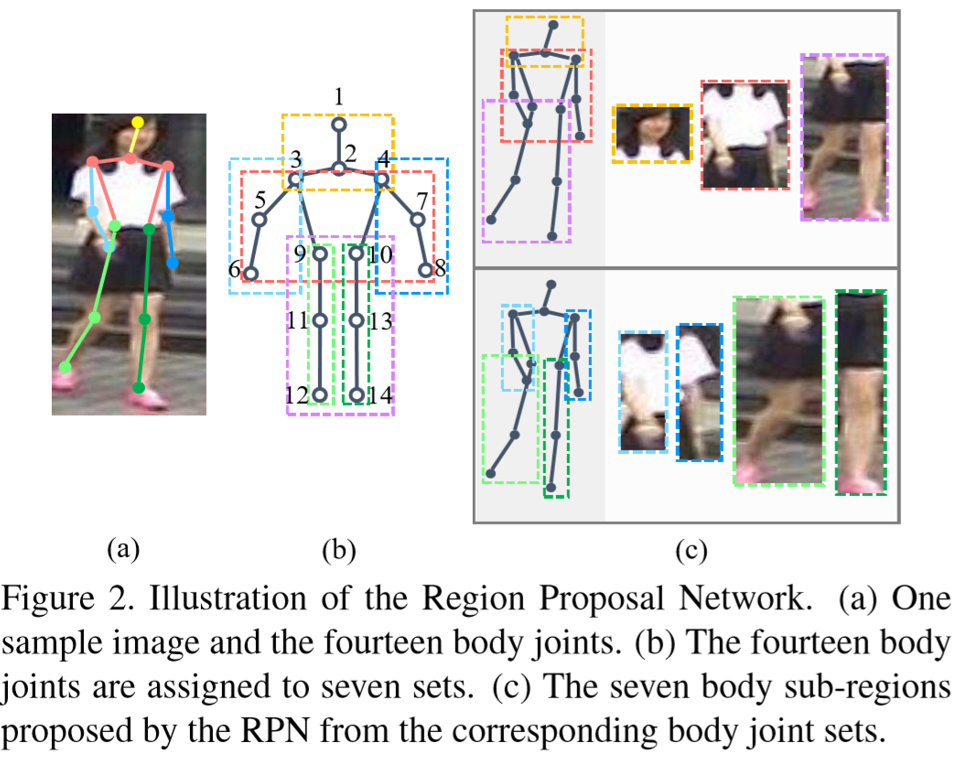
通过CNN提取得到行人的14个特征映射,每个映射包含了一个关键点响应图,即![]() ,其中 X 和 Y 为特征映射的尺寸。特征映射的生成采用了Convolutional Pose Machines(CPM)。然而CPM的计算成本较高,作者对此做出了网络的简化,最终得到14个关键点坐标,即:
,其中 X 和 Y 为特征映射的尺寸。特征映射的生成采用了Convolutional Pose Machines(CPM)。然而CPM的计算成本较高,作者对此做出了网络的简化,最终得到14个关键点坐标,即:![]()
由此7个分区的检测框:![]() ,对应7个关键点集合:
,对应7个关键点集合:![]() 。RPN的训练采用MPII人体姿态数据集,损失函数采用预测响应图和实际响应图的欧式距离。
。RPN的训练采用MPII人体姿态数据集,损失函数采用预测响应图和实际响应图的欧式距离。
Body Region Guided Spindle Net
(1)概述:

网络包含了两个部分:Feature Extraction Network(FEN)和Feature Fusion Network(FFN),如上图所示。FEN的输入为行人图片和区域信息,得到行人的全局特征和七个局部特征,最后通过FFN进行特征融合。
(2)Feature Extraction Network(FEN):
1个全局特征和7个局部特征均通过池化后得到256维的特征向量。FEN包含了3个卷积模块和2个ROI池化模块。FEN-C1的输入为压缩到96*96的图片,![]() 的空间尺寸为24*24,
的空间尺寸为24*24,![]() 通过了ROI池化,得到空间尺寸也为24*24的映射。同理,第二层、第三层的空间尺寸分别为12*12、6*6,最后通过全局平均池化和内积层,压缩到通道上,为256维特征向量。
通过了ROI池化,得到空间尺寸也为24*24的映射。同理,第二层、第三层的空间尺寸分别为12*12、6*6,最后通过全局平均池化和内积层,压缩到通道上,为256维特征向量。
(3)Feature Fusion Network(FFN):
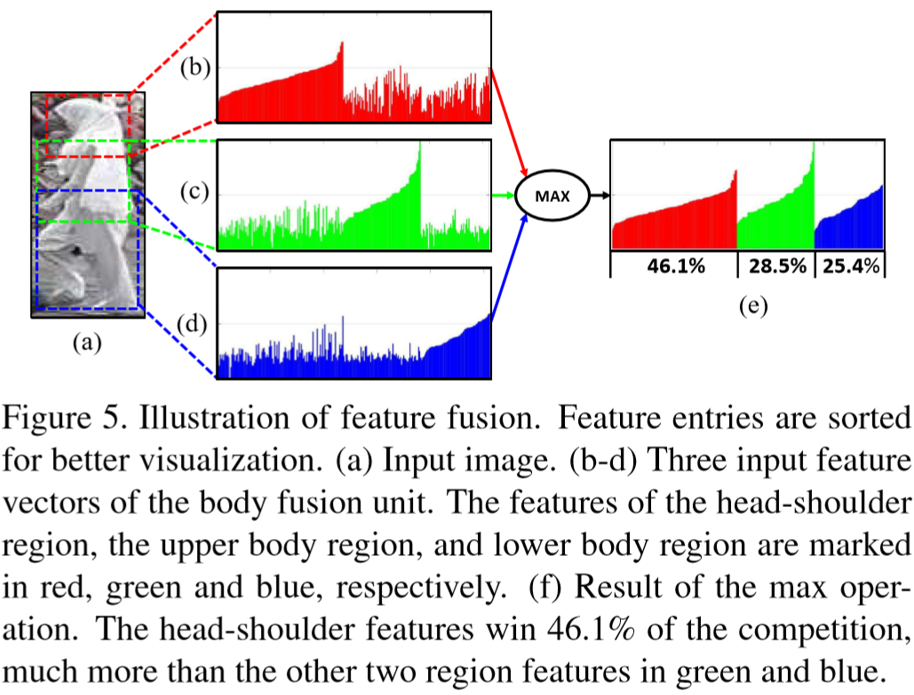
特征融合单元包含两个步骤:① 特征的计算和选择,采用元素最大策略(理解是三个区域的特征向量每个元素都选值最大的那个,如下图所示);② 特征的转换,采用内积计算(理解是对全局、区域特征融合时候采用了内积,将两个256维向量融合为一个256维向量)。
(4)训练细节
训练包含4步:全局特征训练;固定FEN-C1,训练三分支网络;固定FEN-C1和FEN-C2,训练下方四分支网络;训练FFN。
Experiments
(1)数据集设置:
CUHK03、CUHK01、PRID、VIPeR、3DPeS、i-LIDS、Market-1501、CUHK02(只训练)、PSDB(只训练)、SenseReID(只评估)
(2)实验结果:

