Introduction
(1)Motivation:
当前的行人重识别方法都只能在标准的数据集上取得好的效果,但当行人被遮挡或者肢体移动时,往往效果不佳。
(2)Contribution:
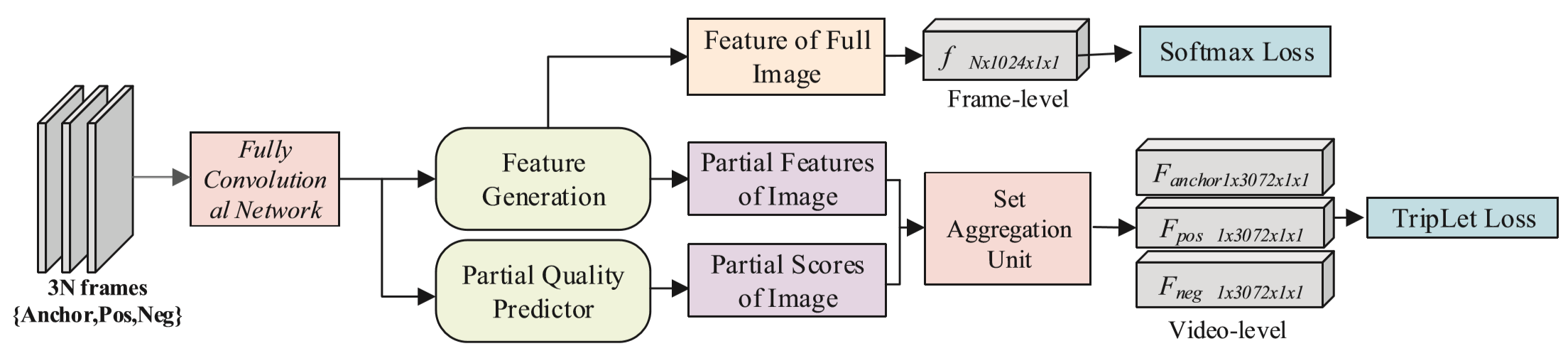
① 提出了一个基于区域的适应性质量估计网络(adaptive region-based quality estimation network,RQEN),包含了区域性特征提取模块和基于区域的质量预测模块。其旨在减小低质量图像区域的影响,利用序列中的区域互补。
② 提供了一个大规模的较整洁的数据集:Labeled Pedestrain in the Wild(LPW),包含了2731个行人,从3个不同场景拍摄,每个行人被2-4个相机捕获,共7694个tracklet、590000帧。该数据集囊括了孩童到老人、步行和快跑等不同的场景。
Proposed Method
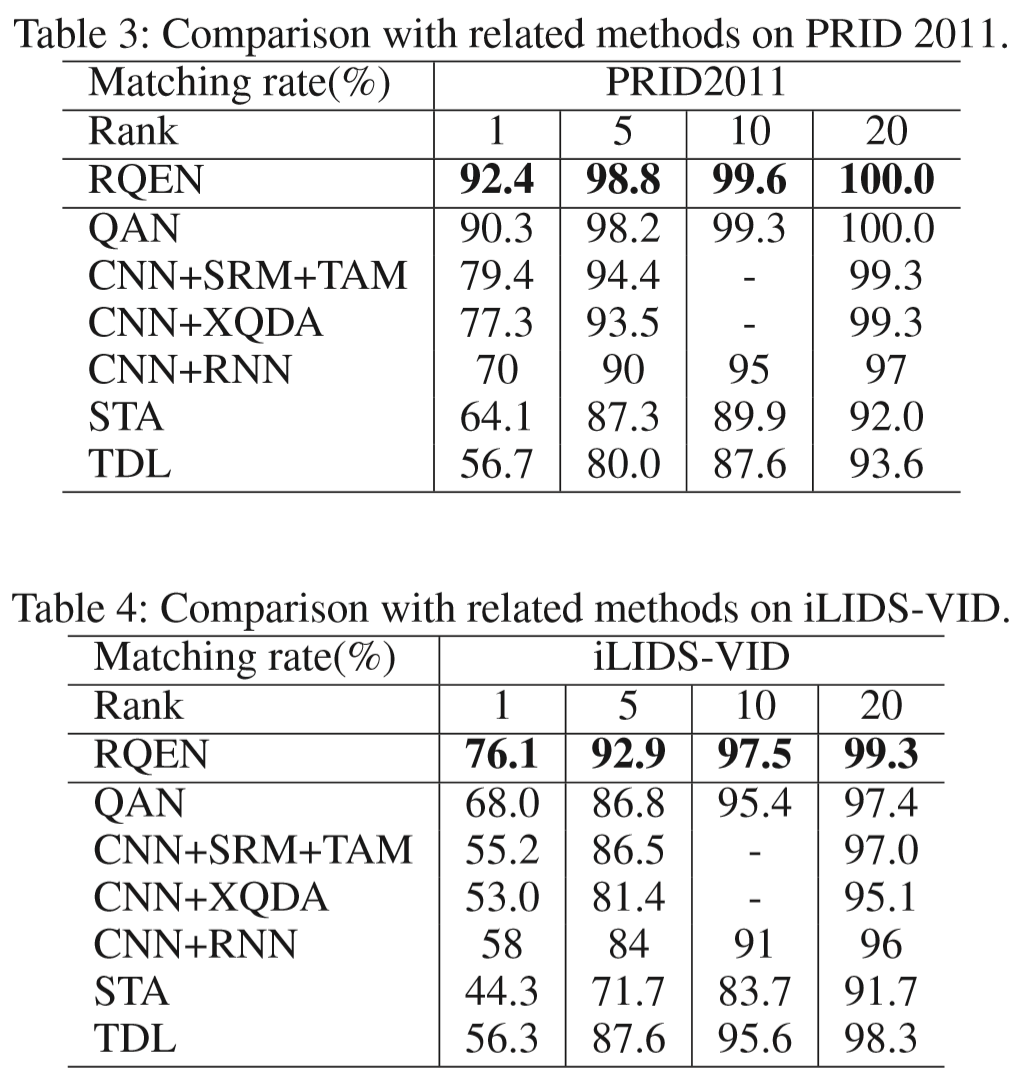
输入:一个行人的图像序列 S = {I1, I2, ..., In}
区域特征提取模块:landmark detector标记行人身体的关键点 [Wei 2016. Convolutional pose machines.CVPR],middle representation按照关键点位置进行划分,然而由于分辨率低的原因,划分常常不够精确。采用的方法:按照关键点分布,将人体大致分为三个部分,定义 u、m、l 为上部、中部、下部区域,分别生成特征向量,即 ![]() ,并进行平均池化。
,并进行平均池化。
质量预测模块:对区域特征生成质量估计![]() 。
。
最终生成视频特征表示 Fw(S)。
(1)区域生成策略:
令 Pi = {p1, p2, ..., pm} 为图像 Ii 的坐标(landmark)集合,m 为坐标点的数量(作者设置 m = 14),如图:

由于低分辨率和遮挡等影响,很多情况下坐标点很难被确定。
采用 k-means 聚类方法对三个集合进行聚类,聚类的设定为:S1P = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10],S2P = [9, 10, 11, 12],S3P = [11, 12, 13, 14].
(2)区域质量预测:
middle representation 输入到卷积网络中,该网络包含卷积层和全连接层,输出的 orignial score μori(Ii) 对应了图片不同的区域,再通过sigmoid函数求出各区域的[0, 1]得分,视频序列不同帧中属于同一区域的得分进行正则化,得到最终结果。
(3)设置聚合单元:
一个图像集合 S = {I1, I2, ..., In},对于每帧图片,有不同的区域表征:![]() ,区域对应的质量评估得分为:
,区域对应的质量评估得分为:![]() ,则生成的特征为:
,则生成的特征为:![]()
![]() ,其中:
,其中:
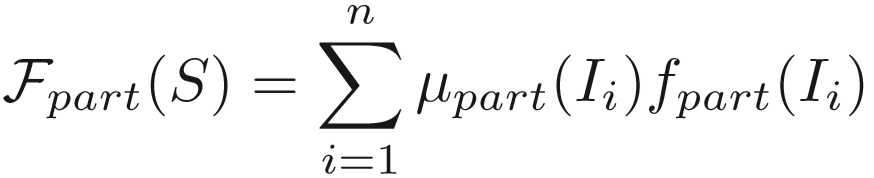
(4)联合训练帧级特征和视频级特征:
训练帧级特征是为了让同一视频内部更紧凑,训练视频级特征是为了让不同视频间更有区分度。

损失函数:![]()
其中三元组损失函数为:
![]()
距离采用 L2-norm 距离。
在区域质量估计部分,T表示输入的数据,输出的 orignial score μori(Ii) 为:
![]()
再进行正则化:
![]()
![]()
Experiments
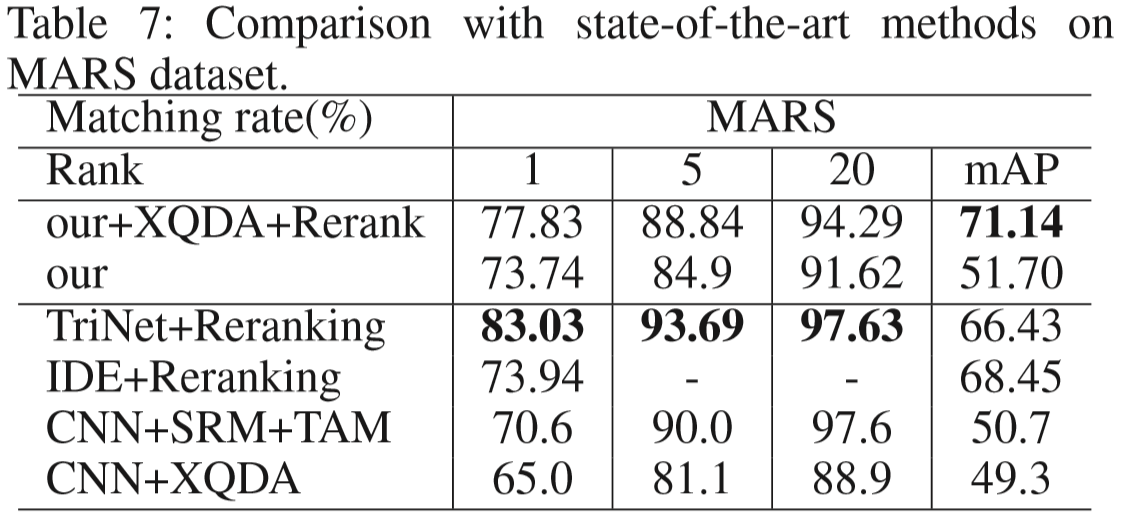
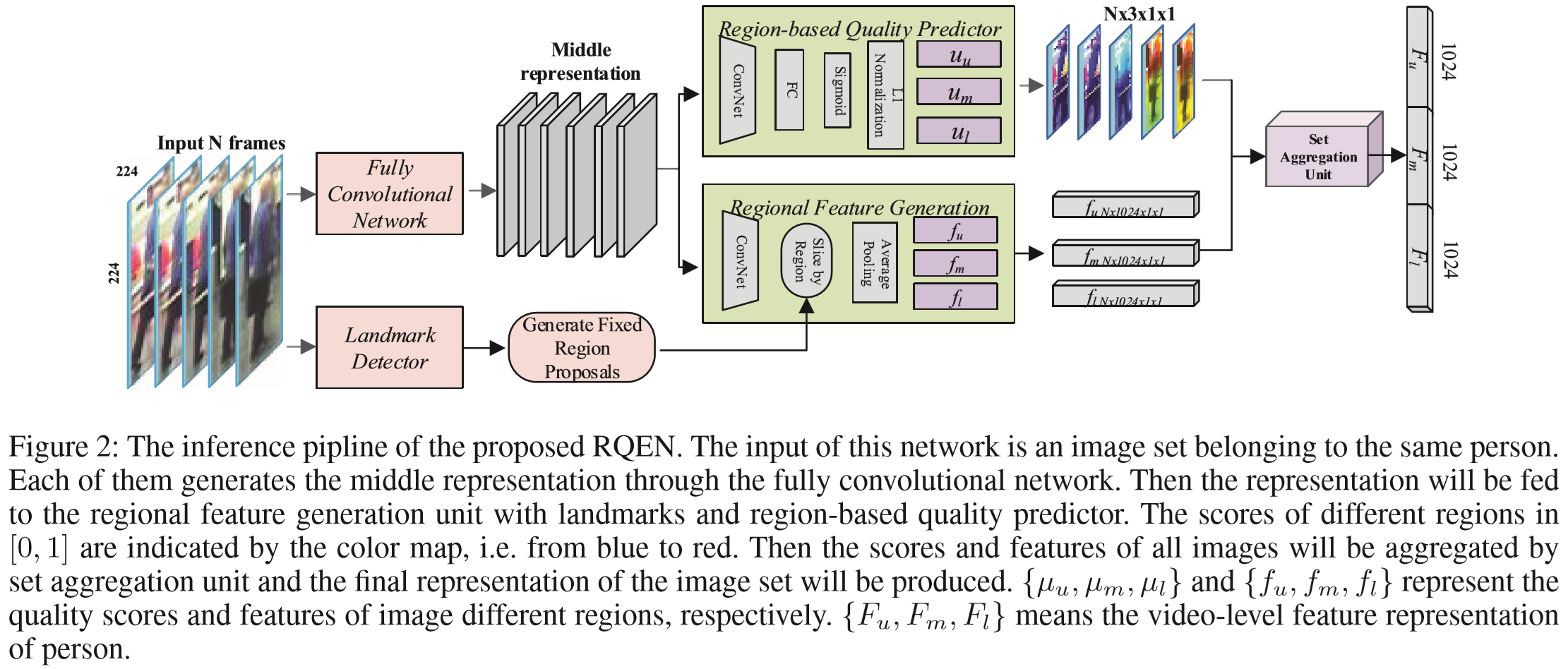
(1)数据集:PRID2011、iLIDS-VID、MARS、LPW
(2)实验结果:
(1)本方法分析:

method(a):GoogLeNet+batch norm(用ImageNet model初始化)[baseline]
method(b)(c)(d):+RU、+RM、+RL表示不同的区域特征
method(e):+QFix表示质量生成单元中设置所有质量得分为1,即消除质量得分的影响
method(f):+MP表示控制参数数量不变(作者提到在RQEN方法中参数会变多?这是为什么?)
(2)对比方法分析: